
CNN結構演變總結(二)輕量化模型
CNN結構演變總結(一)經典模型
導言:
上一篇介紹了經典模型中的結構演變,介紹了設計原理,作用,效果等。在本文,將對輕量化模型進行總結分析。
輕量化模型主要圍繞減少計算量,減少引數,降低實際執行時間,簡化底層實現方式等這幾個方面,提出了深度可分離卷積,分組卷積,可調超引數降低空間解析度和減少通道數,新的啟用函式等方法,並針對一些現有的結構的實際執行時間作了分析,提出了一些結構設計原則,並根據這些原則來設計重新設計原結構。
注:除了以上這種直接設計輕量的、小型的網路結構的方式外,還包括使用知識蒸餾,低秩剪枝、模型壓縮等方法來獲得輕量化模型。在本文的側重點是介紹結構設計,因此對後面這幾種方法在本文不予總結,在技術總結系列文章裡後續會出一些關於模型壓縮,知識蒸餾等方面的技術總結,歡迎持續關注。在CV技術指南中回覆 “CNN模型 ”可獲取這些模型的論文及論文解讀。
Xception(2017)
Xception是基於Inception_v3上做輕量化的改進而來,可認為是extreme Inception。
創新之處有一:
1. 提出深度可分離卷積(Depthwise Separable Convolution)。
Inception_v3的結構圖如下左圖,去掉平均池化路徑後變成右圖。
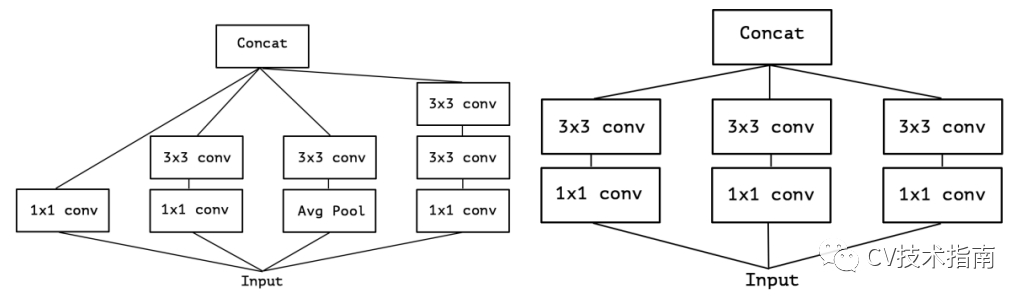

對上右圖做一個簡化,可變成如下左圖的形式。當其極端化時,就變成了如下右圖所示結構。
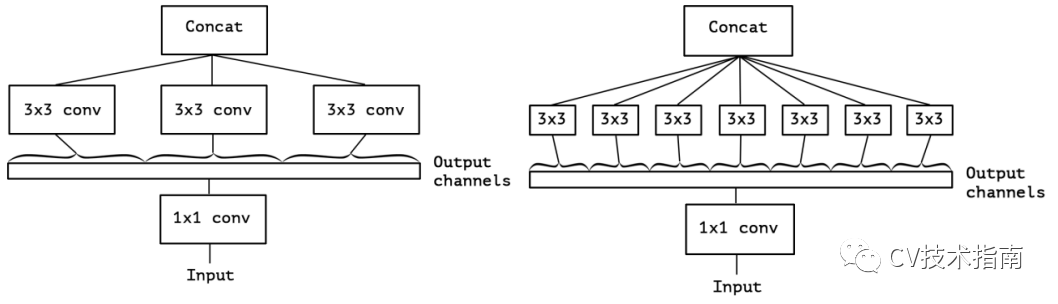
因此,當使用一個3x3卷積對應一個通道時,也就形成了extreme Inception。同時作者認為先進行3x3卷積,再進行1x1卷積不會有什麼影響。因此對extreme Inception進行映象,先進行深度卷積,再進行1x1卷積,形成了深度可分離卷積。
此外,經過實驗證明,在使用深度卷積後,不能再使用ReLU這種非線性啟用函式,轉而使用了線性啟用函式,這樣收斂速度更快,準確率更高。
MobileNet_v1(2017)
MobileNet v1 提出了一種有效的網路架構和一組兩個超引數,這些超引數允許模型構建者根據問題的約束條件為其應用選擇合適尺寸的模型,以構建非常小的,低延遲的模型,這些模型可以輕鬆地與移動和嵌入式視覺應用的設計要求匹配。
創新之處有二:
1. 提出使用深度可分離卷積構建網路,並對計算量做了分析。
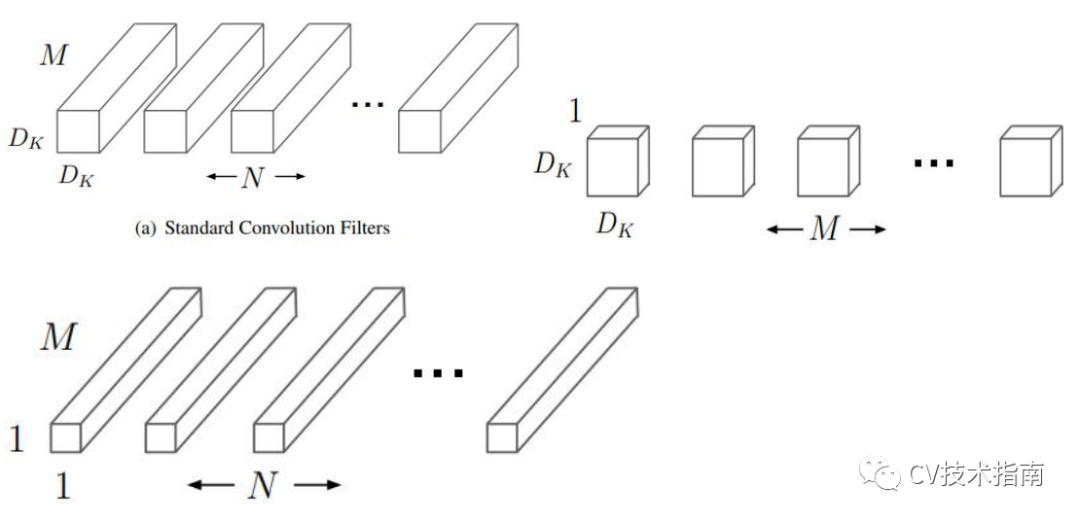
深度可分離卷積是將標準的卷積分解為深度卷積和 1x1 點卷積。深度卷積將單個濾波器應用於每個輸入通道,點卷積將深度卷積的輸出加權結合,這樣的分解效果是大大減少了計算量和模型大小。
例如,給定一個Df x Df x M 的 feature maps 生成Df x Df x N 的 feature maps,假設卷積核大小為Dk。則深度可分離卷積與標準卷積的計算量的比值為:
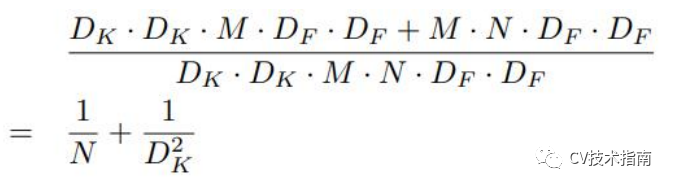
因此,當使用3x3卷積時,這種卷積方式可減少8-9倍計算量,而進度只降低了一點點。
此外,這種深度可分離卷積不只是減少了計算量這麼簡單。
對於無結構的稀疏的矩陣,其計算量雖然比密集矩陣要少,但由於密集矩陣在底層是使用了通用矩陣乘法(general matrix multiply function,即 GEMM)來進行優化(這種優化是在記憶體中通過 im2col 對卷積進行初始重新排序,再進行矩陣乘法計算),因此密集矩陣計算速度更快。
這裡深度可分離卷積中的1x1 卷積不需要進行·im2col 重排序,直接就可以使用矩陣運算,至於深度卷積部分,其引數量和計算量極少,按照正常卷積的優化計算即可。因此深度可分離卷積計算速度同樣極快。
2. 提出根據具體環境 使用超引數調整模型大小。
使用超引數alpha調整深度卷積核的個數,即在原模型的深度卷積核個數M和N的基礎上乘以縮小因子alpha。使用超引數P降低空間解析度,在原來輸入圖尺寸的基礎上乘以縮小因子P。
注:這種使用超引數的方式只降低了計算量,引數量仍然不變。
MobileNet_v2(2018)
MobileNet_v2 在輕量化結構設計方面沒有創新,但提出了一些 MobileNet_v1 存在的一些問題,並在此基礎上提出了改進方案。
創新之處有二:
1. 提出線性瓶頸(Linear Bottlenecks)
MobileNet_v2 提出 ReLU 會破壞在低維空間的資料,而高維空間影響比較少。因此,在低維空間使用 Linear activation 代替 ReLU。經過實驗表明,在低維空間使用 linear layer 是相當有用的,因為它能避免非線性破壞太多資訊。
此外,如果輸出是流形的非零空間,則使用 ReLU 相當於是做了線性變換,將無法實現空間對映,因此 MobileNet_v2 使用 ReLU6 實現非零空間的非線性啟用。
因此,其結構如下圖所示:
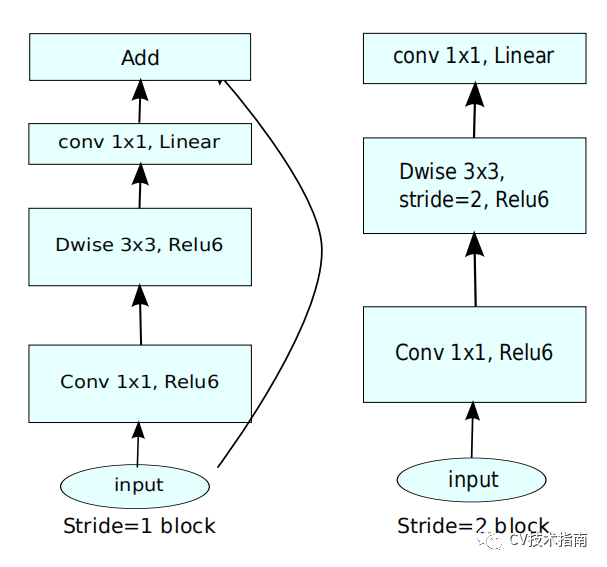
2. 提出倒殘差(Inverted Residuals)
MobileNet_v2引入了殘差連線和殘差塊,但不同的是,ResNet中的bottleneck residual是沙漏形的,即在經過1x1卷積層時降維,而MobileNet_v2中是紡錘形的,在1x1卷積層是升維。這是因為MobileNet使用了Depth wise,引數量已經極少,如果使用降維,泛化能力將不足。
ResNet中residual block是兩端大,中間小。而MobileNet_v2中是中間大,兩端小,剛好相反,作者把它取名為Inverted residual block。
其結構如下:

如上第一個圖所示,在MobileNet_v2中沒有使用池化來降維,而是使用了步長為2的卷積來實現降維,步長為2的block沒有使用shortcut connection。
MobileNet_v3(2019)
MobileNet_v3使用了NAS神經架構搜尋技術來構建網路,並提出了一些改進方案。本系列總結的側重點是結構設計的演變,因此,這裡只提結構創新之處。
創新之處有三:
1. 對於時延比較高的層進行重新設計。‘
在MobileNet_v2的Inverted bottleneck結構中使用1x1卷積作為最後一層,用於擴大到一個更高維的特徵空間,這一層對於提供豐富的特徵用於預測極為重要,但也增加了延時。
為了降低延時,並保持高維空間特徵,MobileNet_v3中把這一層移到了平均池化層的後面,在最後的特徵集現在只需要計算1x1的解析度,而不是原來的7x7。這種設計選擇的結果是,在計算和延遲方面,特性的計算變得幾乎是免費的。
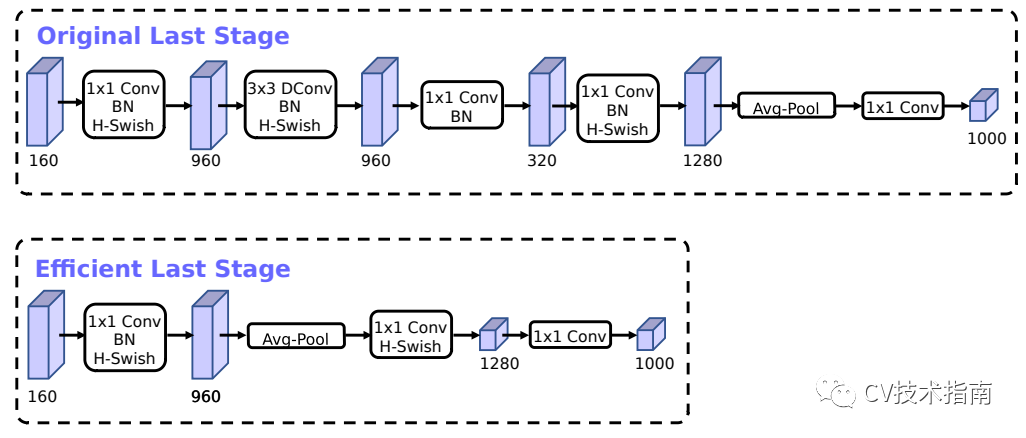
一旦降低了該特性生成層的成本,就不再需要以前的瓶頸投影層來減少計算量。該觀察允許刪除前一個瓶頸層中的投影和過濾層,從而進一步降低計算複雜度。原始階段和優化後的階段如上圖所示。
另一個耗時的層是第一層卷積,當前的移動模型傾向於在一個完整的3x3卷積中使用32個濾波器來構建初始濾波器庫進行邊緣檢測。通常這些過濾器是彼此的映象。
mobileNet_v3對這一層使h-swish非線性啟用函式,其好處是使用了h-swish後濾波器的數量可以減少到16,而同時能夠保持與使用ReLU或swish的32個濾波器相同的精度。這節省了額外的3毫秒和1000萬 MAdds。
2. 提出使用h-swish啟用函式
在一篇語義分割的論文中提出了使用swish的非線性函式來代替ReLU函式,它可以顯著提高神經網路的精度,其定義為:swish x = x · σ(x),這裡σ(x)是sigmoid函式。
然而swish雖然提高了精度,但sigmoid函式計算是極為昂貴的,在嵌入式移動端不適合它的存在,因此,MobileNet_V3提出了計算更為簡便的h-swish函式,其定義如下:
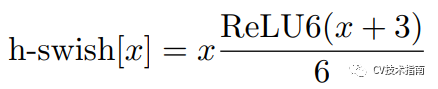
注:在較深的層次中使用更能發揮swish的大多數好處,因此在MobileNet_v3結構中,除了上面提到的第一層用h-swish以外,中高層才使用h-swish, 其它層仍然用ReLU。
3. 提出Large squeeze-and-excite
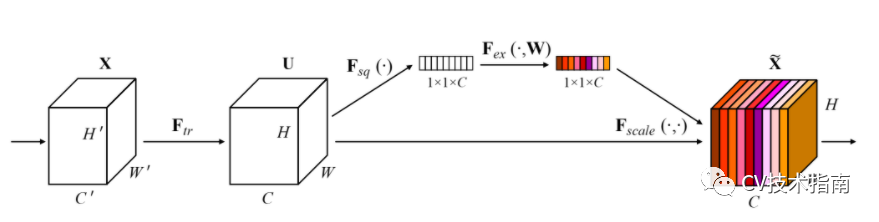
MobileNet_v3引入了在SENet中提出的SE模組,並作了一定的調整。一個是將sigmoid換成了h-swish。第二個是將第二Linear的通道數變為下一層的1/4。但這樣就沒辦法逐畫素相乘了,因為通道數不匹配,然後我去找了MobileNet_v3的程式碼,發現它在通道數變為1/4後又使用expand_as將其擴充套件成了下一層的通道數。
ShuffleNet_v1(2018)
創新之處有二:
1. 提出用於分組卷積的通道混洗。
如下圖所示,左邊是傳統卷積,右邊是分組卷積,在上一篇《CNN結構演變(一)經典模型》中提到,分組卷積的最初創意來源於AlexNet使用了兩個GPU。這樣的分組會出現一個問題,如果分組太多,將導致輸出層的每層通道都直接從上一層某一個或幾個通道卷積而來,這將會阻止通道組之間的資訊流動並削弱模型的表示能力。

解決的辦法就是讓不同組進行連線,讓不同通道組的資訊充分流動。
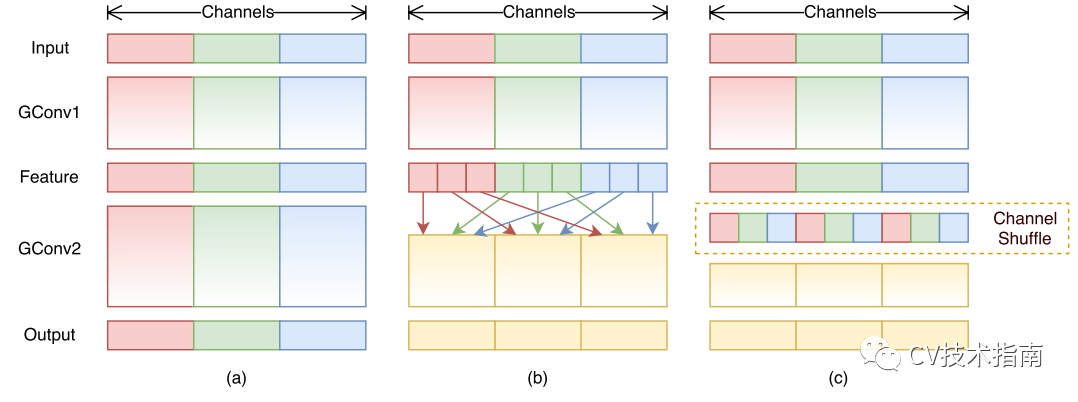
而shuffleNet中提出更好的辦法就是直接將組的順序打亂(如上圖右所示),再進行按組連線。
注:這樣打亂順序後仍然是可微的,因此這種結構可嵌入網路模型進行端到端訓練。
2. 在使用深度卷積的殘差塊(圖a)的基礎上,調整並提出ShuffleNet Unit(圖b和c)。
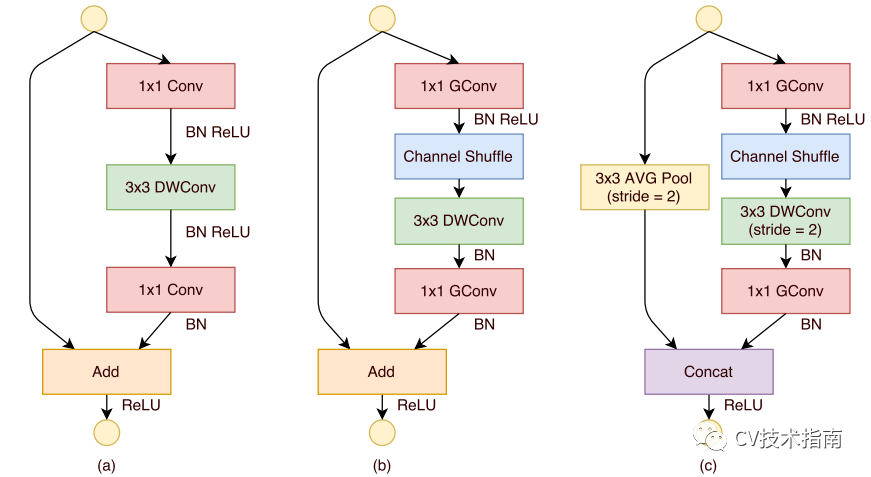
圖b為正常Unit, 圖c為降取樣Unit。
shuffleNet Unit將1x1 卷積替代為1x1分組卷積,並在shortcut path上添加了3x3平均池化,並將逐元素相加代替為通道拼接,這樣可以擴大通道數尺寸而不用增加計算成本。
此外,shuffleNet Unit取消了深度卷積後的ReLU, 最早是Xception中提出只能使用線性變換,而MobileNet_v2中解釋了在深度卷積後使用ReLU會丟失較多的資訊。因此,最終的ShuffleNet Unit如圖b和c所示。
ShuffleNet_v2(2018)
在前面介紹的幾篇輕量化模型中提出了分組卷積,深度可分離卷積等操作用來降低FLOPs,但FLOPs並不是一個直接衡量模型速度或者大小的指標,它只是通過理論上的計算量來衡量模型,然而在實際裝置上,由於各種各樣的優化計算操作,導致計算量並不能準確地衡量模型的速度。
主要原因一個是FLOPs忽略了一些重要的因素,一個是MAC (memory access cost),即記憶體訪問的時間成本。例如分組卷積,其使得底層使用的一些優化實現演算法由於分組後實現效能更低,從而導致,分組數越大,時間成本越高。另一個是並行度,同樣FLOPs下,高並行度的模型速度快於低並行度的模型。
第二個是不同平臺下,同樣的FLOPs的模型執行時間不同。例如在最新的CUDNN library中,優化實現的3x3卷積所花費的時間並沒有1x1卷積的9倍。
因此,ShuffleNet_v2提出根據實際執行時間來衡量模型速度或大小。
創新之處有二:
1. 在ShuffleNet v2進行了四項實驗,得出了一些比較耗時的操作,經過原理分析,提出了四條設計原則。
1) 卷積層輸入輸出通道數相同時,MAC最小
2) 分組卷積的分組數越大,MAC越大
3) 網路支路會降低模型的並行度
4) Element-wise操作不可忽視
注:該論文十分值得一看,可在CV技術指南的模型總結部分看到該論文的完整解讀,這裡不對這四條設計原則詳細介紹原理和細節。
2. 根據上面四條設計原則,對ShuffleNet_V1 Unit中不合理的部分進行調整,提出了新的Unit。
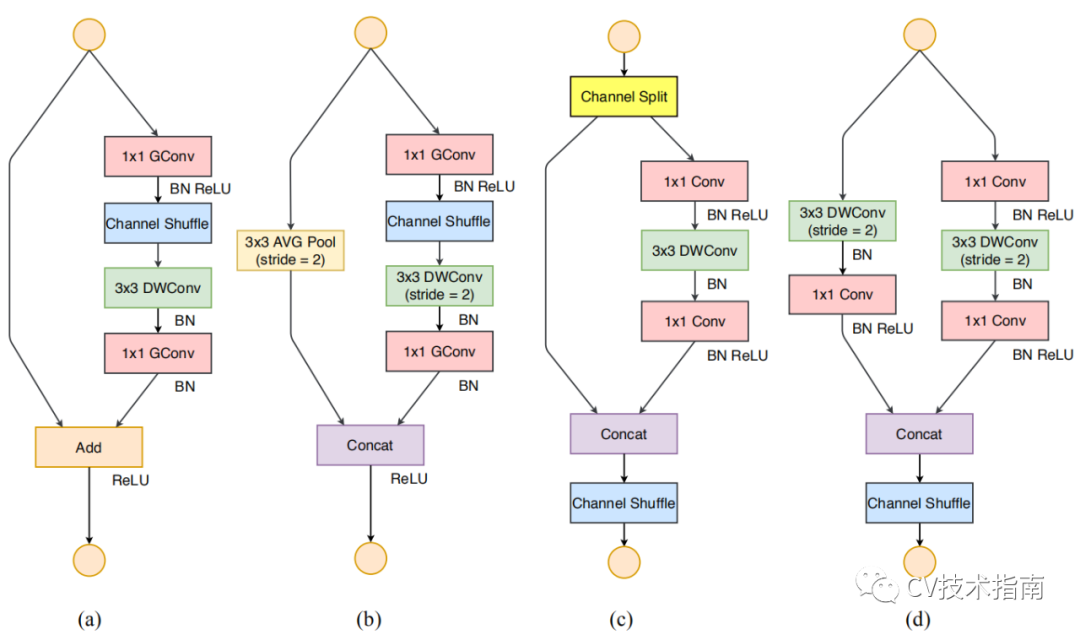
圖a為shuffleNet v1正常Unit, 圖b為shuffleNet v1降取樣Unit,圖c為shuffleNet v2 正常Unit, 圖d為shuffleNet v2 降取樣Unit.
在shuffleNet v2中引入了Channel Split, 將通道數分為c’ 和c - c’,這裡c’取c/2。一部分進行卷積操作,另一部分直接進行concat。卷積的那一路的輸入和輸出相等,這是考慮到第一條原則。
兩個1x1卷積不再進行分組,一部分原因是第二條原則,另一部分是因為Channel split就相當於是分組了。兩路進行concat後,再進行Channel Shuffle,這是為了通道上的資訊進行流動。否則,左端那路的一半通道資訊將一直進行到後面都沒有通過卷積層。
對於空間降取樣層,這個Unit是沒有Channel split,這樣可以實現在兩路concat後,通道數翻倍。其餘改動具體看圖更容易理解。
注:此處提出的Channel Split似乎是下面會提到的CSPNet中Cross Stage Partial Networks的靈感來源,且Channel Split在CSPNet中會發揮另外一種作用。這種Channel Split在每個block中,一半的通道直接進入下一個block參與下一個block,這可以認為是特徵複用(feature reuse)。
SqueezeNet(2017)
SqueezeNet基於以下三點設計理念提出了一種新的模組:
(1)大量使用1x1卷積核替換3x3卷積核,因為引數可以降低9倍;
(2)減少3x3卷積核的輸入通道數(input channels),因為卷積核引數為:(numberof input channels) * (number of filters) * 3 * 3.
(3)下采樣儘量放在網路後面,前面的layers可以有更大的特徵圖,有利於提升模型準確度。
創新之處有一:
1. 提出Fire模組。
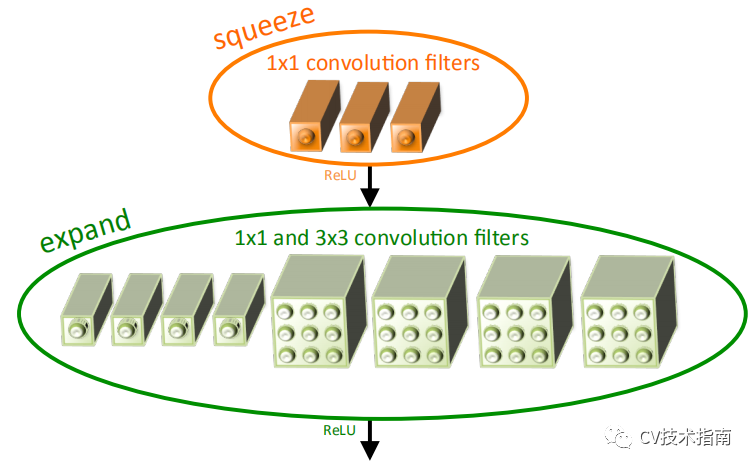
Fire模組由Squeeze layer 和Expand layer組成。
在Squeeze layer,使用1x1卷積,減少通道數;在Expand layer,使用1x1卷積和3x3卷積,1x1卷積和3x3卷積的輸出進行concate。
PELEE(2019)
PeleeNet是一種基於DenseNet改進而來的輕量化網路,主要面向移動端部署的目標檢測。
創新之處有三:
1. 提出Stem block。
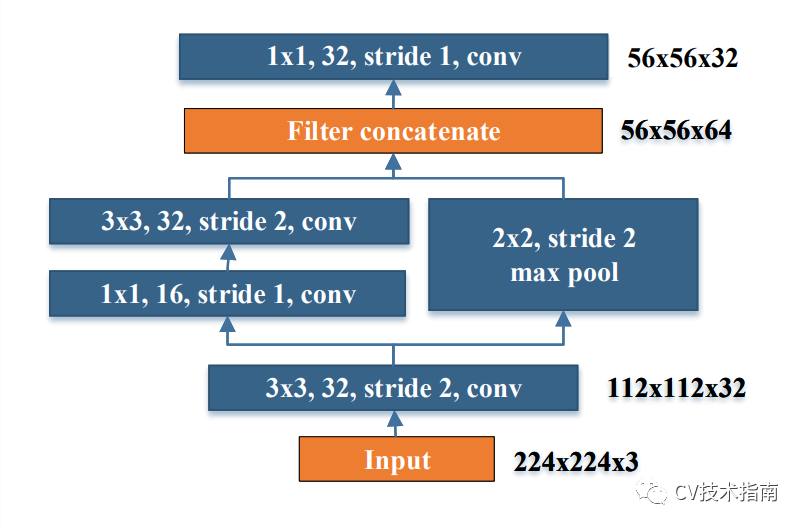
stem block可以在幾乎不增加計算量的情況下,提升特徵的表達能力。
2. 提出兩路Dense Layer。
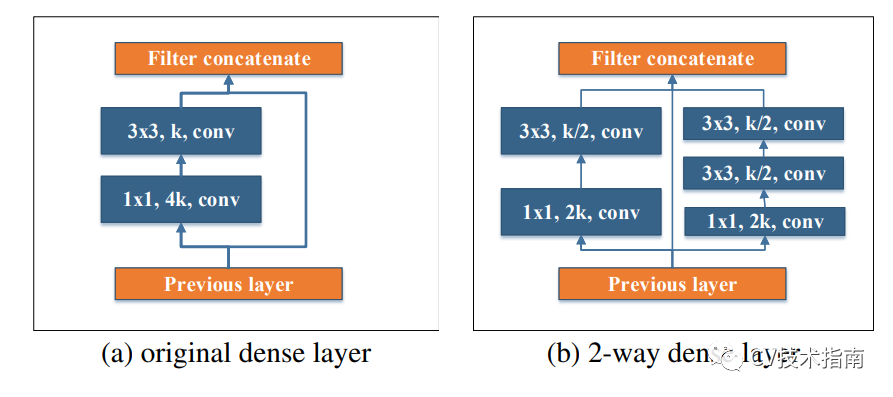
受Inception的啟發,使用了兩路dense layer, 這兩路的感受野不一樣,左邊是3x3 ,右邊是兩個3x3堆疊,感受野有5x5。
注:PELEE還包括一些其它創新點,但跟輕量化沒什麼關係,就不提了。感興趣的讀者可看原論文。在ImageNet資料集上,PeleeNet只有MobileNet模型的66%,並且比MobileNet精度更高。
CSPNet(2020)
準確來說,這篇論文並不是要提出一個輕量化模型,而是要提出一種增強CNN學習能力的backbone。之所以在這裡提這篇論文,是因為CSPNet提出了一種思想,使得網路在保持準確率的情況下,大概降低計算量20%左右。
CSPNet可與現有的一些模型(DenseNet, ResNet, ResNeXt)進行結合,YOLO_v4就是使用CSPDarknet53 作為backbone。
創新之處有一:
1. 提出Cross Stage Partial Network (CSPNet)。
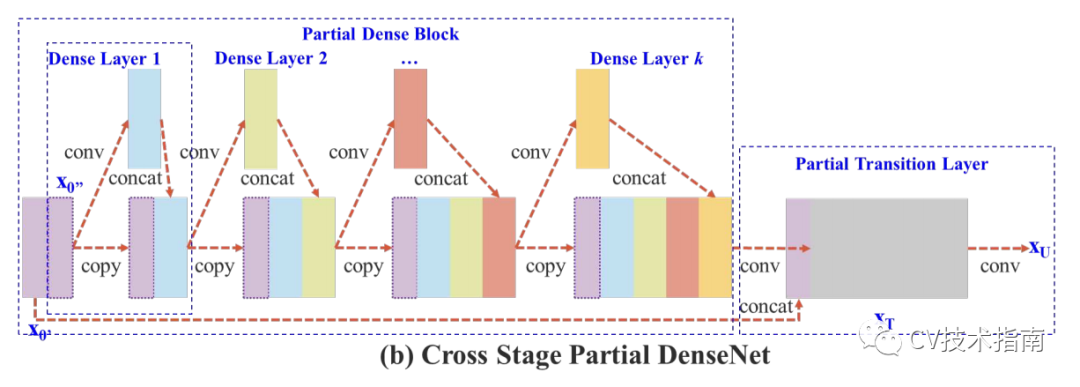
根據DenseNet中提出的基於增加資訊流動的方法,提出將一個stage前的feature maps在通道上分成兩部分,一部分經過該stage的一系列卷積,啟用等操作,另一部分直接在該stage末尾與前一部分concate,並進行transition。實驗證明通過concate和transition的梯度資訊可以具有較大的差異性。
該方法有以下優點:1.增強CNN的學習能力,2.去除計算量瓶頸,3.降低記憶體成本(20%左右)。
注:該論文還有其它創新點,這裡只提跟輕量化有關的。
下一篇將對經典模型,輕量化模型中一些結構設計的原則,作用進行總結。
參考論文
1. Xception: Deep Learning with Depthwise Separable Convolutions
2. MobileNets: Effificient Convolutional Neural Networks for Mobile Vision Applications
3. MobileNetV2: Inverted Residuals and Linear Bottlenecks
4. Searching for mobilenetv3
5. ShufflfleNet: An Extremely Effificient Convolutional Neural Network for Mobile Devices
6. ShuffleNet V2: Practical Guidelines for Effiffifficient CNN Architecture Design
7. SQUEEZENET: ALEXNET-LEVEL ACCURACY WITH 50X FEWER PARAMETERS AND <0.5MB MODEL SIZE
8. Pelee: A Real-Time Object Detection System on Mobile Devices
9. CSPNet: A New Backbone that can Enhance Learning Capability of CNN
更多技術總結內容
CNN視覺化技術總結(一)-特徵圖視覺化
CNN視覺化技術總結(二)--卷積核可視化
CNN視覺化技術總結(三)--類視覺化
CNN視覺化技術總結(四)--視覺化工具與專案
池化技術總結
NMS總結
本文來源於公眾號《CV技術指南》的技術總結部分,更多相關技術總結請掃描文末二維碼關注公眾號。
