
機器學習避坑指南:訓練集/測試集分佈一致性檢查
阿新 • • 發佈:2020-12-24
工業界有一個大家公認的看法,“資料和特徵決定了機器學習專案的上限,而演算法只是儘可能地逼近這個上限”。在實戰中,特徵工程幾乎需要一半以上的時間,是很重要的一個部分。缺失值處理、異常值處理、資料標準化、不平衡等問題大家應該都已經手到擒來小菜一碟了,本文我們探討一個很容易被忽視的坑:資料一致性。

**眾所周知**,大部分機器學習演算法都有一個前提假設:訓練資料樣本和位置的測試樣本來自同一分佈。如果測試資料的分佈跟訓練資料不一致,那麼就會影響模型的效果。

在一些機器學習相關的競賽中,給定的訓練集和測試集中的部分特徵本身很有可能就存在分佈不一致的問題。實際應用中,隨著業務的發展,訓練樣本分佈也會發生變化,最終導致模型泛化能力不足。
下面就向大家介紹幾個檢查訓練集和測試集特徵分佈一致性的方法:
## KDE(核密度估計)分佈圖
核密度估計(kernel density estimation)是在概率論中用來估計未知的密度函式,屬於非引數檢驗方法之一,通過核密度估計圖可以比較直觀的看出資料樣本本身的分佈特徵。
seaborn中的kdeplot可用於對單變數和雙變數進行核密度估計並可視化。
看一個小例子:
```
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
train_set=pd.read_csv(r'D:\...\train_set.csv')
test_set=pd.read_csv(r'D:\...\test_set.csv')
plt.figure(figsize=(12,9))
ax1 = sns.kdeplot(train_set.balance,label='train_set')
ax2 = sns.kdeplot(test_set.balance,label='test_set')
```
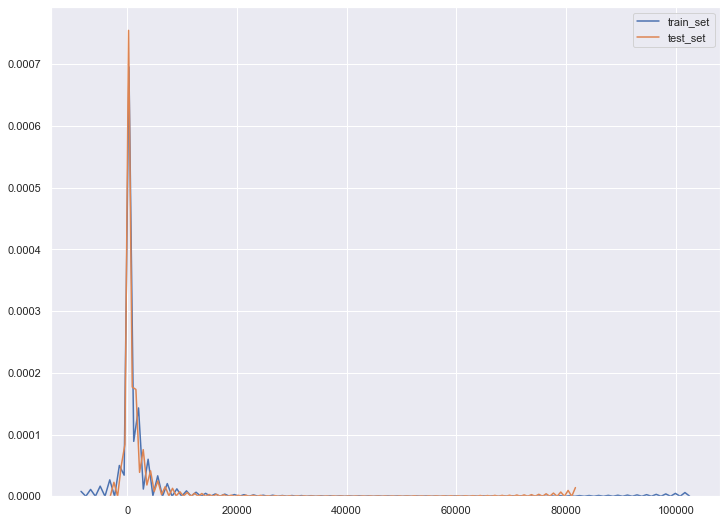
## KS檢驗(Kolmogorov-Smirnov)
KS檢驗是基於累計分佈函式,用於檢驗一個分佈是否符合某種理論分佈或比較兩個經驗分佈是否有顯著差異。兩樣本K-S檢驗由於對兩樣本的經驗分佈函式的位置和形狀引數的差異都敏感,所以成為比較兩樣本的最有用且最常用的非引數方法之一。
我們可以使用 scipy.stats 庫中的ks_2samp,進行KS檢驗:
```
from scipy.stats import ks_2samp
ks_2samp(train_set.balance,test_set.balance)
```
ks檢驗一般返回兩個值:第一個值表示兩個分佈之間的最大距離,值越小即這兩個分佈的差距越小,分佈也就越一致。第二個值是p值,用來判定假設檢驗結果的一個引數,p值越大,越不能拒絕原假設(待檢驗的兩個分散式同分布),即兩個分佈越是同分布。
```
Ks_2sampResult(statistic=0.005976590587342234, pvalue=0.9489915858135447)
```
最終返回的結果可以看出,balance這個特徵在訓練集測試集中服從相同分佈。
## 對抗驗證(Adversarial validation)
除了 KDE 和 KS檢驗,目前比較流行的是對抗驗證,它並不是一種評估模型效果的方法,而是一種用來確認訓練集和測試集的分佈是否變化的方法。
具體做法:
1、將訓練集、測試集合併成一個數據集,新增一個標籤列,訓練集的樣本標記為 0 ,測試集的樣本標記為 1 。
2、重新劃分一個新的train_set和test_set(區別於原本的訓練集和測試集)。
3、用train_set訓練一個二分類模型,可以使用 LR、RF、XGBoost、 LightGBM等等,以AUC作為模型指標。
4、如果AUC在0.5左右,說明模型無法區分原訓練集和測試集,也即兩者分佈一致。如果AUC比較大,說明原訓練集和測試集差異較大,分佈不一致。
5、利用第 2 步中的分類器模型,對原始的訓練集進行打分預測,並將樣本按照模型分從大到小排序,模型分越大,說明與測試集越接近,那麼取訓練集中的 TOP N 的樣本作為目標任務的驗證集,這樣即可將原始的樣本進行拆分得到訓練集,驗證集,測試集。
除了確定訓練集和測試集特徵分佈一致性,對抗驗證還可以用來做特徵選擇。大家感興趣的話可以給個贊+在看,下一講《特徵選擇》,我們用例項來看看對抗驗證的具體用法和