
30分鐘帶你理解 Raft 演算法
阿新 • • 發佈:2021-01-25
- [為什麼需要 Raft?](#為什麼需要-raft)
- [Raft 是什麼?](#raft-是什麼)
- [Raft 的目標](#raft-的目標)
- [前置條件:複製狀態機](#前置條件複製狀態機)
- [Raft 基礎](#raft-基礎)
- [Leader 選舉(選舉安全特性)](#leader-選舉選舉安全特性)
- [日誌複製(Leader只附加、日誌匹配)](#日誌複製leader只附加日誌匹配)
- [安全](#安全)
- [學習資料](#學習資料)
- [使用 Raft 的應用?](#使用-raft-的應用)
- [擴充套件:ZooKeeper ZAB 協議](#擴充套件zookeeper-zab-協議)
- [擴充套件:ZooKeeper 是什麼?](#擴充套件zookeeper-是什麼)
# 為什麼需要 Raft?
* 要提高`系統的容錯率`,需要分散式系統
* 分散式系統有多個例項,對於給定的一組操作,需要協議讓`所有例項達成一致`(分散式一致性)
* Paxos 是分散式一致性協議的標準,但難以理解、實現
* Raft 提供了和 Paxos 演算法相同的功能,但更好理解、構建實際的系統
# Raft 是什麼?
* Replicated And Fault Tolerant,`複製和容錯`
* 管理複製`日誌的一致性演算法`
# Raft 的目標
* 簡單易理解
* 提供完整的實現系統,減少開發者的工作量
* 保證所有條件下都是安全的,在大部分情況下是可用的
* 常用操作是高效的
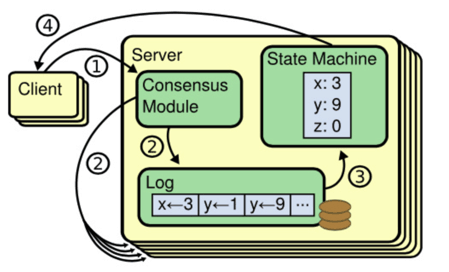
# 前置條件:複製狀態機
* Raft 相當於複製狀態機中的“`一致性模組`”
* 一致性模組(Consensus Module):管理來自客戶端的指令,接入 log
* 日誌(Log)
* 狀態機(State Machine):執行日誌的指令,得到 Server 狀態
# Raft 基礎
* 節點狀態:
* `Leader(領導者)`:系統只有一個節點處是 Leader,處理所有客戶端的請求並同步給 Follower
* `Follower(跟隨者)`:只響應其他伺服器(Leader、Candidate)的請求
* `Candidate(候選者)`:在選舉領導的時候出現
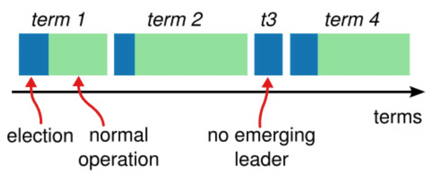
* term(任期):
* 一段選舉的任期(選舉開始+正常工作)
* term 號自動 +1
* 如果選票均分,則該 term 直接結束,進入下一個 term
* Raft 中的`「邏輯時鐘」`,可發現過期資訊,規則:
* 每個節點會儲存當前 term 號,term 編號單調遞增
* 節點間通訊,交換 term 號
* (1)節點當前 term 號 < 他人 term 號,更新 term 號
* (2)節點當前 term 號 > 他人 term 號,拒絕請求
* (3)Candidate、Leader 發現自己的 term < 他人 term,立即變成 Follower
* 節點通訊:使用 `RPC`
* 請求投票(RequestVote) RPCs:選舉階段,Candidate 節點發送給他人
* 附加條目(AppendEntries)RPCs:非選舉階段,Leader 發給所有節點,複製日誌+心跳
* 特性(Raft 保證在任何時候都成立)
* 選舉安全:對一個給定的 term 號,最多選舉出一個 Leader
* Leader 只附加原則:Leader 不會刪除、覆蓋自己的日誌,只會增加
* 日誌匹配:若兩個日誌在相同索引位置的日誌的 term 號相同,則日誌從頭到該索引位置全部相同
* Leader 完整特性:選舉出的 Leader,會包含所有已提交的日誌
* 狀態機安全特性:Leader 已經將給定的索引值位置的日誌條目應用到狀態機,其他任何伺服器都已執行
# Leader 選舉(選舉安全特性)
* Raft 使用心跳機制觸發 Leader 選舉
* 叢集存在 Leader,Leader 節點週期性發心跳包
* 一個 Follower 沒有收到任何訊息(固定區間隨機的時間),發起選舉
* 叢集啟動時,所有節點都處於 Follower 狀態
* 節點到達超時時間後,會進入 Candidate 狀態,增加自己的 term 號,傳送請求投票給自己
* Candidate 狀態機
* 節點得票最多的,變成 Leader
* 收到來自其他節點的“宣告自己是 Leader”的請求
* 一段時間後,沒有獲得多數票,也沒有收到其他節點的 Leader 通知(平分選票)
* 避免選舉的平分選票:隨機選舉超時時間
* 每個節點隨機選擇選舉超時時間,到達時間後成為 Candidate
* 大多數情況下,只有一個節點率先進入 Candidate
# 日誌複製(Leader只附加、日誌匹配)
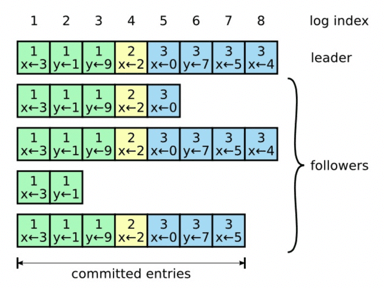
* Leader 會接收客戶端的請求,請求指令作為一個“日誌條目”新增到日誌中
* 向所有 Follower 傳送附加條目 RPC,讓他們複製這個日誌條目
* 得到大多數節點回復後,Leader 會把日誌寫入複製狀態機,持久化,把執行結果返回給客戶端
* 日誌非安全的;進入狀態機中是安全的(已提交),最終會被所有可用的狀態機執行。
index = 7 的日誌已經被大多數節點複製,狀態為已提交。
# 安全
* 選舉限制(Leader 完整性):每次選舉出來的 Leader,必須包含所有已提交的日誌
* 只有已經被大部分節點複製的日誌,才會變成“已提交”
* 一個 Candidate 必須得到大部分節點投票,才能變成 Leader
* 投票時,節點不會把票投給沒有自己的日誌新的 Candidate
* Follower 或 Candidate 崩潰:無限重試
* 超時和可用性:broadcastTime(廣播時間)<< electionTimeout(選舉超時時間)<< MTBF(平均故障間隔時間)
# 學習資料
* 生動形象的網站:http://thesecretlivesofdata.com/raft/
* 論文:https://raft.github.io/raft.pdf
# 使用 Raft 的應用?
* 服務發現框架:consul、`etcd`
* 日誌:`RocketMQ`
* 資料儲存:`Tidb`、`k8s`
# 擴充套件:ZooKeeper ZAB 協議
* 支援崩潰恢復的原子廣播協議:`ZooKeeper Atomic Broadcast protocol`
* ZooKeeper 適合`讀多寫少`的場景,客戶端隨機連到 ZK 叢集的一個節點
* 從當前節點讀
* 寫入到 leader,leader 廣播事務,半數節點成功才會被提交
* `整體流程類似於 Raft`,只是細節和實現的區別
# 擴充套件:ZooKeeper 是什麼?
官方定義: A Distributed Coordination Service for Distributed Applications。本質:`基於記憶體的 KV 系統,以 path 為 key`。
# 程式碼、思維導圖筆記連結
程式碼和思維導圖在 [GitHub 專案](https://github.com/LjyYano/Thinking_in_Java_MindMapping)中,歡迎大家 star!
coding 筆記、點滴記錄,以後的文章也會同步到公眾號(Coding Insight)中,希望大家關注^_^
![](https://img2020.cnblogs.com/other/633265/202101/633265-20210125112924297-263285