
【演算法】分支界限法
阿新 • • 發佈:2021-02-24
前面我們介紹了一下回溯法的使用。
現在我們來給大家介紹一下它的好朋友——分支界限法。
如果說回溯法是使用深度優先遍歷演算法,那麼分支界限法就是使用廣度優先遍歷演算法。
深度優先遍歷可以只使用一個屬性來存放當前狀態,但是廣度優先遍歷就不可以了,所以廣度優先遍歷的節點必須用來儲存當前狀態,一個節點代表一個當前狀態,而一條邊就代表了一次操作,A狀態經過一條邊(操作)變為B狀態。
我在寫這篇文章的時候搜遍了網上各種各樣的分支界限法來解決01揹包問題,看各個程式碼都要一兩百行,都是優化之後的最優化版分支界限法,這樣是不利於新手進行理解的,所以我在此寫了一個最初級的分支界限法解決01揹包問題,可以看到要不了50行就能解決01揹包問題。
# 分支界限法
對於分支界限法,網上有很多種解釋,這裡我依照自己的(死宅)觀點做了以下兩種通俗易懂的解釋:
- **正經版解釋:**所謂“分支”就是採用廣度優先的策略,依次搜尋E-結點的所有分支,也就是所有相鄰結點,拋棄不滿足約束條件的結點,其餘結點加入活結點表。然後從表中選擇一個結點作為下一個E-結點,繼續搜尋。
- **動漫版解釋:**看過火影忍者的都知道,主角擁有影分身的能力,如果主角使用影分身從一個點出發,前往不同的分支,主角的運動速度相同的情況下,同一時刻時分支的深度也應該相同,有的分身走到死路,有的分身達到界限無法進行下去,當分身無法進行下去時,那麼就解除該分身,直接放棄掉這個分身,當然,肯定也會有分身成功到達目的地找到最優解,這與我們今天要講的分支界限法極其相似。
> **PS:**雛田黨大獲全勝!
---
- **總結版解釋:**從眾多分支的路徑中,同時地毯式搜尋找到**符合結果的**路徑或路徑集。
## 概念
> **分支界限演算法:**是類似於廣度優先的搜尋過程,也就是地毯式搜尋,主要是在搜尋過程中尋找問題的解,當發現已不滿足求解條件時,就捨棄該分身,不管了。
它是一種選優搜尋法,按選優條件向前廣度優先搜尋,以達到目標。但當探索到某一步時,發現原先選擇並不優或達不到目標,就放棄該分身,不進行下一步退回,這種走不通就放棄分身的技術稱為**分支界限法**。
所謂“分支”就是採用廣度優先的策略,依次搜尋E-結點的所有分支,也就是所有相鄰結點,拋棄不滿足約束條件的結點,其餘結點加入活結點表。然後從表中選擇一個結點作為下一個E-結點,繼續搜尋。
選擇下一個E-結點的方式不同,則會有幾種不同的分支搜尋方式。不用感到恐慌,其實這幾種不同的搜尋方式很好實現,只需要換一下不同的資料結構容器即可。
1. FIFO搜尋(使用**佇列**實現):按照先進先出原則選取下一個節點為擴充套件節點。 活結點表是先進先出佇列。
2. LIFO搜尋(使用**棧**實現):活結點表是堆疊。
3. 優先佇列式搜尋(使用**優先佇列**實現):按照優先佇列中規定的優先順序選取優先順序最高的節點成為當前擴充套件節點。 活結點表是優先權佇列,LC分支限界法將選取具有最高優先順序的活結點出佇列,成為新的E-結點。
> Java中的優先佇列PriorityQueue對元素採用的是堆排序,頭是按指定排序方式的最小元素。堆排序只能保證根是最大(最小),整個堆並不是有序的。
優先佇列PriorityQueue是Queue介面的實現,可以對其中元素進行排序,可以放基本的包裝型別或自定義的類,對於基本型別的包裝類,優先佇列中元素的預設排列順序是升序,但是對於自定義類來說,需要自定義比較類
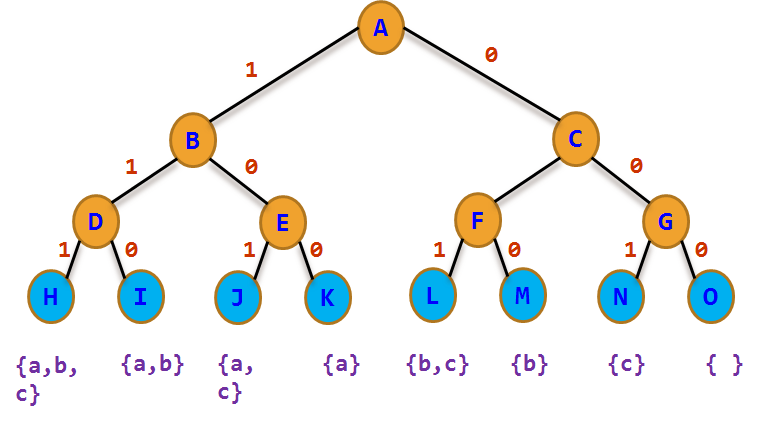
上圖為01揹包問題的解空間樹,**如果當前點不符合要求就放棄,直接剪枝**。
在許多能使用回溯法的問題時,都可以使用分支界限法,算是給讀者一個新的思路去解決問題。
## 基本思想
在包含問題的所有解的解空間樹中,按照**廣度優先搜尋**的策略,從根結點出發廣度地毯式探索解空間樹。對於不同的分支搜尋方式要使用不同的資料結構來實現。
當探索到某一結點時,要先判斷該結點是否包含問題的解:
- 如果**包含**,就將該結點的延伸結點加入佇列,以便之後遍歷;
- 如果該結點**不包含**問題的解,則直接剪枝放棄該結點的延伸結點。(其實分子界限法就是對隱式圖的廣度優先搜尋演算法)
---
**結束條件:**
- 若用分子界限法求問題的**所有解**時,根結點的所有可行的子樹都要已被搜尋遍才結束。
- 若使用分子界限法求**任一個解**時,只要搜尋到問題的一個解就可以結束。
## 適用場景
分支界限法一般使用在問題可以樹形化表示時的場景。
這樣說明的話可能有點抽象,那麼我們來換個方法說明。
當你發現,**你的問題需要用到多重迴圈,具體幾重迴圈你又沒辦法確定**,那麼就可以**使用我們的分支界限演算法來將迴圈一層一層的進行遍歷。**
就像這樣:
```
void LevelOrder(BiTree T) {
InitQueue(Q); //初始化輔助佇列
BiTNode *p;
EnQueue(Q, T); //將根結點入隊
while(!IsEmpty(Q)) { //佇列不空迴圈
DeQueue(Q, p); //隊頭元素出隊,出隊指標才是用來遍歷的遍歷指標
visit(p); //訪問當前p所指向結點
if(p->lchild != NULL) { //左子樹不空,則左子樹入佇列
EnQueue(Q, p->lchild);
}
if(p->rchild != NULL) { //右子樹不空,則右子樹入佇列
EnQueue(Q, p->rchild);
}
}
}
```
這樣層次遍歷的話,無論多少重迴圈我們都可以滿足。
## 分支界限三步走
由於上述網上的步驟太抽象了,所以在這裡我自己總結了分子界限三步走:
- **編寫檢測函式:**檢測函式用來檢測此路徑是否滿足題目條件,是否能通過。
> 這步不做硬性要求。。不一定需要
1. **建立狀態結點:**分支界限法中需要廣度優先遍歷整個分支樹,所以其結點都需要記錄下當前的狀態,否則到需要進行遍歷時我們不能得知此結點的狀態,無法進行操作。
> 與此相對的就是回溯法,回溯法由於是一條路走到底,所以並不需要使用結點記錄下當前的狀態。
> **類比:**做作業
**回溯法:**先做完數學作業再做英語作業,我們的思路是完整的,是一步一步順著來的,不會被遺忘。
**分支界限法:**做一會數學作業,再做一會英語作業,這樣我們為了保證之前做的思路不會遺忘,我們要使用結點記錄下當前的狀態。
2. **明確所有分支(選擇)**:這個構思路徑最好用**樹形圖**表示。
> **例如:**走迷宮有上下左右四個方向,也就是說我們站在一個點處有四種選擇,我們可以畫成無限向下延伸的四叉樹。
直到向下延伸到葉子節點,那裡便是出口;
從根節點到葉子節點沿途所經過的節點就是我們滿足題目條件的選擇。
3. **尋找界限條件:**每一個分支都需要進行判斷,判斷是否到達了界限,如果到達界限那麼我們就無需再進行下去了,直接剪枝放棄該分支。
> 比如說,01揹包中的界限條件就是,在將物品放置進揹包前,要進行判斷放入揹包是否會造成超重,如果不超重,那就可以放入揹包。
### 編寫檢測函式(非必須)
> **第一步**,寫出檢測函式,來檢測這個路徑是否滿足條件,是否能通過。
這個函式依據題目要求來編寫,當然,如果要求不止一個,可能需要編寫多個檢測函式。
### 建立狀態結點
分支界限法中需要廣度優先遍歷整個分支樹,所以其結點都需要記錄下當前的狀態,否則到需要進行遍歷時我們不能得知此結點的狀態,無法進行操作。
> 與此相對的就是回溯法,回溯法由於是一條路走到底,所以並不需要使用結點記錄下當前的狀態。
> **類比:**做作業
**回溯法:**先做完數學作業再做英語作業,我們的思路是完整的,是一步一步順著來的,不會被遺忘。
**分支界限法:**做一會數學作業,再做一會英語作業,這樣我們為了保證之前做的思路不會遺忘,我們要使用結點記錄下當前的狀態。
在01揹包問題中,我們需要記錄的狀態是此時揹包內物品的重量與價值。所以我們的狀態結點為:
```
/**
* 結點類,一個結點物件對應著一個當前的揹包狀態
*/
class Node {
public int weight; // 結點所相應的重量
public int value; // 結點所對應的價值
public Node() {
}
public Node(int weight, int value) {
this.weight = weight;
this.value = value;
}
}
```
### 明確所有分支
這個構思路徑最好用**樹形圖**表示。
> **例如:**走迷宮有上下左右四個方向,也就是說我們站在一個點處有四種選擇,我們可以畫成無限向下延伸的四叉樹。
直到向下延伸到葉子節點,那裡便是出口;
從根節點到葉子節點沿途所經過的節點就是我們滿足題目條件的選擇。
**第三步**,要知道這個結點有幾個選擇,即 幾叉樹。
在01揹包問題中,每個物品都有2個選擇,0不放入揹包,1放入揹包,兩條路,二叉樹。
1. 不放入揹包
2. 放入揹包
### 尋找界限條件
每一個分支都需要進行判斷,判斷是否到達了界限,如果到達界限那麼我們就無需再進行下去了,直接剪枝放棄該分支。
> 比如說,01揹包中的界限條件就是,在將物品放置進揹包前,要進行判斷放入揹包是否會造成超重,如果不超重,那就可以放入揹包。
前面我們確定了一個結點有兩條分支,一個是不裝入揹包,一個是裝入揹包。我們現在需要為每個分支尋找它們的界限條件。
不裝入揹包當然沒有什麼界限條件,而裝入揹包則需要判斷,如果放入揹包是否會造成超重,如果不超重,那就可以放入揹包。
程式碼如下:
```
// 不放此p號物品的狀態
queue.add(new Node(nowBagNode.weight, nowBagNode.value));
// 放置此p號物品的狀態
if (nowBagNode.weight + weights[p] < maxWeight) {
nowBagNode.weight += weights[p];
nowBagNode.value += values[p];
p++;
queue.add(new Node(nowBagNode.weight, nowBagNode.value));
maxValue = nowBagNode.value > maxValue? nowBagNode.value : maxValue;
}
```
完整的程式碼我放在下面的例項中了。
# 例項
## 01揹包問題
假定有N=4件商品,分別用A、B、C、D表示。每件商品的重量分別為3kg、2kg、5kg和4kg,對應的價值分別為66元、40元、95元和40元。現有一個揹包,可以容納的總重量位9kg,問:如何挑選商品,使得揹包裡商品的總價值最大?
22、20、19、10
**答案:**
暴力破解法:

由於暴力破解法不是我們本章的重點,所以程式碼再此掠過,只留下示意圖
我在寫這篇文章的時候搜遍了網上各種各樣的分支界限法來解決01揹包問題,看各個程式碼都要一兩百行,都是優化之後的最優化版分支界限法,這樣是不利於新手進行理解的,所以我在此寫了一個最初級的分支界限法解決01揹包問題,可以看到要不了50行就能解決01揹包問題。
```
/**
* 結點類,一個結點物件對應著一個當前的揹包狀態
*/
class Node {
public int weight; // 結點所相應的重量
public int value; // 結點所對應的價值
public Node() {
}
public Node(int weight, int value) {
this.weight = weight;
this.value = value;
}
}
public class Bag01 {
public int maxWeight = 9; // 揹包的最大容量
public int maxValue = 0; // 揹包內的最大價值總和
/**
* 分支界限法
* @param weights 所有物品的重量陣列
* @param values 所有物品的價值陣列
*/
public void f(int[] weights, int[] values) {
Queue queue = new ArrayDeque<>();
Node node = new Node();
// 放入一個初始結點,結點狀態均為0
queue.add(node);
int p = 0; // 物品指標位置
while (!queue.isEmpty()) {
// 取出當前結點的揹包狀態
Node nowBagNode = queue.remove();
// 如果物品沒有放完
if (p < weights.length) {
// 不放此p號物品的狀態
queue.add(new Node(nowBagNode.weight, nowBagNode.value));
// 放置此p號物品的狀態,如果放入超重了,那就不能放
if (nowBagNode.weight + weights[p] < maxWeight) {
nowBagNode.weight += weights[p];
nowBagNode.value += values[p];
p++;
queue.add(new Node(nowBagNode.weight, nowBagNode.value));
maxValue = nowBagNode.value > maxValue? nowBagNode.value : maxValue;
}
}
}
System.out.println(maxValue);
}
public static void main(String[] args) {
int[] weights = {2, 3, 5, 4};
int[] values = {66, 40, 95, 40};
Bag01 bag01 = new Bag01();
bag01.f(weights, values);
}
}
```
**程式執行結果:**
```
161
```
-------------------
如果你想換一種搜尋方式,那麼你可以把上面的佇列換成堆疊或者優先佇列試試。
# 優化
我還想看一下他們的程式碼,寫一個優化版本。
## 上界估算優化
這裡我們的上界估算是結合貪心演算法的優先佇列(剪枝)
這裡我們還是拿01揹包問題來舉例子。
需要注意的是,這裡的優先佇列是一個人為的概念,你也可以指定屬於自己的優先順序排列方式,只要言之有理,能讓速度加快即可。
結合貪心演算法,這裡我們假設能夠只拿物品的一部分把揹包塞滿,每次從佇列中取出上限值最大的一個結點(即 從該結點出發到葉子節點在理想情況下**可能得到的**最大價值)
> 注意是“可能得到的最大價值”,真實情況下由於每件商品只能整體選擇或者不選,因此價值總和總是小於等於該最大上限值,而且隨著道路的不斷前進,該最優值總是不斷減小,越來越接近真實值,當走完全程考慮完所有商品時,該最優值就變成了真實值。
也就是說,價值上限=節點現有價值+揹包剩餘容量*剩餘物品的最大單位重量價值
現在我們計算出它們的價效比,我們每次都選取單位重量下價值最大的那個物品,並且假定我們可以只選取物品的一部分。
|商品|重量|價值|價效比|
|---|---|---|---|
|A|3|66|22|
|B|2|40|20|
|C|5|95|19|
|D|4|40|10|
價效比:A>B>C>D
最大上限值的計算,就拿A結點來舉例好了:
第一步:如實計算已選道路:在此道路中A是必選的
1. 選A,總重量3,總價值0+66=66
第二步:貪婪演算法計算未知道路。
我們依次選取出價效比最高的物品:
1. 選A+B,總重量5,總價值66+40=106
2. 選A+B+部分C,總重量9,106+4*19=182
所以A結點的上限為182。
遍歷方法:
我們每次都從優先佇列中取出上限值最大的一個結點,依次加入該結點的子節點進行遍歷,直到彈出的上限值(即 最大最優價值)為某一葉子節點(即 結果),此葉子節點即為獲得揹包最大價值的最優組合方式,因為它比其他道路最優的情況還要好,那麼它一定大於其他道路的真實價值。
物品類:
```
public class Knapsack implements Comparable {
/*物品重量*/
private int weight;
/*物品價值*/
private int value;
/*單位重量價值*/
private int unitValue;
public Knapsack(int weight, int value){
this.weight = weight;
this.value = value;
this.unitValue = (weight == 0) ? 0 : value/weight;
}
public int getWeight(){
return weight;
}
public void setWeight(int weight){
this.weight = weight;
}
public int getValue(){
return value;
}
public void setValue(int value){
this.value = value;
}
public int getUnitValue(){
return unitValue;
}
@Override
public int compareTo(Knapsack snapsack) {
int value = snapsack.unitValue;
if (unitValue > value)
return 1;
if (unitValue < value)
return -1;
return 0;
}
}
```
當前狀態結點:
```
/*當前操作的節點,放入物品或不放入物品*/
class Node {
/*當前放入物品的重量*/
private int currWeight;
/*當前放入物品的價值*/
private int currValue;
/*不放入當前物品可能得到的價值上限*/
private int upperLimit;
/*當前操作物品的索引*/
private int index;
public Node(int currWeight, int currValue, int index) {
this.currWeight = currWeight;
this.currValue = currValue;
this.index = index;
}
}
```
實現:
```
public class ZeroAndOnePackage {
/*物品陣列*/
private Knapsack[] knapsacks;
/*揹包承重量*/
private int totalWeight;
/*物品數*/
private int num;
/*可以獲得的最大價值*/
private int bestValue;
public ZeroAndOnePackage(Knapsack[] knapsacks, int totalWeight) {
super();
this.knapsacks = knapsacks;
this.totalWeight = totalWeight;
this.num = knapsacks.length;
/*物品依據單位重量價值進行排序*/
Arrays.sort(knapsacks, Collections.reverseOrder());
}
public int getBestValue() {
return bestValue;
}
/*價值上限=節點現有價值+揹包剩餘容量*剩餘物品的最大單位重量價值
*當物品由單位重量的價值從大到小排列時,計算出的價值上限大於所有物
*品的總重量,否則小於物品的總重量當放入揹包的物品越來越來越多時,
*價值上限也越來越接近物品的真實總價值
*/
private int getPutValue(Node node) {
/*獲取揹包剩餘容量*/
int surplusWeight = totalWeight - node.currWeight;
int value = node.currValue;
int i = node.index;
while (i < this.num && knapsacks[i].getWeight() <= surplusWeight) {
surplusWeight -= knapsacks[i].getWeight();
value += knapsacks[i].getValue();
i++;
}
/*當物品超重無法放入揹包中時,可以通過揹包剩餘容量*下個物品單位重量的價值計算出物品的價值上限*/
if (i < this.num) {
value += knapsacks[i].getUnitValue() * surplusWeight;
}
return value;
}
public void findMaxValue() {
LinkedList nodeList = new LinkedList();
/*起始節點當前重量和當前價值均為0*/
nodeList.add(new Node(0, 0, 0));
while (!nodeList.isEmpty()) {
/*取出放入佇列中的第一個節點*/
Node node = nodeList.pop();
// 如果當前結點的上限大於等於最大價值並且結點索引小於物品總數,那就可以進行操作
// 否則,沒啥操作的必要,上限都沒當前最大價值大,何必操作呢
if (node.upperLimit >= bestValue && node.index < num) {
/*左節點:該節點代表物品放入揹包中,上個節點的價值+本次物品的價值為當前價值*/
int leftWeight = node.currWeight + knapsacks[node.index].getWeight();
int leftValue = node.currValue + knapsacks[node.index].getValue();
Node left = new Node(leftWeight, leftValue, node.index + 1);
/*放入當前物品後可以獲得的價值上限*/
left.upperLimit = getPutValue(left);
/*當物品放入揹包中左節點的判斷條件為保證不超過揹包的總承重*/
if (left.currWeight <= totalWeight && left.upperLimit > bestValue) {
/*將左節點新增到佇列中*/
nodeList.add(left);
if (left.currValue > bestValue) {
/*物品放入揹包不超重,且當前價值更大,則當前價值為最大價值*/
bestValue = left.currValue;
}
}
/*右節點:該節點表示物品不放入揹包中,上個節點的價值為當前價值*/
Node right = new Node(node.currWeight, node.currValue,node.index + 1);
/*不放入當前物品後可以獲得的價值上限*/
right.upperLimit = getPutValue(right);
if (right.upperLimit >= bestValue) {
/*將右節點新增到佇列中*/
nodeList.add(right);
}
}
}
}
public static void main(String[] args) {
Knapsack[] knapsack = new Knapsack[] {
new Knapsack(2, 13),new Knapsack(1, 10), new Knapsack(3, 24), new Knapsack(2, 15),
new Knapsack(4, 28), new Knapsack(5, 33), new Knapsack(3, 20),new Knapsack(1, 8)};
int totalWeight = 12;
ZeroAndOnePackage zeroAndOnePackage = new ZeroAndOnePackage(knapsack, totalWeight);
zeroAndOnePackage.findMaxValue();
System.out.println("最大價值為:"+zeroAndOnePackage.getBestValue());
}
}
```
# 優化理論
## 1. 問題描述
設有n個物體和一個揹包,物體i的重量為wi價值為pi ,揹包的載荷為M, 若將物體i(1<= i <=n)裝入揹包,則有價值為pi . 目標是找到一個方案, 使得能放入揹包的物體總價值最高.
設N=3, W=(16,15,15), P=(45,25,25), C=30(揹包容量)
## 2. 佇列式分支限界法
可以通過畫分支限界法狀態空間樹的搜尋圖來理解具體思想和流程
每一層按順序對應一個物品放入揹包(1)還是不放入揹包(0)
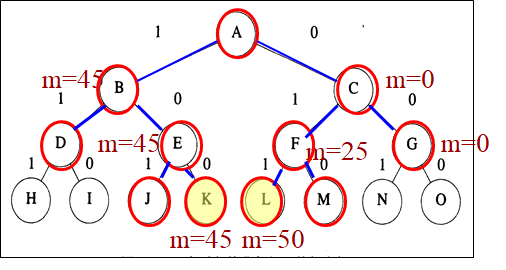
**步驟:**
1. 用一個佇列儲存活結點表,初始為空
2. A為當前擴充套件結點,其兒子結點B和C均為可行結點,將其按從左到右順序加入活結點佇列,並捨棄A。
3. 按FIFO原則,下一擴充套件結點為B,其兒子結點D不可行,捨棄;E可行,加入。捨棄B
4. C為當前擴充套件結點,兒子結點F、G均為可行結點,加入活結點表,捨棄C
5. 擴充套件結點E的兒子結點J不可行而捨棄;K為可行的葉結點,是問題的一個可行解,價值為45
6. 當前活結點佇列的隊首為F, 兒子結點L、M為可行葉結點,價值為50、25
7. G為最後一個擴充套件結點,兒子結點N、O均為可行葉結點,其價值為25和0
8. 活結點佇列為空,演算法結束,其最優值為50
>