
梯度下降法原理與模擬分析||系列(1)
阿新 • • 發佈:2020-12-10
## 1 引言
梯度下降法(Gradient Descent)也稱為最速下降法(Steepest Descent),是法國數學家奧古斯丁·路易·柯西 (Augustin Louis Cauchy) 於1847年提出來,它是最優化方法中最經典和最簡單的一階方法之一。梯度下降法由於其較低的複雜度和簡單的操作而在很多領域得到廣泛研究和應用,如機器學習。由梯度下降法衍生了許多其他演算法,如次梯度下降法,近端梯度下降法,隨機梯度下降法,回溯梯度發,動量加速梯度法等等。本文只介紹最基礎的梯度下降法原理和理論分析,與此同時,通過模擬來說明梯度下降法的優勢和缺陷。其他重要的梯度下降衍生方法會持續更新,敬請關注。
## 2 梯度下降法原理
### 2.1 偏導數,方向導數和梯度
在直角座標系下,標量函式 $f:\mathbb{R}^{n}\mapsto \mathbb{R}$ 的梯度 $\nabla f$ 定義為:
$$\nabla f = \frac{{\partial f}}{{\partial x}}{\bf{i}} + \frac{{\partial f}}{{\partial y}}{\bf{j}} + \frac{{\partial f}}{{\partial z}}{\bf{k}}$$
其中 $\bf{i}$,$\bf{j}$,$\bf{k}$ 表示在三個維度的單位方向向量。$\frac{{\partial f}}{{\partial x}}$,$\frac{{\partial f}}{{\partial y}}$,$\frac{{\partial f}}{{\partial z}}$ 為對應的偏導數。
- 方向導數:函式在某點處有無數條切線,沿著這些方向的斜率組成了方向導數,每一條切線都代表一個變化的方向。
- 偏導數:函式在一個點處有無數個導數,而延著座標軸方向對應的導數叫偏導數。
- 梯度:是一個向量,它是的方向是最大方向導數所對應的方向。
梯度下降法就是以梯度為搜尋方向的迭代優化演算法
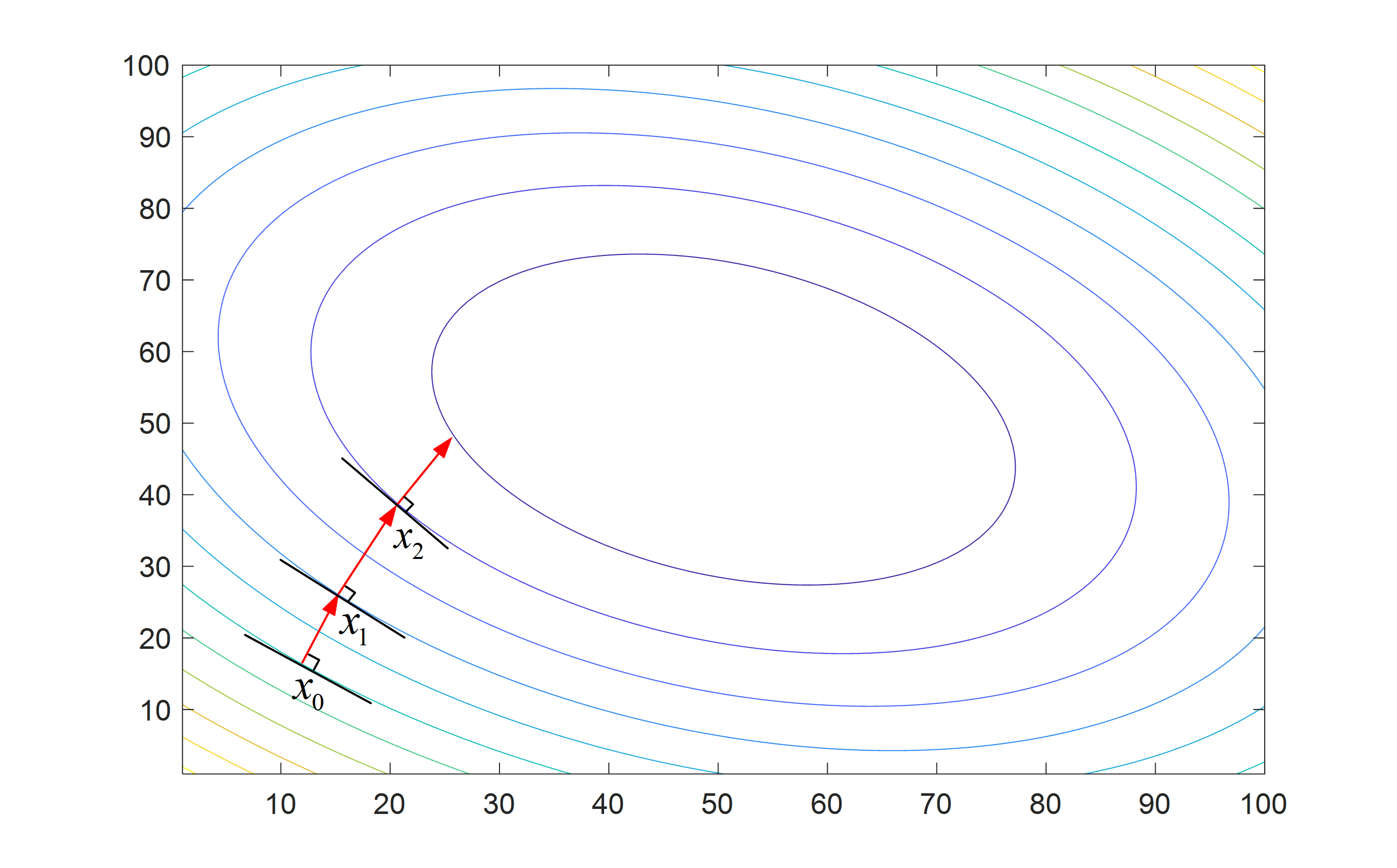
圖2. 梯度下降法迭代過程

圖1. 複雜函式影象 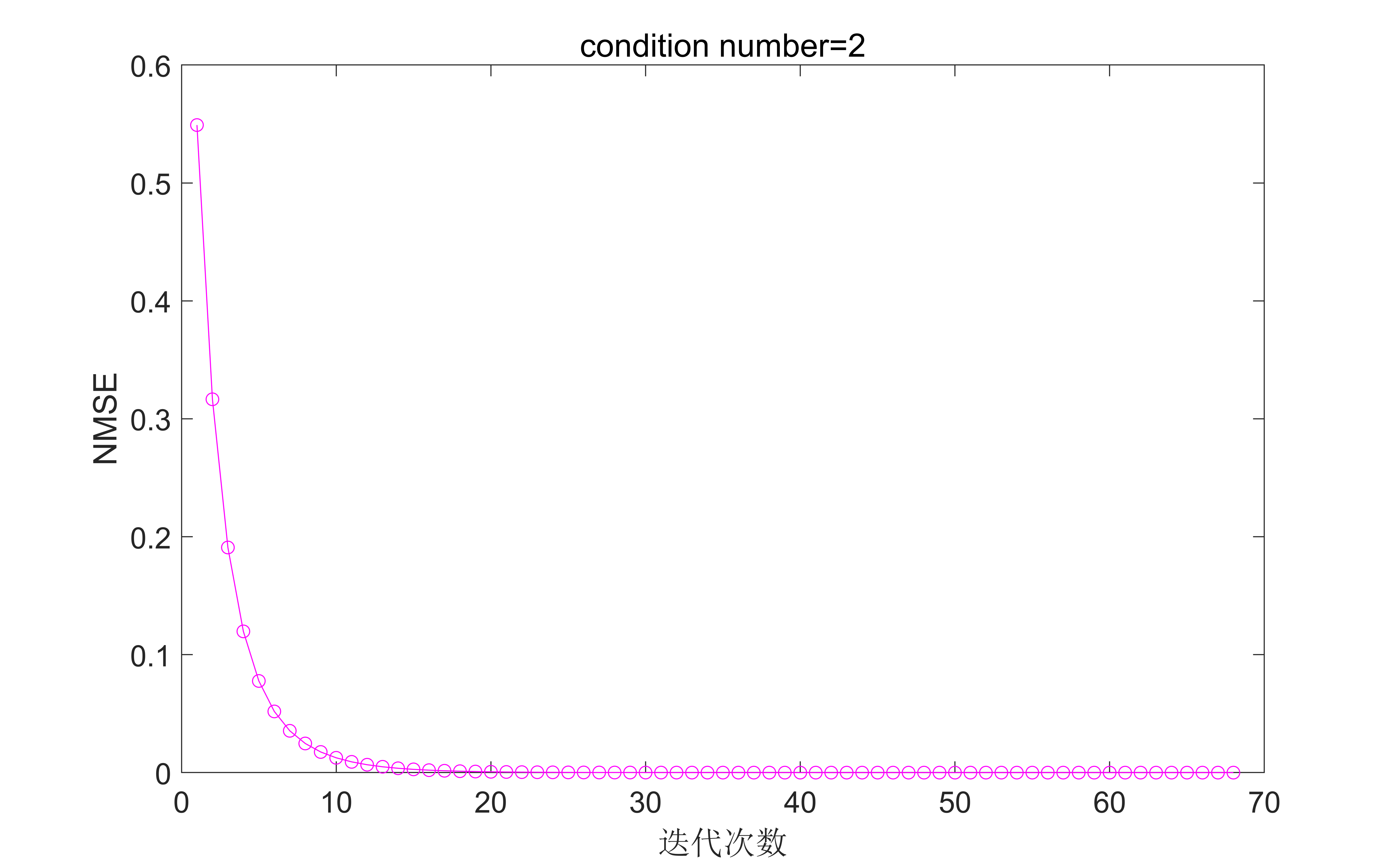
圖3. 固定步長為0.5條件數為2時的結果
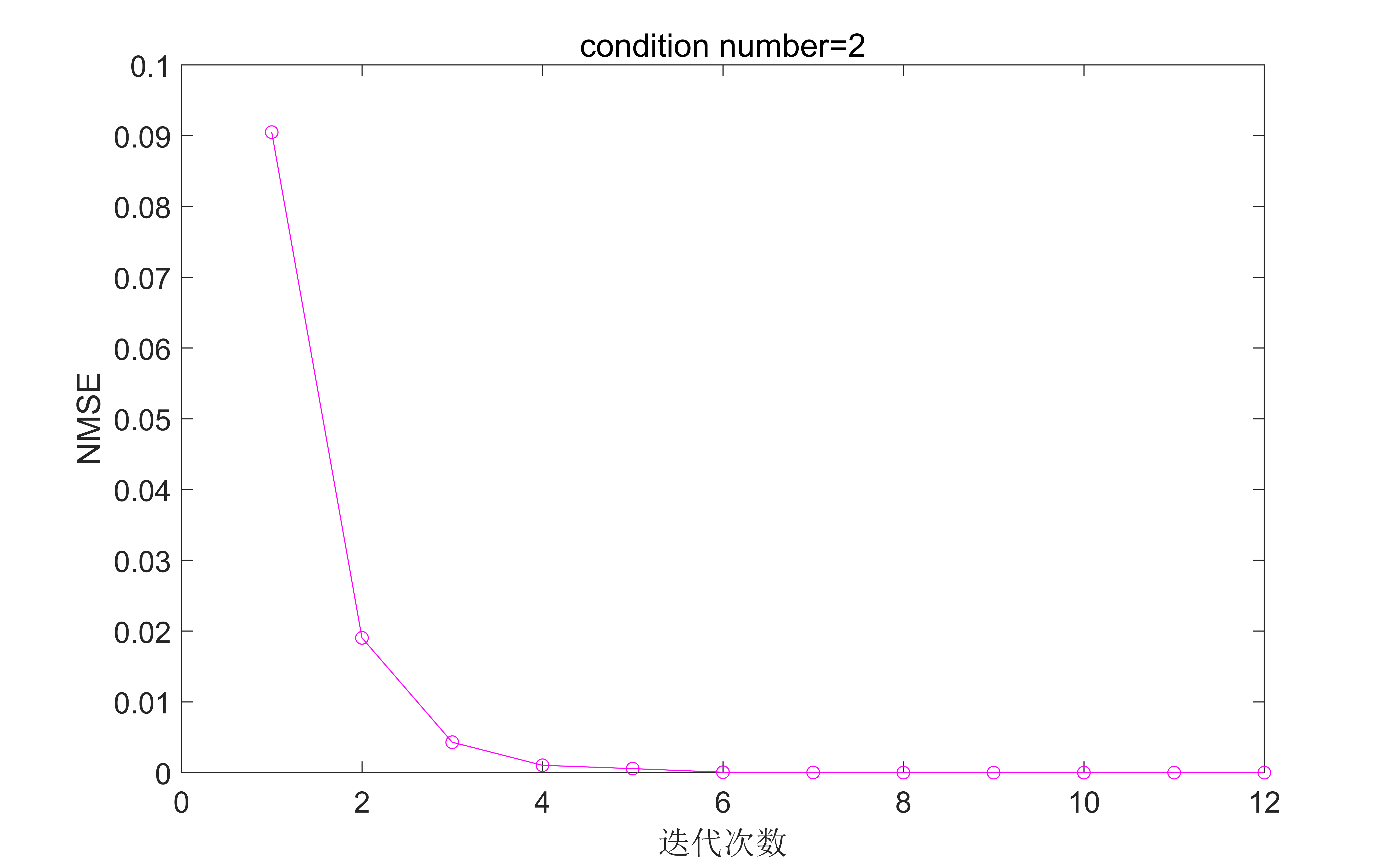
圖4. 最優步長,條件數為2時的結果
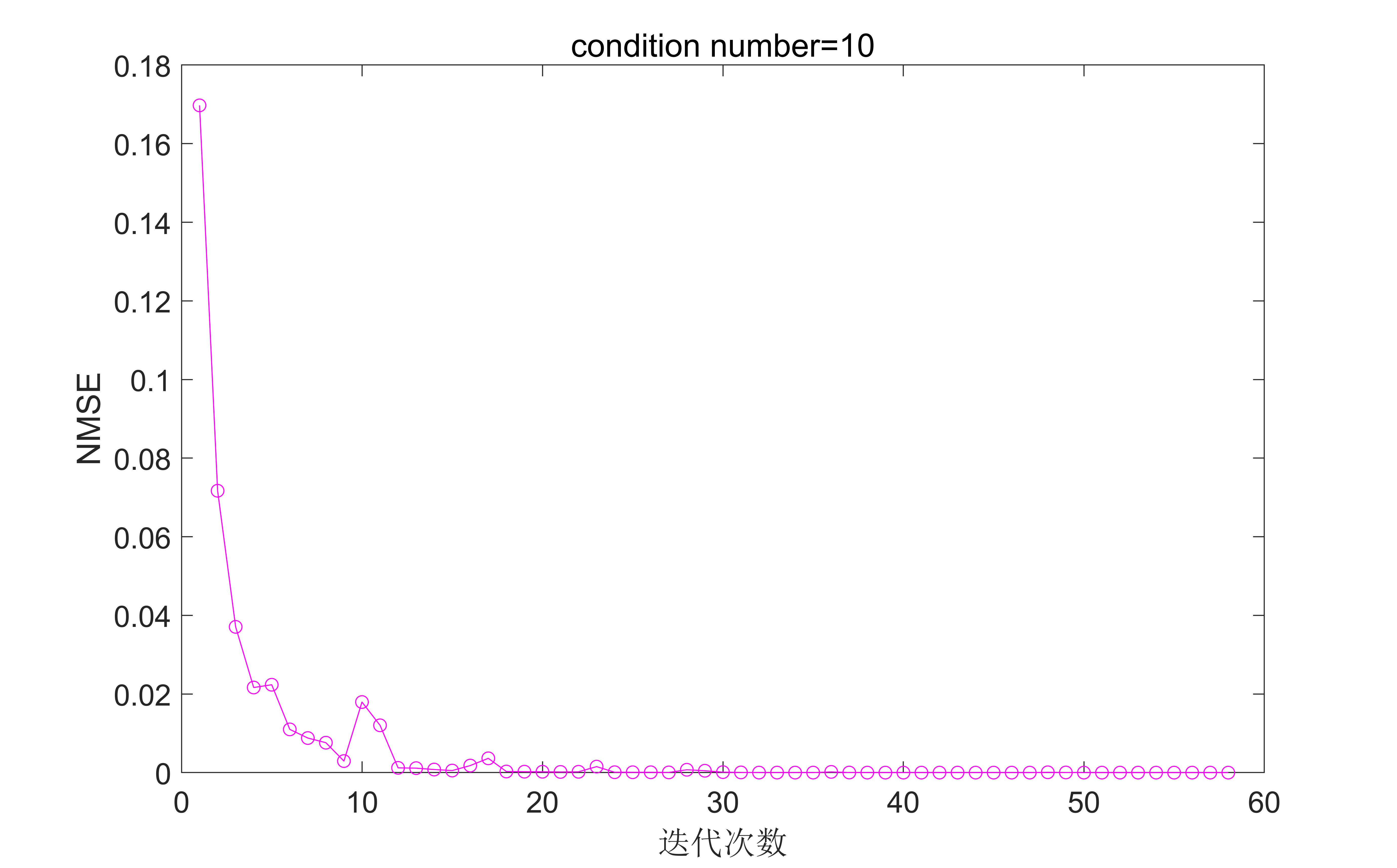
圖5. 最優步長,條件數為10時的結果
