
CNN結構演變總結(三)設計原則
CNN結構演變總結(一)經典模型
CNN結構演變總結(二)輕量化模型
前言:
前兩篇對一些經典模型和輕量化模型關於結構設計方面的一些創新進行了總結,在本文將對前面的一些結構設計的原則,作用進行總結。
本文將介紹兩種提升模型的表示能力的結構或方式,模型的五條設計原則,輕量化模型的四個設計方式。
提升模型的表示能力的結構或方式
1.“split-transform-merge”結構
這個概念來源於ResNeXt(2017年),在文中作了如下解釋。
1) Split:將向量x分成低維嵌入表示;
2) Transform:每個低維特徵經過一個線性變換;
3) Merge:通過單位加合成最後的輸出;
Inception系列就是採用了這種策略的一個結構,在Inception模組中,Split採用的是1x1降維的方式,Transform採用卷積,Merge採用Concate的方式。通過 ”split-transform-merge”這種策略,使得模型可以以較少的引數和計算量,實現更深更大模型才具備的特徵表示能力。
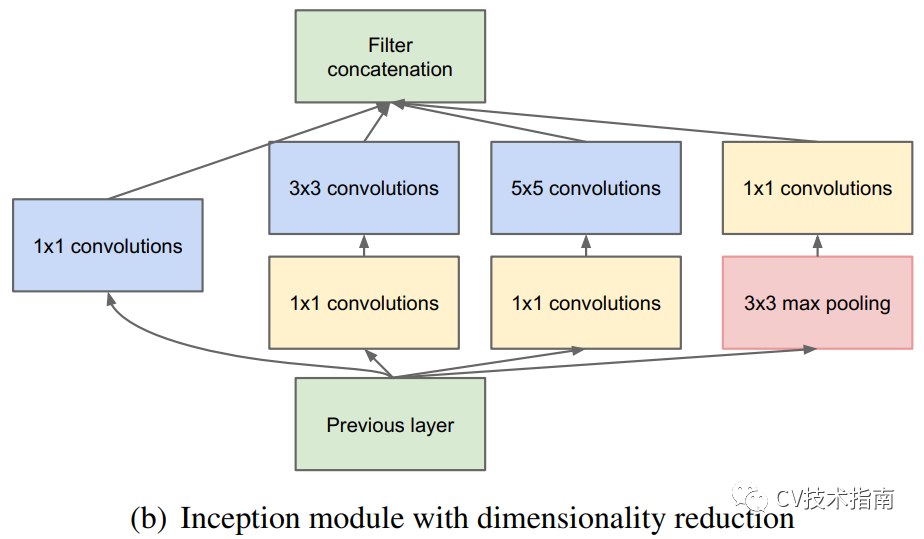

在ResNeXt中提到,基數(cardinality,也就是分支數)增多是一種比加深加寬網路更有效的方式提升精度。基於這一點,在PELEE網路中,就將DenseNet中的結構從單路變成雙路的方式來改進模型。
2. 特徵複用(feature reuse)
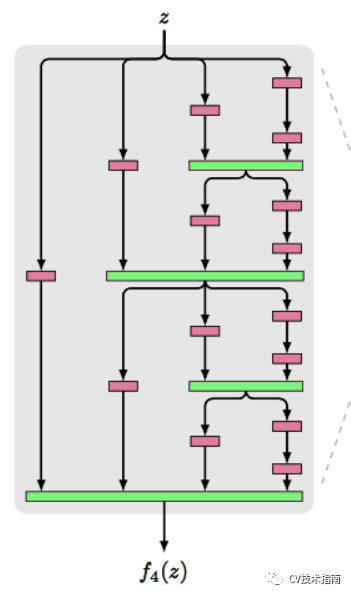
傳統的卷積網路在一個前向過程中每層只有一個連線,ResNet增加了殘差連線從而增加了資訊從一層到下一層的流動。FractalNets重複組合幾個有不同卷積塊數量的並行層序列,增加名義上的深度,卻保持著網路前向傳播短的路徑。相類似的操作還有Stochastic depth和Highway Networks,DenseNet等。
這些模型都顯示一個共有的特徵,縮短前面層與後面層的路徑,其主要的目的都是為了增加不同層之間的資訊流動,使用的方式就是特徵複用。
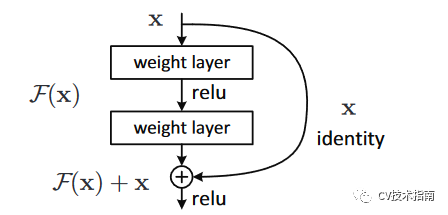
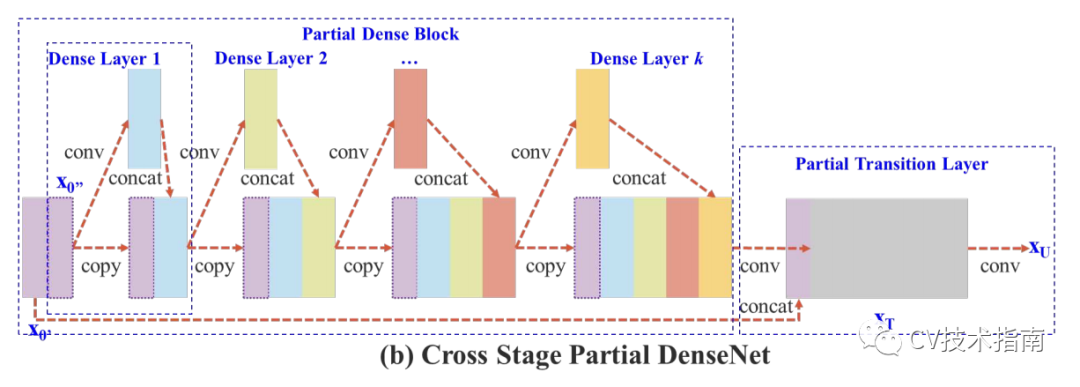
特徵複用的實現方式有以下幾種:殘差連線;feature maps留下一半進入下一層;feature maps通過不同的卷積核數量的並行層序列。
殘差連線:採用直接相加的方式。
feature maps留下一半進入下一層:CSPNet。
feature maps通過不同的卷積核數量的並行層序列:FractalNets。
模型的設計原則
在Inception系列的第三篇論文裡總結了四條CNN設計的四條原則。
1. 避免表示瓶頸,特別是在網路的淺層。
一個前向網路每層表示的尺寸應該是從輸入到輸出逐漸變小的。以下圖為例,按照左邊第一種的方式進行下采樣,將會出現表示瓶頸。為了避免這個問題,提出了第四個圖所示的結構來進行降取樣。
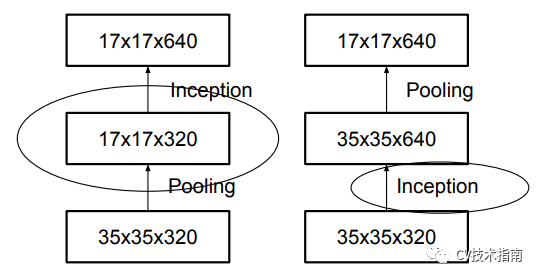
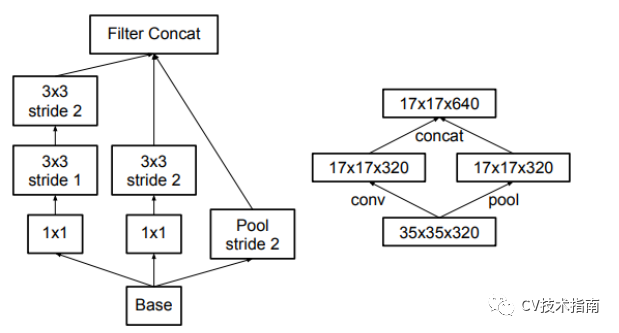
2. 高維度的表示很容易在網路中處理,增加啟用函式的次數會更容易解析特徵,也會使網路訓練的更快。
3. 可以在較低維的嵌入上進行空間聚合,而不會損失很多表示能力。
例如,在執行更分散(例如3×3)的卷積之前,可以在空間聚集之前(淺層)減小輸入表示的尺寸,而不會出現嚴重的不利影響。
我們假設這樣做的原因是,如果在空間聚合環境中(中高層)使用輸出,則相鄰單元之間的強相關性會導致在尺寸縮減期間資訊損失少得多。鑑於這些訊號應易於壓縮,因此減小尺寸甚至可以促進更快的學習。
4. 平衡網路的寬度和深度。
通過平衡每個階段的濾波器數量和網路深度,可以達到網路的最佳效能。增加網路的寬度和深度可以有助於提高網路質量。但是,如果並行增加兩者,則可以達到恆定計算量的最佳改進。因此,應在網路的深度和寬度之間以平衡的方式分配計算預算。
5. 此外再補充一條關於池化的使用。
在網路的特徵提取部分,使用最大池化。在分類部分,使用平均池化。具體原因與細節,請閱讀CV技術指南中的《池化技術總結》。
輕量化模型設計原則
1. 改進底層實現方式。
如sigmoid函式在實現過程中採用近似的方式,不僅很複雜,還會導致精度損失,因此MobileNet_v3中提出了h-swish非線性啟用函式,這個函式的特點就是底層實現很簡單,也不會導致推理階段的精度損失。
2. 減少引數量。
基於這一原則的方式目前有1)使用深度可分離卷積;2)使用分解卷積;3)使用分組卷積;4)使用特徵表示能力強的結構;5)使用1x1卷積代替3x3卷積;
3. 減少計算量。
第二條中的五種方式都具有減少計算量的作用,此外,特徵複用也具備減少計算量的作用。
4. 降低實際執行時間。
下面提到ShuffleNet_v2中的四條原則就是基於這一點。
在ShuffleNet的第二篇論文裡總結了四條實現降低模型實際執行時間的原則。
MAC: memory access cost
1. 卷積層輸入輸出通道數相同時,MAC最小。
為簡化計算表示式,這裡使用1x1卷積來進行理論上的推導。
對於空間大小為 h,w的特徵圖,輸入和輸出通道數分別為c1和c2,使用1x1卷積, 則FLOPs為B = h x w x c1 x c2。而MAC = hw(c1 + c2 ) + c1 x c2。
這裡hwc1為輸入特徵圖記憶體訪問成本,hwc2為輸出特徵圖記憶體訪問時間成本,c1xc2x1x1為卷積核記憶體訪問時間成本。
將B表示式代入MAC表示式中,並根據不等式定理,可有如下不等式:
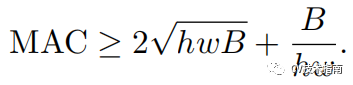
由此式可知,MAC存在下限,當c1 = c2時,MAC取最小值。
這種方式主要指模組的輸入輸出通道數相同,並非單純是一層卷積層的輸入輸出。
2. 分組卷積的分組數越大,MAC越大。
分組卷積在一方面,使得在相同FLOPs下,分組數越大,在通道上的密集卷積就會越稀疏,模型精度也會增加,在另一方面,更多的分組數導致MAC增加。
使用分組卷積的FLOPs表示式為B=h w c1 c2 /g , MAC表示式如下:
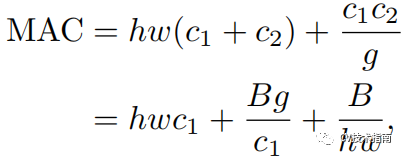
3. 網路支路會降低模型的並行度。
前面提到當網路支路數量增加時,會提高模型的特徵表示能力,但同時也降低了效率,這是因為支路對GPU並行運算來說是不友好的,此外,它還引入了額外的開銷,如核心啟動與同步。
4. Element-wise操作不可忽視。
Element-wise操作在GPU上佔的時間是相當多的。Element-wise操作有ReLU, AddTensor, AddBias等。它們都有比較小的FLOPs,卻有比較大的MAC。特別地,depthwise conv也可以認為是一個Element-wise操作,因為它有較大的MAC/FLOPs比值。
總結:《CNN結構演變總結》這個系列對目前神經網路的結構設計部分進行了比較完整的總結,但神經網路不僅僅包括結構部分,此外還包括啟用函式,訓練技巧,避免過擬合的方法,學習方式等諸多內容,在後續的總結系列文章中將會對這些內容進行總結,將放在CV技術指南的CV技術總結部分。
參考論文
第一篇忘記放參考論文,在這裡補上,再加上本文的一些參考論文。
-
Gradient-based learning applied to document recognition
-
ImageNet Classification with Deep Convolutional Neural Networks
-
Network In Network
-
Very Deep Convolutional Networks For Large-scale Image Recognition
-
Going Deeper with Convolutions
-
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
-
Rethinking the Inception Architecture for Computer Vision
-
Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
-
Deep Residual Learning for Image Recognition
-
Wide Residual Networks
-
Densely Connected Convolutional Networks
-
Training very deep networks
-
Aggregated Residual Transformations for Deep Neural Networks
-
FractalNet: Ultra-Deep Neural Networks without Residuals
更多技術總結內容
CNN視覺化技術總結(一)-特徵圖視覺化
CNN視覺化技術總結(二)--卷積核可視化
CNN視覺化技術總結(三)--類視覺化
CNN視覺化技術總結(四)--視覺化工具與專案
池化技術總結
NMS總結
本文來源於公眾號《CV技術指南》的技術總結部分,更多相關技術總結請掃描文末二維碼關注公眾號。
