
深入理解 Web 協議 (三):HTTP 2
本篇將詳細介紹 HTTP 2 協議的方方面面,知識點如下:
- HTTP 2 連線的建立
- HTTP 2 中幀和流的關係
- HTTP 2 中流量節省的奧祕:HPACK 演算法
- HTTP 2 協議中 Server Push 的能力
- HTTP 2 為什麼要實現流量控制?
- HTTP 2 協議遇到的問題
一、HTTP 2 連線的建立
和許多人的固有印象不同的是 HTTP 2協議本身並沒有規定必須建立在TLS/SSL之上,其實用普通的TCP連線也可以完成HTTP 2連線的建立。只不過現在為了安全市面上所有的瀏覽器都僅預設支援基於TLS/SSL的 HTTP 2協議。簡單來說我們可以把構建在TCP連線之上的 HTTP 2 協議稱之為H2C,而構建在TLS/SSL協議之上的就可以理解為是H2了。
輸入命令:
tcpdump -i eth0 port 80 and host nghttp2.org -w h2c.pcap &
然後用curl訪問基於TCP連線,也就是port 80埠的 HTTP 2站點(這裡是沒辦法用瀏覽器訪問的,因為瀏覽器不允許)
curl http://nghttp2.org --http2 -v
其實看日誌也可以大致瞭解一下這個連線建立的過程:
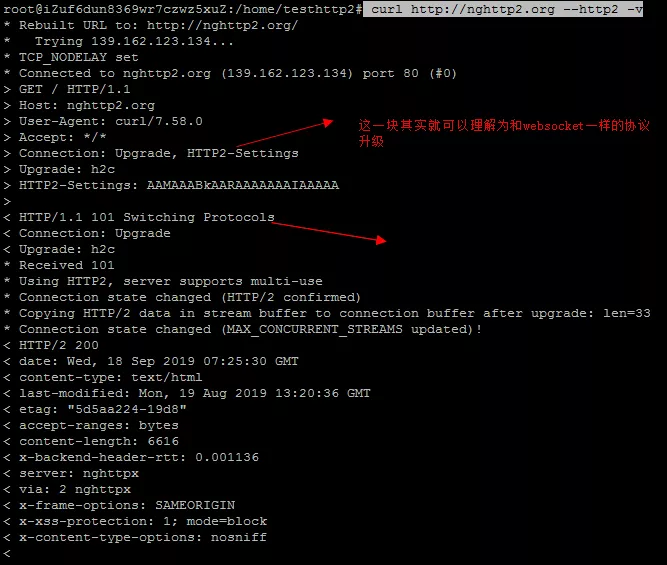
我們將TCPDump出來的pcap檔案拷貝到本地,然後用Wireshark開啟以後還原一下整個HTTP 2連線建立的報文:
首先是 HTTP 1.1 升級到 HTTP 2 協議
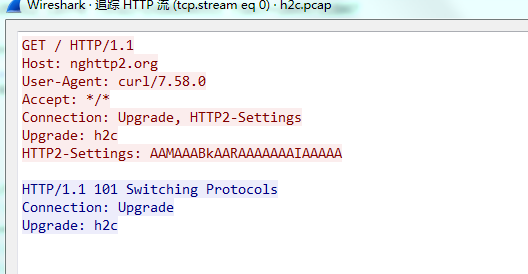
然後客戶端還需要傳送一個“魔法幀”:
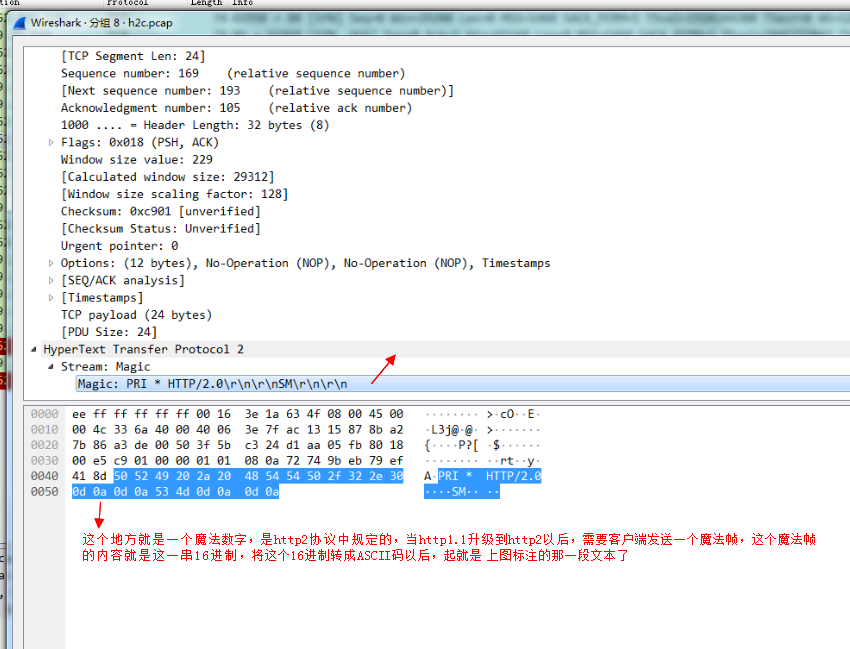
最後還需要傳送一個設定幀:
之後,我們來看一下,基於TLS的 HTTP 2連線是如何建立的,考慮到加密等因素,我們需要提前做一些準備工作。可以在Chrome中下載這個外掛。

然後開啟任意一個網頁只要看到這個閃電的圖示為藍色就代表這個站點支援HTTP 2;否則不支援。如下圖:
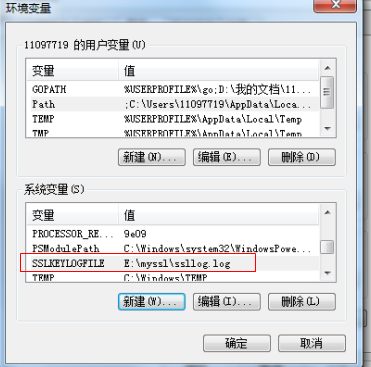
將Chrome瀏覽器的TLS/SSL之類的資訊 輸出到一個日誌檔案中,需要額外配置系統變數,如圖所示:
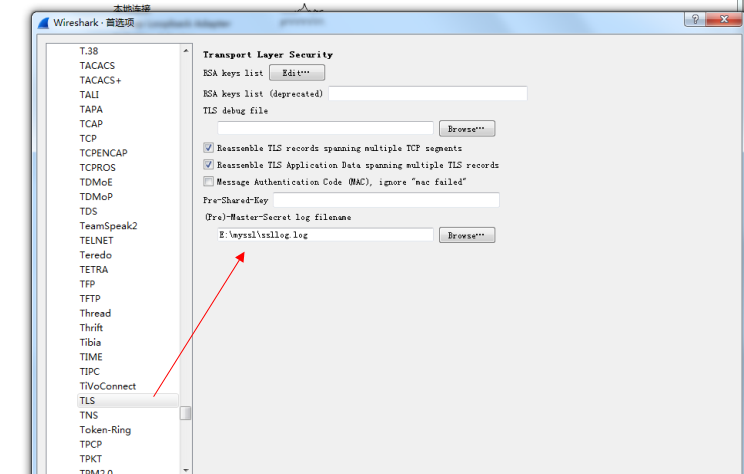
然後將我們的Wireshark中SSL相關的設定也進行配置。
這樣瀏覽器在進行TLS協議互動的時候,相關的加密解密資訊都會寫入到這個log檔案中,我們的Wireshark就會用這個log檔案中的資訊來解密出我們的TLS報文。
有了上述的基礎,我們就可以著手分析基於TLS連線的HTTP 2協議了。比如我們訪問tmall的站點 https://www.tmall.com/ 然後開啟我們的Wireshark。
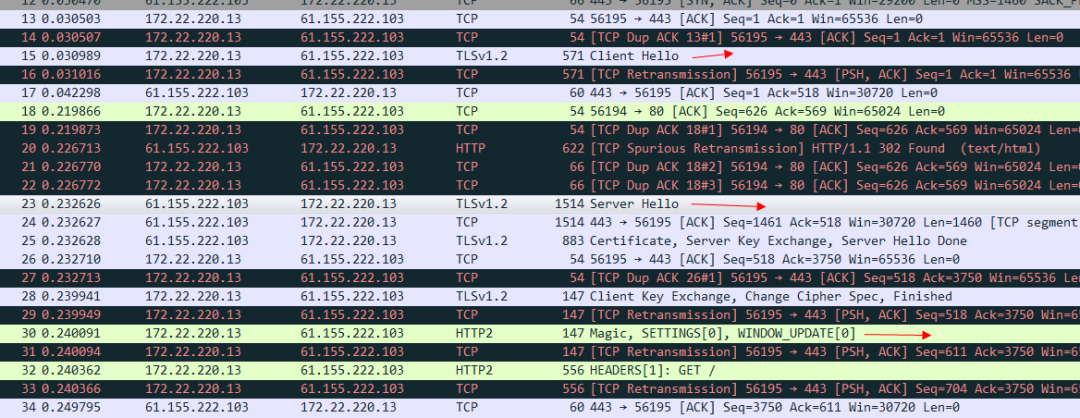
看一下標註的地方可以看出來,是TLS連線建立以後 然後繼續傳送魔法幀和設定幀,才代表HTTP 2的連線真正建立完畢。我們看一下TLS報文的client hello 這個資訊:
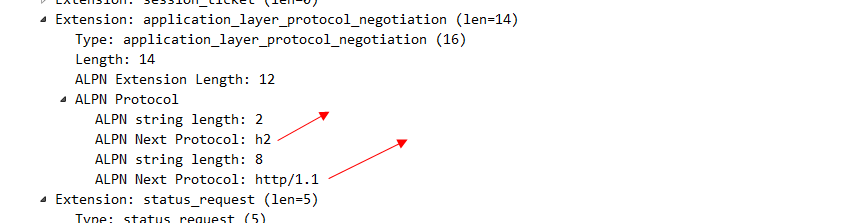
其中這個alpn協議的資訊 就代表客戶端可以接受哪兩種協議。server hello 這個訊息 就明確的告知 我們要使用H2協議。
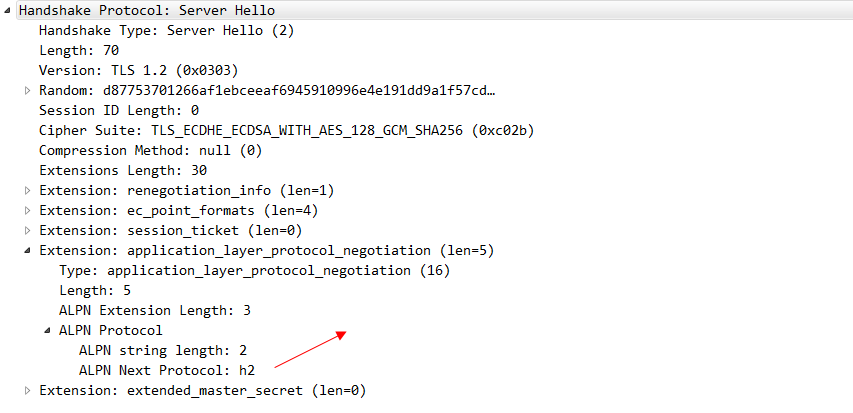
這也是HTTP 2相比spdy協議最重要的一個優點:spdy協議強依賴TLS/SSL,伺服器沒有任何選擇。而HTTP 2協議則會在客戶端發起請求的時候攜帶alpn這個擴充套件,也就是說客戶端發請求的時候會告訴服務端我支援哪些協議。從而可以讓服務端來選擇,我是否需要走TLS/SSL。
二、HTTP 2 中幀和流的關係
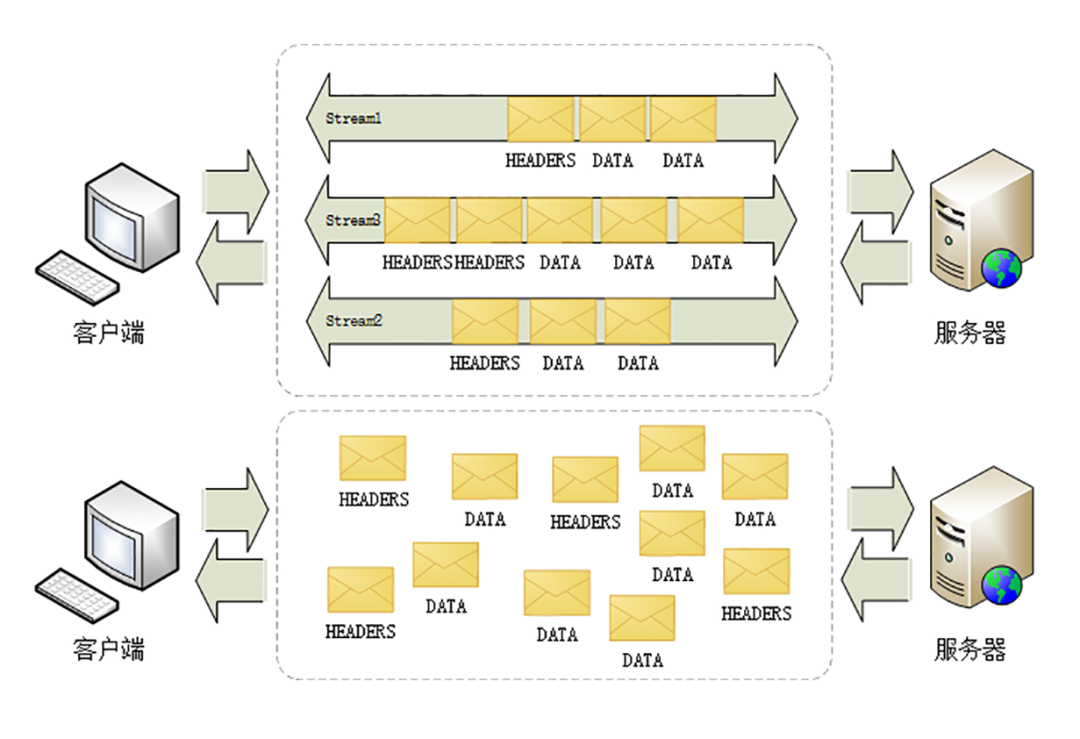
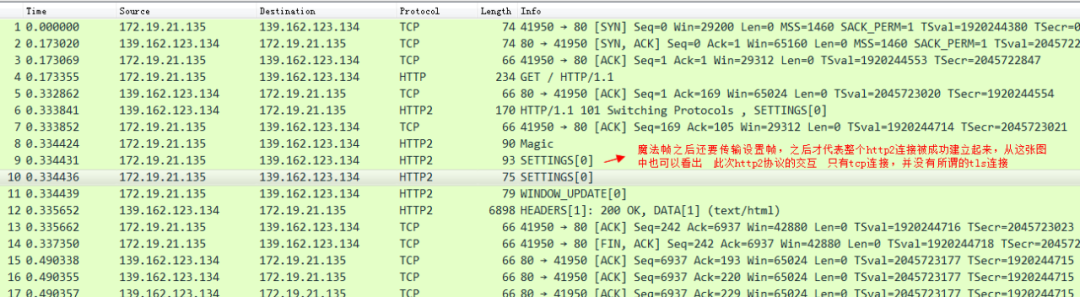
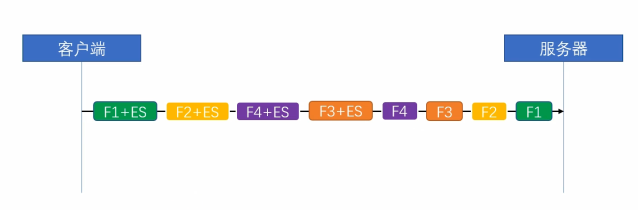
簡單來說,HTTP 2就是在應用層上模擬了一下傳輸層TCP中“流”的概念,從而解決了HTTP 1.x協議中的隊頭擁塞的問題,在1.x協議中,HTTP 協議是一個個訊息組成的,同一條TCP連線上,前面一個訊息的響應沒有回來,後續的訊息是不可以傳送的。在HTTP 2中,取消了這個限制,將所謂的“訊息”定義成“流”,流跟流之間的順序可以是錯亂的,但是流裡面的幀的順序是不可以錯亂的。如圖:
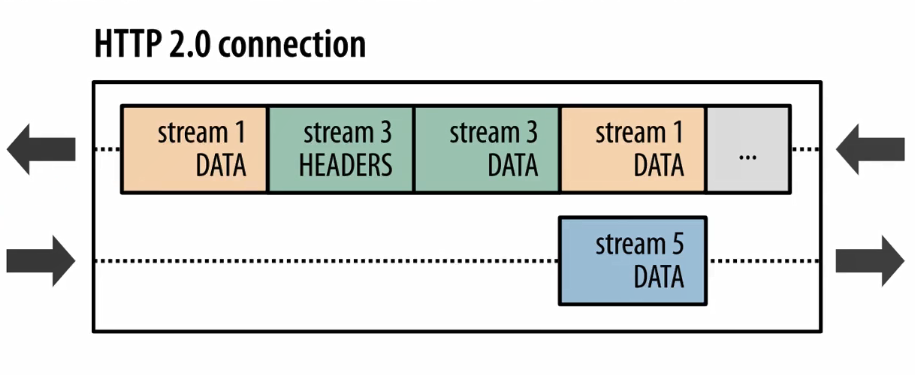
也就是說在同一條TCP連線上,可以同時存在多個stream流,這些流 由一個個frame幀組成,流跟流之間沒有順序關係,但是每一個流內部的幀是有先後順序的。注意看這張圖中的 135 等數字其實就是stream id,WebSocket中雖然也有幀的概念,但是因為WebSocket中沒有stream id,所以Websocket是沒有多路複用的功能的。HTTP 2 因為有了stream id所以就有了多路複用的能力。可以在一條TCP連線上存在n個流,就意味著服務端可以同時併發處理n個請求然後同時將這些請求都響應到同一條TCP連線上。當然這種在同一條TCP連線上傳送n個stream的能力也是有限制的,在 HTTP 2 連線建立的時候,setting幀 中會包含這個設定資訊。例如下圖 在訪問天貓的站點的時候,瀏覽器攜帶的setting幀的訊息裡面就標識了 瀏覽器這個HTTP 2的客戶端可以支援併發最大的流為1000。
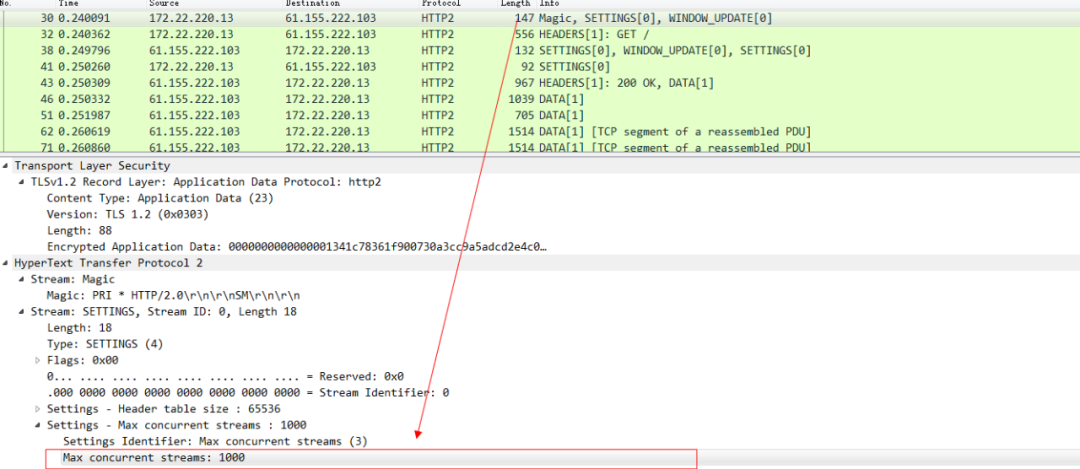
當天貓伺服器返回這個setting幀的響應的時候,就告知了瀏覽器,我能支援的最大併發stream為128。
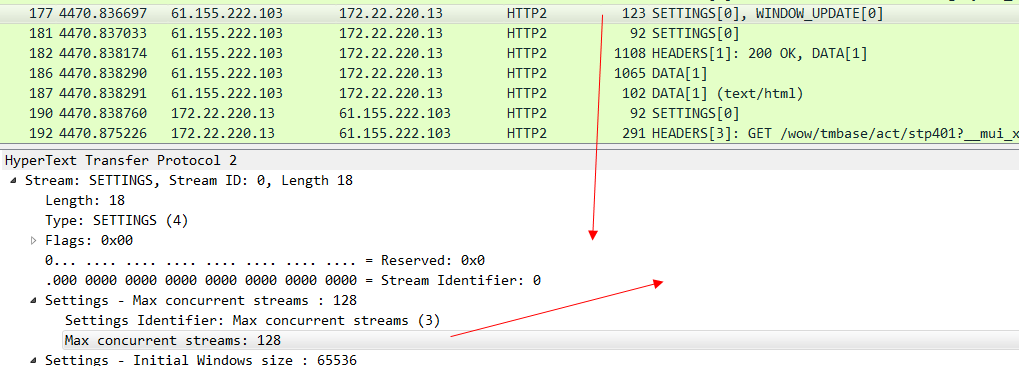
同時 我們也要知道,HTTP 2協議中 流id為單數就代表是客戶端發起的流,偶數代表服務端主動發起的流(可以理解為服務端主動推送)。
三、 HTTP 2 中流量節省的奧祕:HPACK 演算法
相比與HTTP 1.x協議,HTTP 2協議還在流量消耗上做了極大改進。主要分為三塊:靜態字典,動態字典,和哈夫曼編碼. 可以安裝如下工具探測一下 對流量節省的作用:
apt-get install nghttp2-client
然後可以探測一下一些已經開啟 HTTP 2的站點,基本上節約的流量都是百分之25起,如果頻繁訪問的話 會更多:
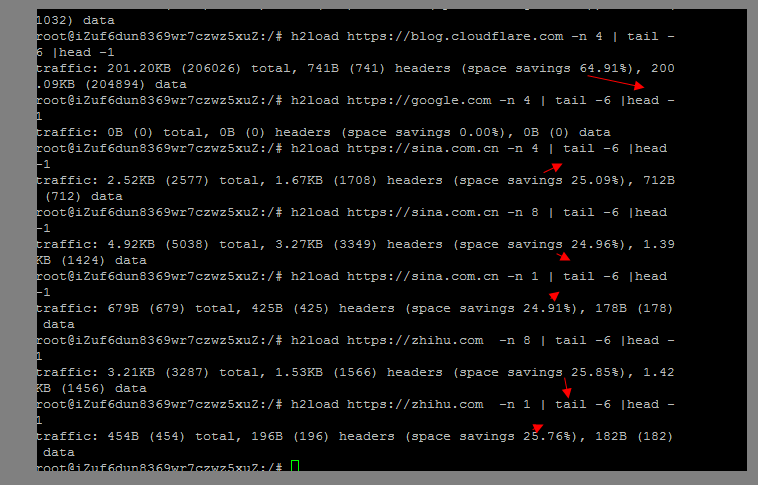
對於流量消耗來說,其實HTTP 2相比HTTP 1.x協議最大的改進就是在HTTP 2中我們可以對HTTP 的頭部進行壓縮了,而在以往HTTP 1.x協議中,gzip等是無法對header進行壓縮的,尤其對於絕大多數的請求來說,其實header的佔比是最大的。
我們首先來了解一下靜態字典,如圖所示:
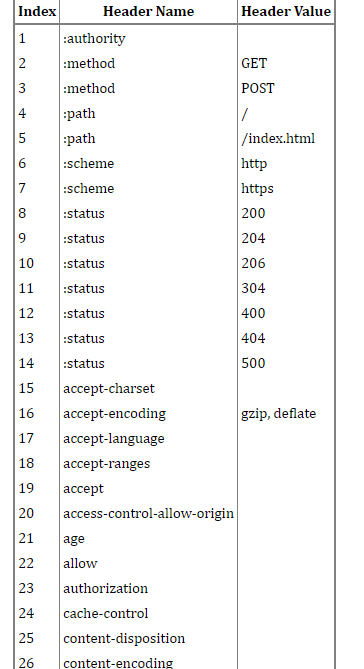
這個其實不難理解,無非就是將我們那些常用的HTTP 頭部,用固定的數字來表示,那當然可以起到節約流量的作用.這裡要注意的是 有些value 情況比較複雜的header,他們的value 是沒有做靜態字典的。比如cache-control這個快取控制欄位,這後面的值因為太多了就無法用靜態字典來解決,而只能靠霍夫曼編碼。下圖可以表示 HPACK這種壓縮演算法 起到的節約流量的作用:
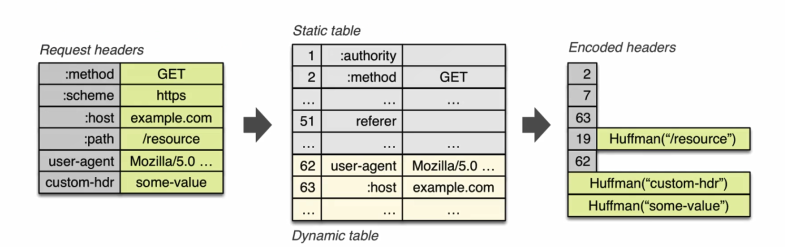
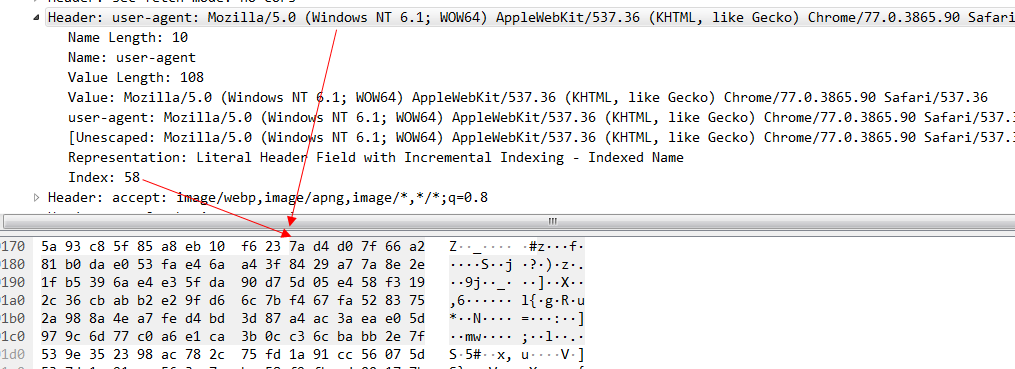
例如,我們看下62這個 頭部,user-agent 代指瀏覽器,一般我們請求的時候這個頭部資訊都是不會變的,所以最終經過hpack演算法優化以後 後續再傳輸的時候 就只需要傳輸62這個數字就可以代表其含義了。
又例如下圖:
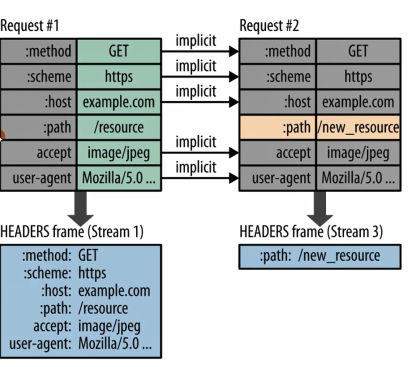
也是一樣的,多個請求連續傳送的時候,多數情況下變化的只有path,其餘頭部資訊是不變的,那麼基於此場景,最終傳輸的時候也就只有path這一個頭部資訊了。
最後我們來看看hpack演算法中的核心:哈夫曼編碼。哈弗曼編碼核心思想就是出現頻率較高的用較短的編碼,出現頻率較低的用較長的編碼(HTTP 2協議的前身spdy協議採用的是動態的哈夫曼編碼,而HTTP 2協議則選擇了靜態的哈夫曼編碼)。
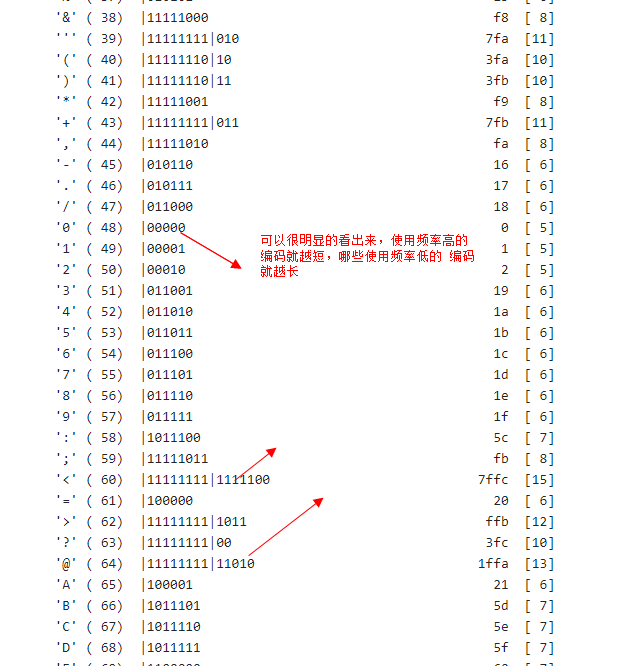
來看幾個例子:
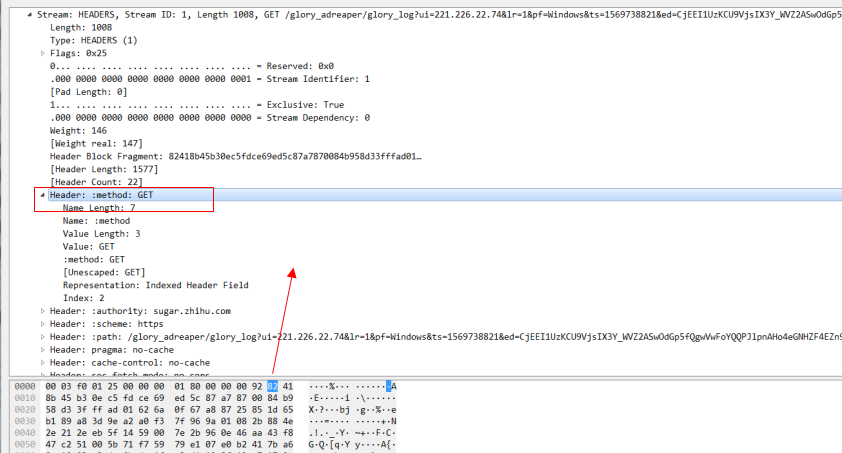
例如這個header幀,注意看這個method:get的頭部資訊。因為method:get 在靜態索引表中的索引值為2.對於這種key和value都在索引表中的值,我們用一個位元組也就是8個bit來標識,其中第一個bit固定為1,剩下7位就用來表示索引表中的值,這裡method:get 索引表的值為2,所以這個值就是1000 0010,換算成16進位制就是0x82.
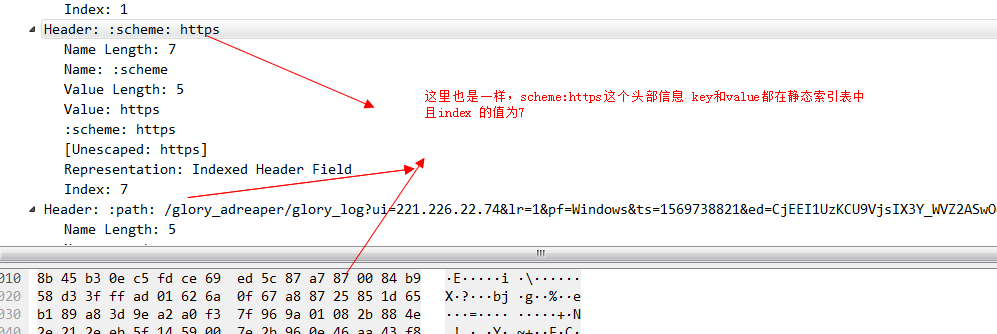
再看一組,key在索引表中,value 不在索引表中的header例子。
對於key在索引表中,value 不在索引表中的情況,固定是01開頭的位元組,後面6個bit(111010 換算成十進位制就是58)就是靜態索引的值, user-agent在索引中index的值是58 再加上01開頭的2個bit 換算成二進位制就是01111010,16進位制就7a了。然後接著看第二個位元組,0xd4,0xd4換算成二進位制就是 1 101 0100,其中第一個bit 代表後面採用的是哈夫曼編碼,後面的7個bit 這個key-value的value 需要幾個位元組來表示,這裡是101 0100 換算成10進位制就是84,也就是說這個user-agent後面的value需要84個位元組來表示,我們數一下圖中的位元組數 16*5+第一排d4後面的4個位元組,剛好等於84個位元組。
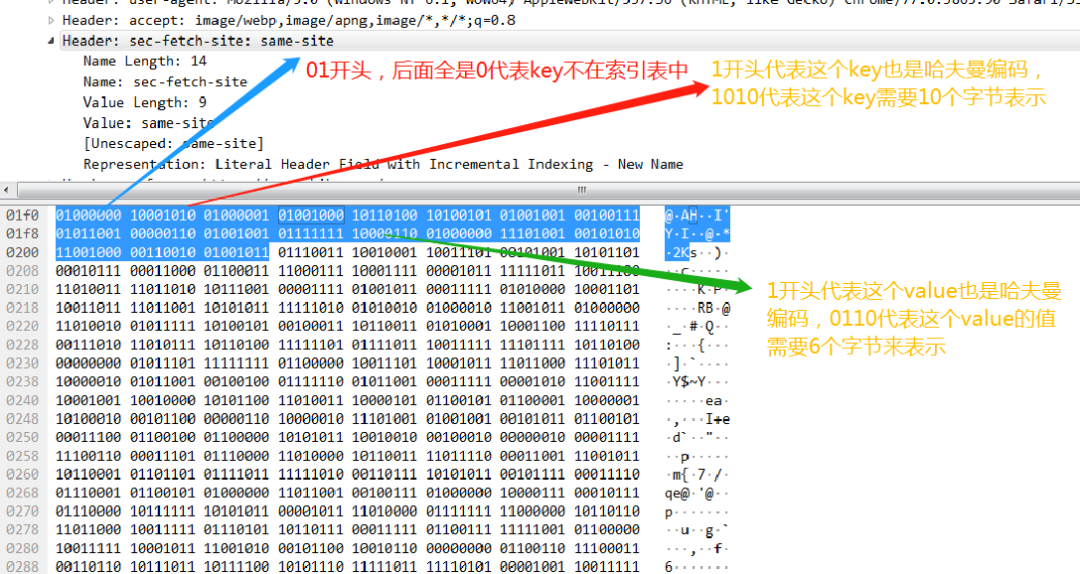
最後再看一個key和value 都不在索引表中的例子。
四、HTTP 2 協議中 Server Push 的能力
前文我們提到過,H2相比H1.x協議提升最大的就是H2可以在單條TCP連線的基礎上 同時傳輸n個stream。從而避免H1.x協議中隊頭擁塞的問題。實際上在大部分前端的頁面中,我們還可以使用H2協議的Server Push能力 進一步提高頁面的載入速度。例如通常我們用瀏覽器訪問一個Html頁面時,只有當html頁面返回到瀏覽器,瀏覽器核心解析到這個Html頁面中有CSS或者JS之類的資源時,瀏覽器才會傳送對應的CSS或者JS請求,當CSS和JS回來以後 瀏覽器才會進一步渲染,這樣的流程通常會導致瀏覽器處於一段時間內的白屏從而降低使用者體驗。有了H2協議以後,當瀏覽器訪問一個Html頁面到伺服器時,伺服器就可以主動推送相應的CSS和JS的內容到瀏覽器,這樣就可以省略瀏覽器之後重新發送CSS和JS請求的步驟。
有些人對Server Push存在一定程度上的誤解,認為這種技術能夠讓伺服器向瀏覽器傳送“通知”,甚至將其與WebSocket進行比較。事實並非如此,Server Push只是省去了瀏覽器傳送請求的過程。只有當“如果不推送這個資源,瀏覽器就會請求這個資源”的時候,瀏覽器才會使用推送過來的內容。否則如果瀏覽器本身就不會請求某個資源,那麼推送這個資源只會白白消耗頻寬。當然如果與伺服器通訊的是客戶端而不是瀏覽器,那麼HTTP 2協議自然就可以完成 push推送的功能了。所以都使用HTTP 2協議的情況下,與伺服器通訊的是客戶端還是瀏覽器 在功能上還是有一定區別的。
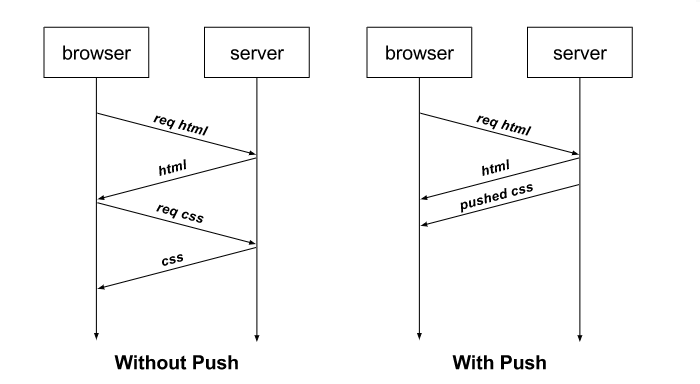
下面為了演示這個過程,我們寫一段程式碼。考慮到瀏覽器訪問HTTP 2站點必須要建立在TLS連線之上,我們首先要生成對應的證書和祕鑰。

然後開啟HTTP 2,在接收到Html請求的時候主動push Html中引用的CSS檔案。
package main
import (
"fmt"
"net/http"
"github.com/labstack/echo"
)
func main() {
e := echo.New()
e.Static("/", "html")
//主要用來驗證是否成功開啟http2環境
e.GET("/request", func(c echo.Context) error {
req := c.Request()
format := `
<code>
Protocol: %s<br>
Host: %s<br>
Remote Address: %s<br>
Method: %s<br>
Path: %s<br>
</code>
`
return c.HTML(http.StatusOK, fmt.Sprintf(format, req.Proto, req.Host, req.RemoteAddr, req.Method, req.URL.Path))
})
//在收到html請求的時候 同時主動push html中引用的css檔案,不需要等待瀏覽器發起請求
e.GET("/h2.html", func(c echo.Context) (err error) {
pusher, ok := c.Response().Writer.(http.Pusher)
if ok {
if err = pusher.Push("/app.css", nil); err != nil {
println("error push")
return
}
}
return c.File("html/h2.html")
})
//
e.StartTLS(":1323", "cert.pem", "key.pem")
}
然後Chrome訪問這個網頁的時候,看下NetWork面板:

可以看出來這個CSS檔案 就是我們主動push過來的。再看下Wireshark。

可以看出來 stream id為13的 是客戶端發起的請求,因為id是單數的,在這個stream中,還存在著push_promise幀,這個幀就是由伺服器傳送給瀏覽器的,看一下他的具體內容。
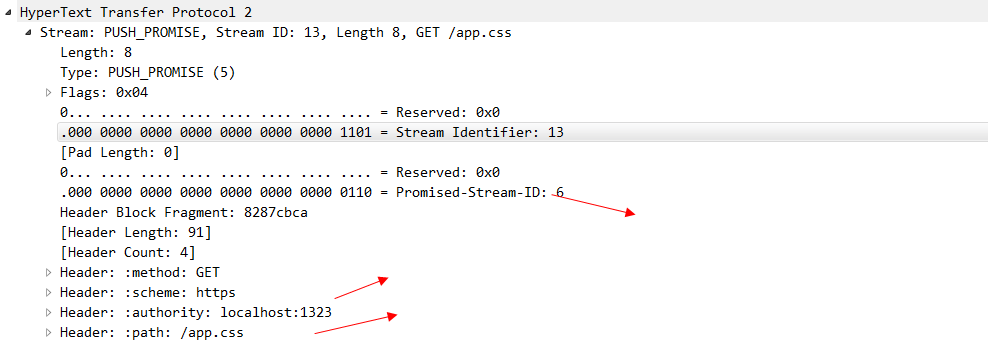
可以看出來這個幀就是用來告訴瀏覽器,我主動push給你的是哪個資源,這個資源的stream-id 是6.圖中我們也看到了有一個stream-id 為6的 data在傳輸了,這個就是伺服器主動push出來的CSS檔案。到這裡,一次完整的Server Push就互動完畢了。
但在實際線上應用Server Push的時候 挑戰遠遠比我們這個demo中來的複雜。首先就是大部分cdn供應商(除非自建cdn)對Server Push的支援比較有限。我們不可能讓每一次資源的請求都直接打到我們的源伺服器上,大部分靜態資源都是前置在CDN中。其次,對於靜態資源來說,我們還要考慮快取的影響,如果是瀏覽器自己發出去的靜態資源請求,瀏覽器是可以根據快取狀態來決定這個資源我是否真的需要去請求,而Server Push 是伺服器主動發起的,伺服器多數情況下是不知道這個資源的快取是否過期的。當然可以在瀏覽器接收到push Promise幀以後,查詢自身的快取狀態然後發起RST_STREAM幀,告知伺服器這個資源我有快取,不需要繼續傳送了,但是你沒辦法保證這個RST_STREAM在到達伺服器的時候,伺服器主動push出去的data幀還沒發出去。所以還是會存在一定的頻寬浪費的現象。總體來說,Server Push 還是一個提高前端使用者體驗相當有效的手段,使用了Server Push以後 瀏覽器的效能指標 idle指標 一般可以提高3-5倍(畢竟瀏覽器不用等待解析Html以後再去請求CSS和JS了)。
五、HTTP 2 為什麼要實現流量控制?
很多人不理解,為什麼TCP傳輸層已經實現了流量控制,我們的應用層 HTTP 2 還要實現流量控制。下面我們看一張圖。
在HTTP 2協議中,因為我們支援多路複用,也就是說我們可以同時傳送多個stream 在同一條TCP連線中,上圖中,每一種顏色就代表一個stream,可以看到 我們總共有4種stream,每一個stream又有n個frame,這個就很危險了,假設在應用層中我們使用了多路複用,就會出現n個frame同時不停的傳送到目標伺服器中,此時流量達到頂峰就會觸發TCP的擁塞控制,從而將後續的frame全部阻塞住,造成伺服器響應過慢了。HTTP 1.x 中因為不支援多路複用自然就不存在這個問題。且我們之前多次提到過,一個請求從客戶端到達伺服器端要經過很多的代理伺服器,這些代理伺服器記憶體大小以及網路情況都可能不一樣,所以在應用層上做一次流量控制儘量避開觸發TCP的流控是十分有必要的。在HTTP 2協議中的流量控制策略,遵循以下幾個原則:
- 客戶端和服務端都有流量控制能力。
- 傳送端和接收端可以獨立設定流控能力。
- 只有data幀才需要流控,其他header幀或者push promise幀等都不需要。
- 流控能力只針對TCP連線的兩端,中間即使有代理伺服器,也不會透傳到源伺服器上。
訪問知乎的站點看一下抓包。
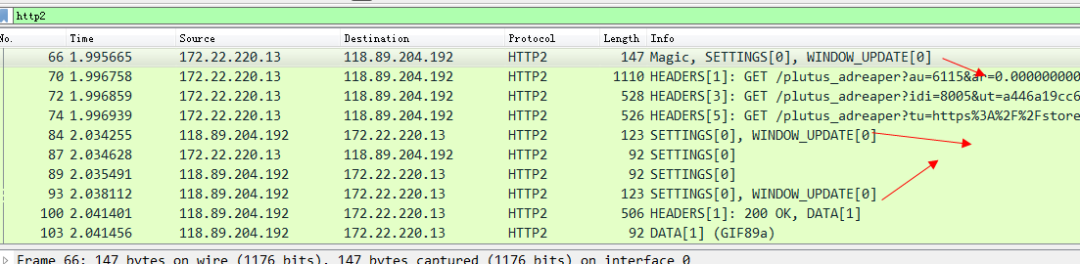
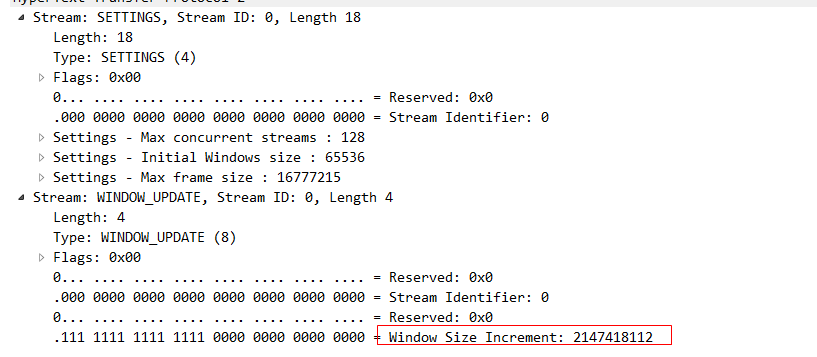
這些標識window_update幀的 就是所謂的流控幀了。我們隨意點開一個看一下,就可以看到這個流量控制幀告訴我們的幀大小。
聰明如你一定能想到,既然HTTP 2都能做到流控了,那一定也可以來做優先順序。比方說在HTTP 1.x協議中,我們訪問一個Html頁面,裡面會有JS和CSS還有圖片等資源,我們同時傳送這些請求,但是這些請求並沒有優先順序的概念,誰先出去誰先回來都是未知的(因為你也不知道這些CSS和JS請求是不是在同一條TCP連線上,既然是分散在不同的TCP中,那麼哪個快哪個慢是不確定的),但是從使用者體驗的角度來說,肯定CSS的優先順序最高,然後是JS,最後才是圖片,這樣就可以大大縮小瀏覽器白屏的時間。在HTTP 2中 實現了這樣的能力。比如我們訪問sina的站點,然後抓包就可以看到:
可以看下這個CSS 幀的的優先順序:
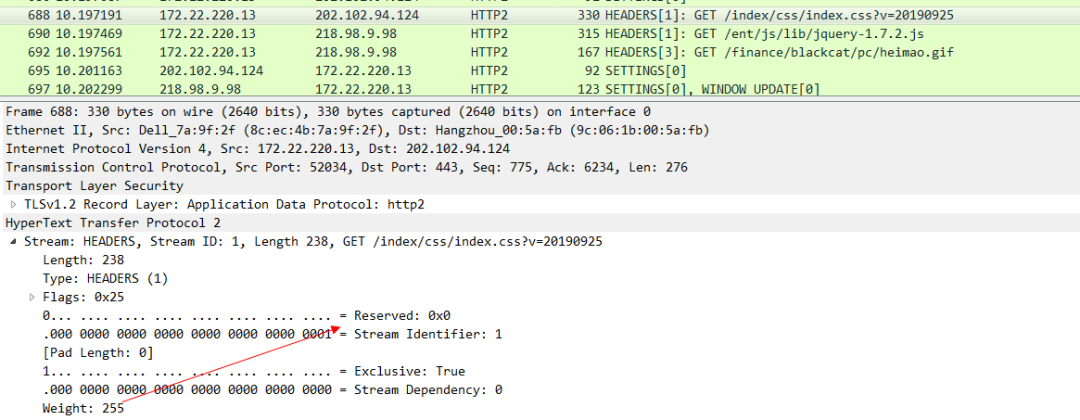
JS的優先順序
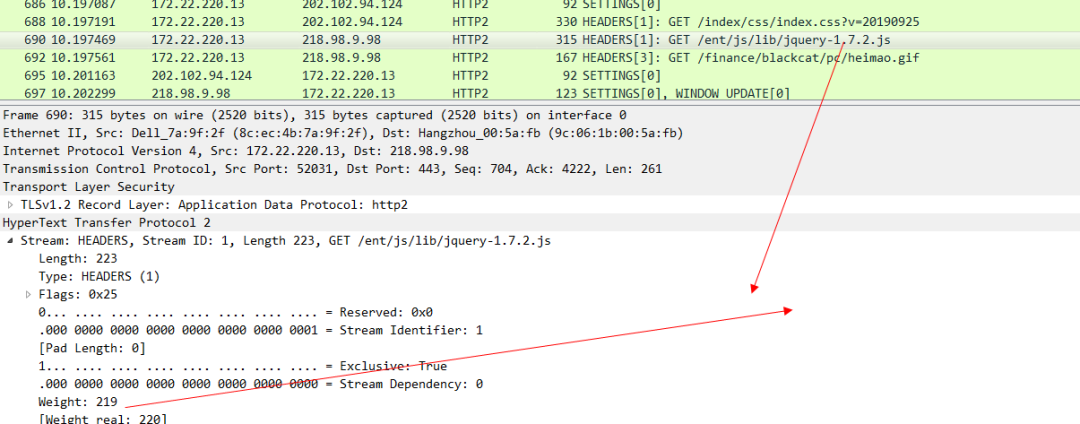
最後是gif圖片的優先順序 ,可以看出來這個優先順序是最低的。
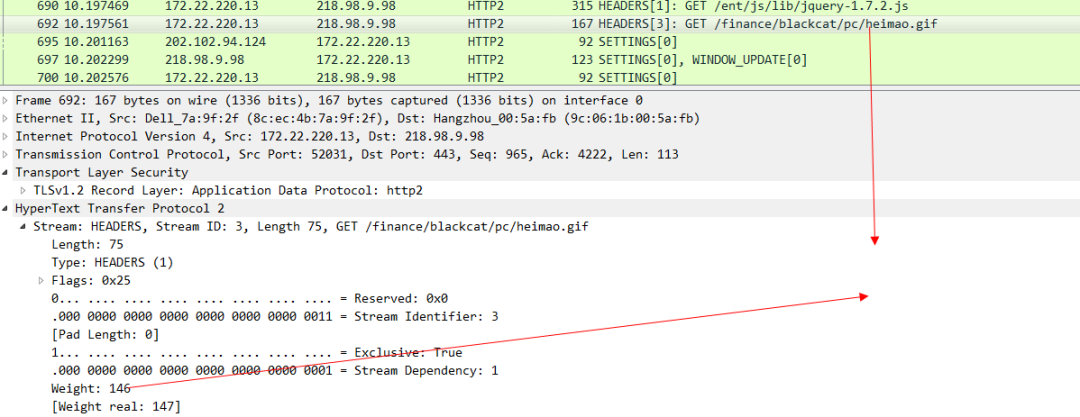
有了weight這個關鍵字來標識優先順序,伺服器就知道哪些請求需要優先被響應優先被髮送response,哪些請求可以後一點被髮送。這樣瀏覽器在整體上提供給使用者的體驗就會變的更好。
六、HTTP 2 協議遇到的問題
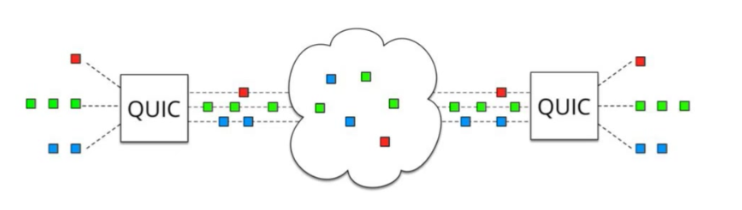
基於TCP或者TCP+TLS的 HTTP 2協議 還是遇到了很多問題,比如:握手時間過長問題,如果是基於TCP的HTTP 2協議,那麼至少要三次握手,如果是TCP+TLS的HTTP 2協議,除了TCP的握手還要經歷TLS的多次握手(TLS1.3已經可以做到只有1次握手)。每一次握手都需要傳送一個報文然後接收到這個報文的ack才可以進行下一次握手,在弱網環境下可以想象的到這個連線建立的效率是極低的。此外,TCP協議天生的隊頭擁塞 問題也一直在困擾著HTTP 21.x協議和HTTP 2協議。我們看一下谷歌spdy的宣傳圖,可以更加精準的理解這個擁塞的本質:
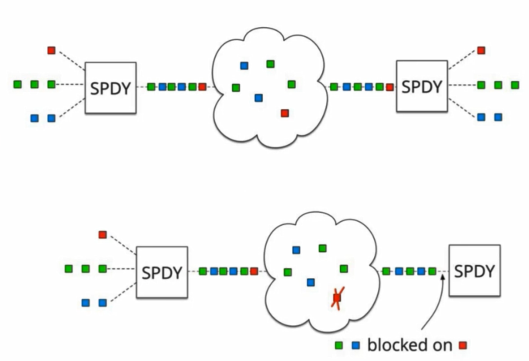
圖一很好理解,我們多路複用支援下同時發了3個stream,然後經過TCP/IP協議 傳送到伺服器端,然後TCP協議把這些資料包再傳給我們的應用層,注意這裡有個條件是,傳送包的順序要和接收包的順序一致。上圖中可以看到那些方塊的圖的順序是一致的,但是如果碰到下圖中的情況,比如說這些資料包恰好第一個紅色的資料包傳丟了,那麼後續的資料包即使已經到了伺服器的機器裡,也無法立刻將資料傳遞給我們的應用層協議,因為TCP協議規定好了接收的順序要和傳送的順序保持一致,既然紅色的資料包丟失了,那麼後續的資料包就只能阻塞在伺服器裡,一直等到紅色的資料包經過重新發送以後成功到達伺服器了,再將這些資料包傳遞給應用層協議。
TCP協議除了有上述的一些缺陷以外,還有一個問題就是TCP協議的實現者是在作業系統層面,我們任何語言,包括 Java,C,C++,Go等等 對外暴露的所謂Socket程式設計介面 最終實現者其實都是作業系統自己。要讓作業系統自己升級TCP協議的實現是非常非常困難的,況且整個網際網路中那麼多裝置想要整體實現TCP協議的升級是一件不現實的事情(IPV6協議升級的過慢也有這方面的原因)。基於上述問題,谷歌就基於udp協議封裝了一層quic協議(其實很多基於udp協議的應用層協議,都是在應用層上部分實現了TCP協議的若干功能),來替代HTTP 21.x-HTTP 2中的TCP協議。
我們開啟Chrome中的quic協議開關:

然後訪問一下youtube(國內的b站其實也支援)。
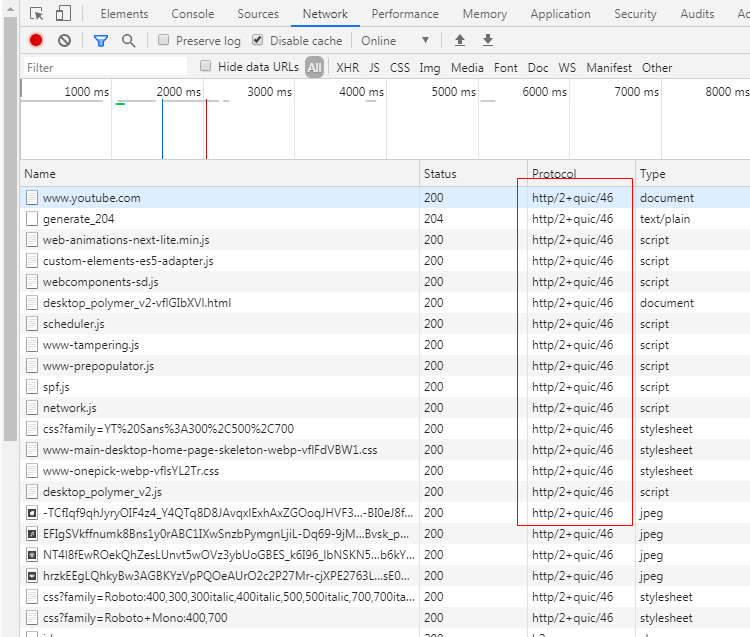
可以看出來已經支援quic協議了。為什麼這個選項在Chrome瀏覽器中預設是關閉的,其實也很好理解,這個quic協議實際上是谷歌自己搞出來的,還沒有被正式納入到HTTP 3協議中,一切都還在草案中。所以這個選項預設是關閉的。看下quic協議相比於原來的TCP協議主要做了哪些改進?其實就是將原來佇列傳輸報文改成了無需佇列傳輸,那自然也就不存在隊頭擁塞的問題了。
此外在HTTP 3中還提供了 變更埠號或者ip地址也可以複用之前連線的能力,個人理解這個協議支援的特性可能更多是為了物聯網考慮的。物聯網中很多裝置的ip都可能是一直變化的。能複用之前的連線將會大大提高網路傳輸的效率。這樣就可以避免目前存在的斷網以後重新連線到網路需要至少經過1-3個rtt才可以繼續傳輸資料的弊端。
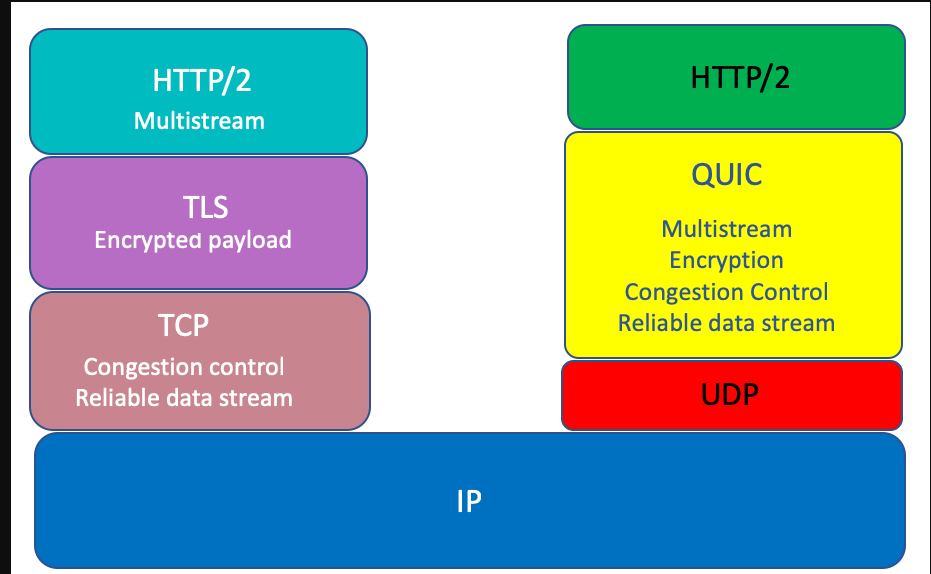
最後要提一下,在極端弱網環境中,HTTP 2 的表現有可能不如HTTP 1.x,因為HTTP 2下面只有一條TCP連線,弱網下,如果丟包率極高,那麼會不斷的觸發TCP層面的超時重傳,造成TCP報文的積壓,遲遲無法將報文傳遞給上面的應用層,但是HTTP 1.x中,因為可以使用多條TCP連線,所以在一定程度上,報文積壓的情況不會像HTTP 2那麼嚴重,這也是我認為的HTTP 2協議唯一不如HTTP 1.x的地方,當然這個鍋是TCP的,並不是HTTP 2本身的。
更多閱讀:
- 深入理解web協議(二):DNS、WebSocket
- 深入理解 web 協議(一):http 包體傳輸
作者:vivo 網際網路-WuYue