
固定學習率梯度下降法的Python實現方案
阿新 • • 發佈:2021-01-31
# 應用場景
優化演算法經常被使用在各種組合優化問題中。我們可以假定待優化的函式物件$f(x)$是一個黑盒,我們可以給這個黑盒輸入一些引數$x_0, x_1, ...$,然後這個黑盒會給我們返回其計算得到的函式值$f(x_0), f(x_1), ...$。我們的最終目的是得到這個黑盒函式的最優輸入引數$x_i$,使得$f(x_i)=min\{f(x)\}$。那麼我們就會想到,通過不斷的調整輸入給黑盒的$x$值,直到找到滿足要求的那個$x$值。
我們需要明確的一個資訊是,我們不可能遍歷這整個的函式空間。雖然這樣能夠使得我們找到真正的最優解,但是遍歷所帶來的時間消耗是一般的專案所無法接受的,因此就需要一些更加聰明的變化方法來對黑盒進行優化。
# 梯度下降法
梯度下降(Gradient Descent)是最早被提出的一種簡單模型,其引數迭代思路較為簡單:
$$
x_{n+1} = x_{n} - \gamma\frac{d}{dx}f(x_n)
$$
或者也可以將其寫成更加容易理解的差分形式:
$$
x_{n+1} = x_{n} - \gamma\frac{f(x_{n+1})-f(x_n)}{x_{n+1}-x_{n}}
$$
其中的$\gamma$我們一般稱之為學習率,在後續的部落格中,會介紹一種自適應學習率的梯度優化方法。學習率會直接影響到優化收斂的速率,如果設定不當,甚至有可能導致優化結果發散。我們在優化的過程中一般採用自洽的方法,使得優化過程中滿足自洽條件後直接退出優化過程,避免多餘的計算量:
$$
\frac{d}{dx}f(x_n)=0
$$
在該條件下實際上我們找到的很有可能是一個區域性最優值,在`minimize`的過程中可以認為是找到了一個極小值或者常見的`鞍點`(如下圖所示)。如果需要跳出極小值,可能需要額外的方法,如隨機梯度下降和模擬退火等。
# 針對梯度下降演算法的改進
實際應用中如果直接使用該梯度下降演算法,會遇到眾多的問題,如:在接近極小值附近時優化過程緩慢,或者由於步長的設定導致一致處於"震盪"的狀態,這裡我們引入兩種梯度下降的優化方案。
## 衰減引數的引入
由於前面提到的梯度下降演算法的學習率$\gamma$是固定的,因此在迭代優化的過程中有可能出現這幾種情況:
1. 由於設定的學習率太小,導致一直出於下降優化過程,但是直到達到了最大迭代次數,也沒能優化到最優值。如下圖所示,正因為學習率設定的太低而導致迭代過程無法收斂。
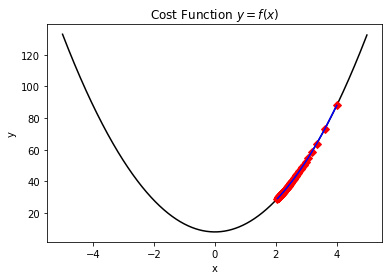
2. 由於設定的學習率太大,導致出現"震盪"現象,同樣無法儘快優化到收斂值。
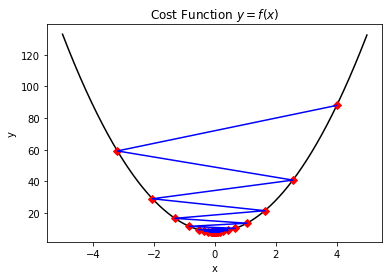
因此,這裡我們可以引入衰減引數的概念,使得梯度下降的過程中,學習率也逐步的在衰減,越靠近收斂值跳動就越緩慢:
$$
x_{n+1} = x_{n} - \frac{\gamma}{n+1}\frac{f(x_{n+1})-f(x_n)}{x_{n+1}-x_{n}}
$$
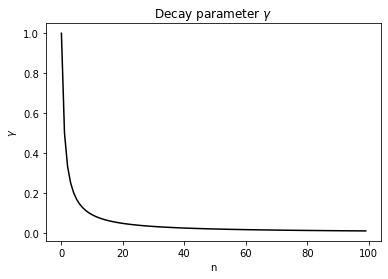
在這種配置下,學習率引數$\gamma$按照如下圖所示的趨勢進行衰減:
```python
import matplotlib.pyplot as plt
x = [i for i in range(100)]
y = [1/(i + 1) for i in range(100)]
plt.figure()
plt.plot(x,y,color='black')
plt.title('Decay parameter $\gamma$')
plt.xlabel('n')
plt.ylabel('$\gamma$')
plt.show()
```
## 衝量引數的引入
在迭代優化的過程中,靠近極小值處的優化效率也是一處難點,也正是因為配置了衰減引數,因此在優化的末尾處會尤其的緩慢(如下圖所示)。為此,我們需要一些提高效率的手段。
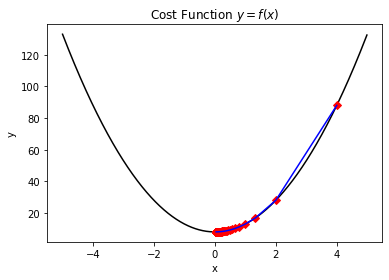
首先我們可以嘗試結合一些物理定律來考慮這個問題,比如衝量定理:
$$
Ft=m\frac{d}{dt}x_1-m\frac{d}{dt}x_0
$$
這個經典力學公式所隱藏的一個規律是:當我們給定一個"迭代衝量"時,本次迭代過程的偏移量$\frac{d}{dt}x_1$的大小跟前面一次的偏移量$\frac{d}{dt}x_0$是有一定的關係的。因此這裡我們也新增一個"衝量"引數,使得如果前一次梯度前進的方向與本次前進方向相同,則多前進一些步長,而如果兩者梯度方向相反,則降低步長以防止"震盪"現象。具體公式變動如下所示:
$$
x_{n+1} = x_{n} - \frac{\gamma}{n+1}\frac{f(x_{n+1})-f(x_n)}{x_{n+1}-x_{n}} + m(x_{n}-x_{n-1})
$$
在給定上述的迭代策略之後,我們可以開始定義一些簡單的問題,並使用該梯度下降的模型去進行優化求解。
# 定義代價函式
這裡我們開始演示梯度下降法的使用方法,為此需要先定義一個代價函式用於黑盒優化,我們可以給定這樣的一個函式:
$$
f(x)=5x^2+8
$$
這個函式所對應的python程式碼實現如下:
```python
import matplotlib.pyplot as plt
def cost_function(x):
return 5 * x ** 2 + 8
plt.figure()
x = [i / 100 - 5 for i in range(1000)]
y = [cost_function(i) for i in x]
plt.plot(x, y, color = 'black')
plt.title('Cost Function $y = f(x)$') # Latex Type Equation.
plt.xlabel('x')
plt.ylabel('y')
plt.show()
```
從上述python程式碼的輸出中,我們可以看到該函式的輪廓結構如下圖所示:
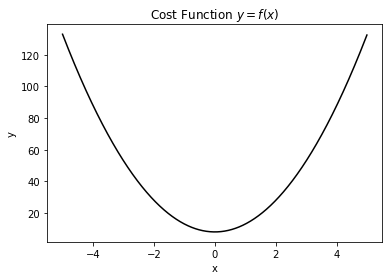
從圖中我們可以獲取大概這些資訊:函式連續可微,存在極小值且為最小值,最小值對應的輸入在0附近。
# 梯度下降法的程式碼實現
根據演算法特性,我們將其分為了`引數定義`、`代價函式定義`、`梯度計算`、`路徑計算`幾個模組,最終再將其整合到`minimize`函式中。此處我們還額外引用了`scipy.optimize.minimize`函式作為一個對比,以及`tqdm`可用於展示計算過程中的進度條,相關使用方法可以參考這篇[部落格](https://www.cnblogs.com/dechinphy/p/progress-bar.html)。
```python
from scipy.optimize import minimize as scipy_minimize
from tqdm import trange
import matplotlib.pyplot as plt
import numpy as np
DELTA = 1e-06
EPSILON = 1e-06
MAX_STEPS = 100
GAMMA = 0.6
MOMENTUM =0.2
def cost_function(x):
return 5 * x ** 2 + 8
def gradient(x, func):
return (func(x + DELTA) - func(x)) / DELTA
def next_x(x, func, iterations, v):
_tmpx = x - GAMMA * gradient(x, func) / (iterations + 1) + MOMENTUM * v
return _tmpx if cost_function(_tmpx) < cost_function(x) and gradient(_tmpx, func) * gradient(x, func) >= 0 else x
def minimize(x0, func):
_x1 = x0
_y1 = func(_x1)
plot_x = [_x1]
plot_y = [_y1]
v = 0
for i in trange(MAX_STEPS):
_x = next_x(_x1, func, i, v)
_y = func(_x)
v = _x - _x1
if v == 0:
continue
if abs(_y - _y1) <= EPSILON:
print ('The minimum value {} founded :)'.format(_y))
print ('The correspond x value is: {}'.format(_x))
print ('The iteration times is: {}'.format(i))
return _y, _x, plot_y, plot_x
_x1 = _x
_y1 = _y
plot_x.append(_x1)
plot_y.append(_y1)
print ('The last value of y is: {}'.format(_y))
print ('The last value of x is: {}'.format(_x))
return _y, _x, plot_y, plot_x
if __name__ == '__main__':
x0 = 4
yt, xt, py, px = minimize(x0, cost_function)
plt.figure()
x = [i / 100 - 5 for i in range(1000)]
y = [cost_function(i) for i in x]
plt.plot(x, y, color = 'black')
plt.plot(px, py, 'D', color = 'red')
print ('The function evaluation times is: {}'.format(len(py)))
plt.plot(px, py, color = 'blue')
plt.title('Cost Function $y = f(x)$') # Latex Type Equation.
plt.xlabel('x')
plt.ylabel('y')
plt.show()
result = scipy_minimize(cost_function, x0, method='BFGS', options={'disp':True})
print ('The scipy method founded x is: {}'.format(result.x))
print ('The correspond cost function value is: {}'.format(cost_function(result.x)))
```
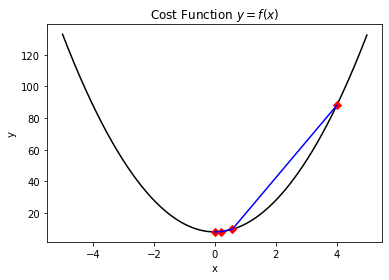
這裡簡單對程式碼中的引數作一個解釋:`DELTA`是計算梯度值時所採用的步長,`EPSILON`是精度要求,`MAX_STEPS`是最大迭代次數(避免因為達不到自洽收斂條件而陷入死迴圈),`GAMMA`是學習率(在其他的一些基於梯度的演算法中可能會採用自適應的學習率或者逐步下降的學習率來達到更好的收斂效果)。該簡單案例得到的結果如下所示:
```bash
The last value of y is: 8.00000000000125
The last value of x is: -5.000249774511634e-07
The function evaluation times is: 4
```
```bash
Optimization terminated successfully.
Current function value: 8.000000
Iterations: 3
Function evaluations: 8
Gradient evaluations: 4
The scipy method founded x is: [-9.56720569e-09]
The correspond cost function value is: [8.]
```
這裡我們可以看到,自定義的函式迭代次數`4`次要小於通用庫中所實現的`8`次函式估計。這裡由於名稱的定義有可能導致迭代次數和函式估計次數被混淆,一般基於梯度的演算法是多次函式估計後才會迭代一次,而有些非梯度的優化演算法如`COBYLA`等,則是每計算一次代價函式就代表迭代一次,這裡我們能夠簡單從數量上理解即可。
# 補充測試案例
在上面二次函式的優化成功之後,我們可以嘗試一些其他形式的函式的優化效果,如本次使用的正弦函式:
```python
from scipy.optimize import minimize as scipy_minimize
from tqdm import trange
import matplotlib.pyplot as plt
import numpy as np
DELTA = 1e-06
EPSILON = 1e-06
MAX_STEPS = 100
GAMMA = 2
MOMENTUM =0.9
def cost_function(x):
return np.sin(x)
def gradient(x, func):
return (func(x + DELTA) - func(x)) / DELTA
def next_x(x, func, iterations, v):
_tmpx = x - GAMMA * gradient(x, func) / (iterations + 1) + MOMENTUM * v
return _tmpx if cost_function(_tmpx) < cost_function(x) and gradient(_tmpx, func) * gradient(x, func) >= 0 else x
def minimize(x0, func):
_x1 = x0
_y1 = func(_x1)
plot_x = [_x1]
plot_y = [_y1]
v = 0
for i in trange(MAX_STEPS):
_x = next_x(_x1, func, i, v)
_y = func(_x)
v = _x - _x1
if v == 0:
continue
if abs(_y - _y1) <= EPSILON:
print ('The minimum value {} founded :)'.format(_y))
print ('The correspond x value is: {}'.format(_x))
print ('The iteration times is: {}'.format(i))
return _y, _x, plot_y, plot_x
_x1 = _x
_y1 = _y
plot_x.append(_x1)
plot_y.append(_y1)
print ('The last value of y is: {}'.format(_y))
print ('The last value of x is: {}'.format(_x))
return _y, _x, plot_y, plot_x
if __name__ == '__main__':
x0 = 1.4
yt, xt, py, px = minimize(x0, cost_function)
plt.figure()
x = [i / 100 - 5 for i in range(1000)]
y = [cost_function(i) for i in x]
plt.plot(x, y, color = 'black')
plt.plot(px, py, 'D', color = 'red')
print ('The function evaluation times is: {}'.format(len(py)))
plt.plot(px, py, color = 'blue')
plt.title('Cost Function $y = f(x)$') # Latex Type Equation.
plt.xlabel('x')
plt.ylabel('y')
plt.show()
result = scipy_minimize(cost_function, x0, method='BFGS', options={'disp':True})
print ('The scipy method founded x is: {}'.format(result.x))
print ('The correspond cost function value is: {}'.format(cost_function(result.x)))
```
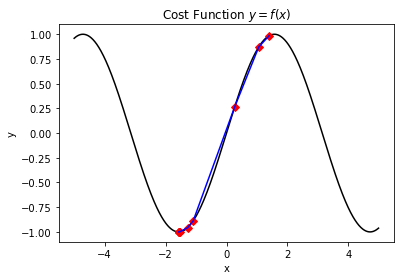
其執行效果如下:
```bash
The minimum value -0.9999986210818882 founded :)
The correspond x value is: -1.569135653179335
The iteration times is: 14
The function evaluation times is: 11
```
```bash
Optimization terminated successfully.
Current function value: -1.000000
Iterations: 2
Function evaluations: 16
Gradient evaluations: 8
The scipy method founded x is: [-1.57079993]
The correspond cost function value is: [-1.]
```
在該測試案例中,通過合理的引數配置,我們同樣可以找到比標準庫數量更少的迭代次數。其實在大部分的黑盒優化的情況下,我們並不能事先就計算好函式對應的輪廓,也無從獲取相關資訊,甚至函式運算本身也是一個複雜性較高的計算工作。因此,對於迭代次數或者函式值估計的次數的優化,也是一個值得研究的方向。
# 總結概要
梯度下降法是眾多優化演算法的基礎形式,而一眾優化演算法在機器學習、神經網路訓練以及變分量子演算法實現的過程中都發揮著巨大的作用。通過了解基本的梯度下降函式的實現原理,可以為我們帶來一些優化的思路,後續也會補充一些梯度下降函式的變種形式。可能有讀者注意到,本文中的實際的函式值估計次數要大於結果中所展現的函式值估計次數。這個觀點是對的,但是這裡我們可以通過後續會單獨講解的`lru快取`法來進行處理,這使得同樣的引數輸入下對於一個函式的訪問可以幾乎不需要時間,因此對於一個函式值的估計次數,其實僅跟最後得到的`不同函式值的數量`有關,中間存在大量的簡併。
# 版權宣告
本文首發連結為:https://www.cnblogs.com/dechinphy/p/gradient.html
作者ID:DechinPhy
更多原著文章請參考:https://www.cnblogs.com/de