
【論文研讀】Sabir, Ekraam, et al. "Recurrent convolutional strategies for face manipulation detection in videos." Interfaces (GUI)
阿新 • • 發佈:2021-02-07
Sabir, Ekraam, et al. "Recurrent convolutional strategies for face manipulation detection in videos." Interfaces (GUI) 3.1 (2019).
#摘要
錯誤資訊通過合成逼真的影象和視訊進行傳播這一嚴重問題,需要魯棒的篡改檢測方法來應對。儘管在檢測靜止影象上的面部篡改方面已付出了巨大的努力,但人們對於通過利用視訊流中存在的時序資訊,對視訊中被篡改面部的識別方面的研究較少。迴圈卷積模型是一類深度學習模型,已證明能夠有效地利用跨域影象流中的時序資訊。因此,我們通過廣泛的實驗,提出了將這些模型中的變化與特定領域的面部預處理技術相結合的最佳策略(根據後文應該是面部對齊和CNN (DenseNet) + bidirectional RNN),從而在公開的基於視訊的面部篡改benchmark上達到了目前最先進的效能。具體來說,我們嘗試檢測Deepfake,Face2Face和FaceSwap生成的視訊流中的篡改人臉。對最近提出的 FaceForensics++資料集進行評估,將以前的最先進技術的精確度提高 4.55%。
#1. Introduction
錯誤資訊可以以不同的方式表現:直接篡改資訊(如copy-move和splicing)或在誤導的環境中呈現未篡改的內容(如image repurposing)。
通過深度學習生成的人臉的偽像是如此微妙,以至於評估臉部真假的唯一線索是(i) 頭髮的微妙不一致 - 頭髮太直,斷線或乾脆不自然,(ii) 不自然不對稱的臉,(iii) 奇怪的牙齒,更重要的是,大多數時候,(iv) 其他更明顯的不一致不在臉上而在背景上。
假視訊數量的激增可能歸因於兩個原因:1. 將某人的身份或表情換成別人的,現在更容易了;2. 一段視訊比一張圖片更可信。
鑑於上述觀察結果,並考慮到人臉篡改生成工具不會在合成過程中增強時間連貫性,而是逐幀執行操作,因此我們提出利用時間上的偽像來指示視訊流中的異常人臉。
本文使用迴圈卷積模型以利用時間差異來改進當前方法。為了消除與視訊中面部剛性運動相關的其他混淆因素,本文還使用了面部對齊方法。
#2. Related Work
**Video processing with deep models.**
這方面有三種主要方法:
• 第一種研究從兩個流網路 [37] 發展,其中 RGB 視訊幀及其光流版本在網路中的兩個獨立分支中處理,然後是融合機制。
• 第二個是由迴圈卷積層支援的單個流網路:使用提取高階語義特徵的單獨卷積神經網路 (CNN) 收集每個幀中內容的感知知識,同時在這些特徵上訓練一個迴圈模型,以執行對時間維度的決策。
• 第三種發展使用 3D 卷積 [40, 19] 作為網路中的local building block,以學習豐富的時空特徵。
本文認為基於雙流架構的方法在動作識別方面是有效的,但與捕獲生成器在視訊中可能產生的細微閃爍的偽像不相關;並且另一方面,3D卷積雖然可能更適合於此目的,但它們會大大增加可學習的濾波器的數量。因此本文使用第二種方法。
**Face manipulation benchmarks.**
FaceForensics以及FaceForensics++。
**Face Manipulation Detection.**
XceptionNet [8]、MesoNet [4]、GoogLeNet等等。
#3. Method
篡改檢測的整體方法是分成兩步:從視訊幀裁剪和對齊人臉,然後對預處理面部區域進行篡改檢測。
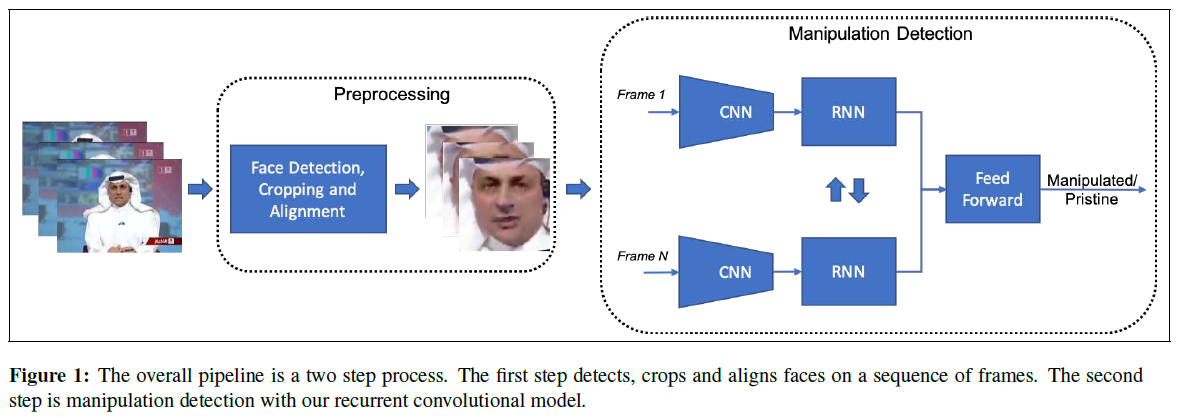
##3.1. Face preprocessing
兩種用於對齊人臉的技術:(i)使用面部landmark進行顯式對齊,其中參考座標系和麵部裁剪的緊度由先驗知識決定,並且所有面部都與該參考座標系對齊,以便補償面部的任何剛性運動,(ii)使用基於可學習的仿射變換的空間轉換網路(STN:Spatial Transformer Network )進行隱式對齊。
**Landmark-based alignment.**
使用簡單的相似度轉換(四個自由度)對齊人臉影象,以補償各向同性比例,平面內旋轉和2D平移。轉換後,解析度為224×224。
**Spatial Transformer Network.**
其包括三個部分:定位網路,網格生成器和取樣器。定位網路預測仿射變換引數,並且網格生成器和取樣器將輸入特徵圖使用仿射引數包裝以生成輸出特徵圖。
##3.2. Videobased Face Manipulation Detection
使用迴圈卷積網路利用視訊幀之間的時序偽像進行篡改檢測。
**Backbone encoding network.**
本文使用ResNet [14]和DenseNet [15]作為模型的CNN元件有如下兩個原因:
(i)FaceForensics ++ [34]是一個包含1,000個視訊的低解析度資料集,為避免過擬合,作者不得不使用經過預訓練的具有固定特徵提取層的XceptionNet [8]。
為了實現端到端的可訓練性,本文選擇了ResNet [14]。
(ii)篡改偽像表現為不需要高階面部語義特徵的低階特徵(例如不連續的下巴,眼睛模糊等)。
DenseNet也是一種合適的CNN架構,因為它提取了不同層次結構的特徵。並使用cross-entropy loss。
**RNN training strategies.**實驗將迴圈模型放置在backbone網路的不同部分:它將backbone網路連線在一起,充當特徵學習器,將特徵傳遞給RNN,隨著時間的推移彙總。本文實驗了兩種策略:第一個是在backbone網路的最終特徵之上僅使用單個迴圈網路。第二個是嘗試在backbone網路層次結構的不同級別上學習多個迴圈網路。從CNN中提取多個特徵級別的特徵以進行篡改檢測,這些特徵在單個迴圈網路中處理,期望這個新的多迴圈卷積模型能夠利用微觀,中觀和巨集觀特徵進行篡改檢測。
#4. Experiments
通過實驗發現(1)DenseNet優於ResNet,(2)面部對齊可提高效能,(3)影象序列要比單幀輸入更好。
#5. Conclusion
We found a landmark based face alignment with bidirectional-recurrent-denset to perform the best for face manipulation detection in