
助力面試之ConcurrentHashMap面試靈魂拷問,你能扛多久
阿新 • • 發佈:2021-03-09
[TOC]
# 前言
本文從 `ConcurrentHashMap` 常見的面試問題引入話題,並逐步揭開其設計原理,相信讀完本文,對面試中的相關問題會有很大的幫助。
`HashMap` 在我們日常的開發中使用頻率最高的一個工具類之一,然而使用 `HashMap` 最大的問題之一就是它是執行緒不安全的,如果我們想要執行緒安全應該怎麼辦呢?這時候就可以選擇使用 `ConcurrentHashMap`,`ConcurrentHashMap` 和 `HashMap` 的功能是基本一樣的,`ConcurrentHashMap` 是 `HashMap` 的執行緒安全版本。
因 `ConcurrentHashMap` 和 `HashMap` 排除執行緒的安全性方面,所以有很多相同的設計思想本文不會做太多重複介紹,如果大家不瞭解 `HashMap` 底層實現原理,建議在閱讀本文可以先閱讀 [金三銀四助力面試-手把手輕鬆讀懂HashMap原始碼
](https://www.cnblogs.com/lonely-wolf/p/14412615.html) 瞭解 `HashMap` 的設計思想。
# ConcurrentHashMap 原理
`ConcurrentHashMap` 是 `HashMap` 的執行緒安全版本,其內部和 `HashMap` 一樣,也是採用了陣列 + 連結串列 + 紅黑樹的方式來實現。
如何實現執行緒的安全性?加鎖。但是這個鎖應該怎麼加呢?在 `HashTable` 中,是直接在 `put` 和 `get` 方法上加上了 `synchronized`,理論上來說 `ConcurrentHashMap` 也可以這麼做,但是這麼做鎖的粒度太大,會非常影響併發效能,所以在 `ConcurrentHashMap ` 中並沒有採用這麼直接簡單粗暴的方法,其內部採用了非常精妙的設計,大大減少了鎖的競爭,提升了併發效能。
`ConcurrentHashMap` 中的初始化和 `HashMap` 中一樣,而且容量也會調整為 2 的 N 次冪,在這裡不做重複介紹這麼做的原因。
## JDK1.8 版本 ConcurrentHashMap 做了什麼改進
在 `JDK1.7` 版本中,`ConcurrentHashMap` 由陣列 + Segment + 分段鎖實現,其內部氛圍一個個段(`Segment`)陣列,Segment`` 通過繼承 `ReentrantLock` 來進行加鎖,通過每次鎖住一個 `segment` 來降低鎖的粒度而且保證了每個 `segment` 內的操作的執行緒安全性,從而實現全域性執行緒安全。下圖就是 `JDK1.7` 版本中 `ConcurrentHashMap` 的結構示意圖:
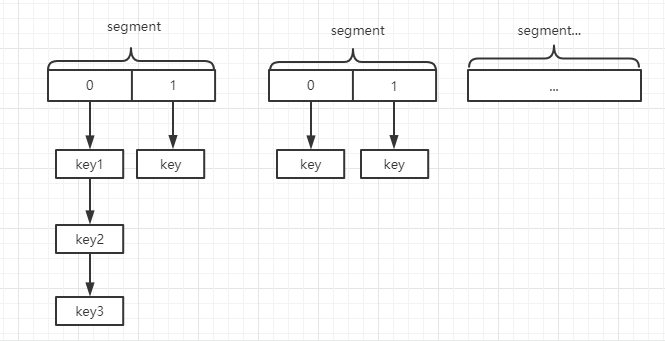
但是這麼做的缺陷就是每次通過 `hash` 確認位置時需要 `2` 次才能定位到當前 `key` 應該落在哪個槽:
1. 通過 `hash` 值和 `段陣列長度-1` 進行位運算確認當前 `key` 屬於哪個段,即確認其在 `segments` 陣列的位置。
2. 再次通過 `hash` 值和 `table` 陣列(即 `ConcurrentHashMap` 底層儲存資料的陣列)長度 - 1進行位運算確認其所在桶。
為了進一步優化效能,在 `jdk1.8` 版本中,對 `ConcurrentHashMap ` 做了優化,取消了分段鎖的設計,取而代之的是通過 `cas` 操作和 `synchronized` 關鍵字來實現優化,而擴容的時候也利用了一種分而治之的思想來提升擴容效率,在 `JDK1.8` 中 `ConcurrentHashMap` 的儲存結構和 `HashMap` 基本一致,如下圖所示:

## 為什麼 key 和 value 不允許為 null
在 `HashMap` 中,`key` 和 `value` 都是可以為 `null` 的,但是在 `ConcurrentHashMap` 中卻不允許,這是為什麼呢?
作者 `Doug Lea` 本身對這個問題有過回答,在併發程式設計中,`null` 值容易引來歧義, 假如先呼叫 `get(key)` 返回的結果是 `null`,那麼我們無法確認是因為當時這個 `key` 對應的 `value` 本身放的就是 `null`,還是說這個 `key` 值根本不存在,這會引起歧義,如果在非併發程式設計中,可以進一步通過呼叫 `containsKey` 方法來進行判斷,但是併發程式設計中無法保證兩個方法之間沒有其他執行緒來修改 `key` 值,所以就直接禁止了 `null` 值的存在。
而且作者 `Doug Lea` 本身也認為,假如允許在集合,如 `map` 和 `set` 等存在 `null` 值的話,即使在非併發集合中也有一種公開允許程式中存在錯誤的意思,這也是 `Doug Lea` 和 `Josh Bloch`(`HashMap`作者之一) 在設計問題上少數不同意見之一,而 `ConcurrentHashMap` 是 `Doug Lea` 一個人開發的,所以就直接禁止了 `null` 值的存在。
## ConcurrentHashMap 如何保證執行緒的安全性
在 `ConcurrentHashMap` 中,採用了大量的分而治之的思想來降低鎖的粒度,提升併發效能。其原始碼中大量使用了 `cas` 操作來保證安全性,而不是和 `HashTable` 一樣,不論什麼方法,直接簡單粗暴的使用 `synchronized`關鍵字來實現,接下來的原理分析中,部分和 `HashMap` 類似之處本文就不在重複,本文主要從安全性方面來分析 `ConcurrentHashMap` 的設計。
### 如何用 CAS 保證陣列初始化的安全
下面就是初始化的方法:
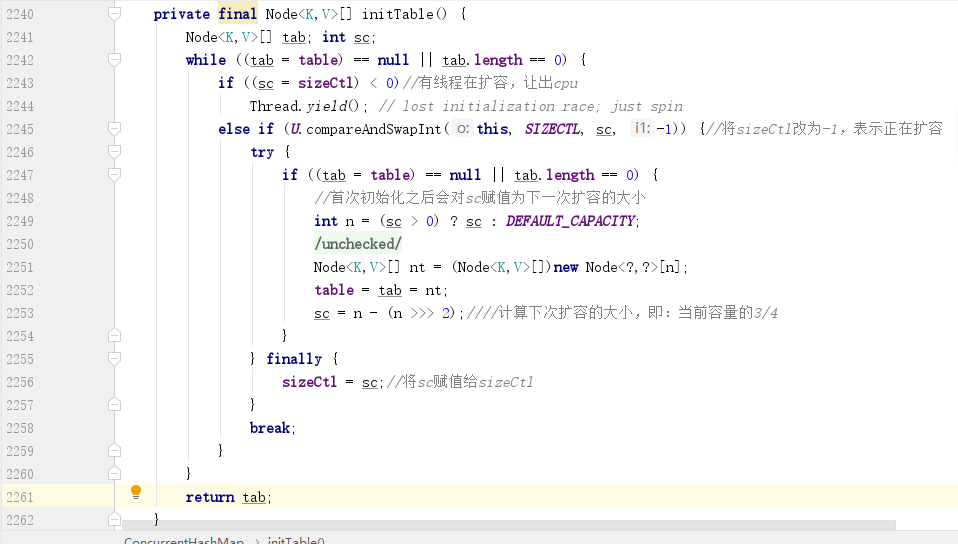
這裡面有一個非常重要的變數 `sizeCtl`,這個變數對理解整個 `ConcurrentHashMap ` 的原理非常重要。
`sizeCtl` 有四個含義:
- `sizeCtl<-1` 表示有 `N-1` 個執行緒正在執行擴容操作,如 `-2` 就表示有 `2-1` 個執行緒正在擴容。
- `sizeCtl=-1` 佔位符,表示當前正在初始化陣列。
- `sizeCtl=0` 預設狀態,表示陣列還沒有被初始化。
- `sizeCtl>0` 記錄下一次需要擴容的大小。
知道了這個變數的含義,上面的方法就好理解了,第二個分支採用了 `CAS` 操作,因為 `SIZECTL` 預設為 `0`,所以這裡如果可以替換成功,則當前執行緒可以執行初始化操作,`CAS` 失敗,說明其他執行緒搶先一步把 `sizeCtl` 改為了 `-1`。擴容成功之後會把下一次擴容的閾值賦值給 `sc`,即 `sizeClt`。
### put 操作如何保證陣列元素的可見性
`ConcurrentHashMap ` 中儲存資料採用的 `Node` 陣列是採用了 `volatile` 來修飾的,但是這隻能保證陣列的引用在不同執行緒之間是可用的,並不能保證陣列內部的元素在各個執行緒之間也是可見的,所以這裡我們判定某一個桶是否有元素,並不能直接通過下標來訪問,那麼應該如何訪問呢?原始碼給你答案:

可以看到,這裡是通過 `tabAt` 方法來獲取元素,而 `tableAt` 方法實際上就是一個 `CAS` 操作:

如果發現當前節點元素為空,也是通過 `CAS` 操作(`casTabAt`)來儲存當前元素。
如果當前節點元素不為空,則會使用 `synchronized` 關鍵字鎖住當前節點,並進行對應的設值操作:
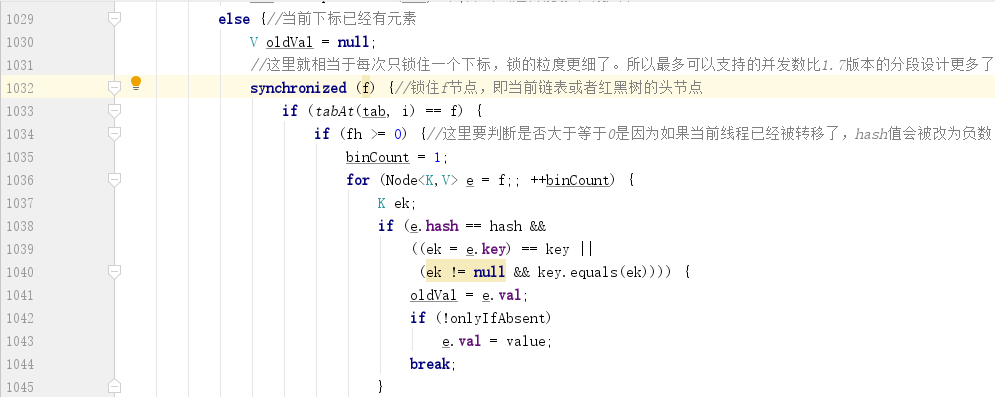
### 精妙的計數方式
在 `HashMap` 中,呼叫 `put` 方法之後會通過 `++size` 的方式來儲存當前集合中元素的個數,但是在併發模式下,這種操作是不安全的,所以不能通過這種方式,那麼是否可以通過 `CAS` 操作來修改 `size` 呢?
直接通過 `CAS` 操作來修改 `size` 是可行的,但是假如同時有非常多的執行緒要修改 `size` 操作,那麼只會有一個執行緒能夠替換成功,其他執行緒只能不斷的嘗試 `CAS`,這會影響到 `ConcurrentHashMap ` 集合的效能,所以作者就想到了一個分而治之的思想來完成計數。
作者定義了一個數組來計數,而且這個用來計數的陣列也能擴容,每次執行緒需要計數的時候,都通過隨機的方式獲取一個數組下標的位置進行操作,這樣就可以儘可能的降低了鎖的粒度,最後獲取 `size` 時,則通過遍歷陣列來實現計數:
```java
//用來計數的陣列,大小為2的N次冪,預設為2
private transient volatile CounterCell[] counterCells;
@sun.misc.Contended static final class CounterCell {//陣列中的物件
volatile long value;//儲存元素個數
CounterCell(long x) { value = x; }
}
```
#### addCount 計數方法
接下來我們看看 `addCount` 方法:

首先會判斷 `CounterCell` 陣列是不是為空,需要這裡的是,這裡的 `CAS` 操作是將 `BASECOUNT` 和 `baseCount` 進行比較,如果相等,則說明當前沒有其他執行緒過來修改 `baseCount`(即 `CAS` 操作成功),此時則不需要使用 `CounterCell` 陣列,而直接採用 `baseCount` 來計數。
假如 `CounterCell` 為空且 `CAS` 失敗,那麼就會通過呼叫 `fullAddCount` 方法來對 `CounterCell` 陣列進行初始化。
#### fullAddCount 方法
這個方法也很長,看起來比較複雜,裡面包含了對 `CounterCell` 陣列的初始化和賦值等操作。
##### 初始化 CounterCell 陣列
我們先不管,直接進入出初始化的邏輯:

這裡面有一個比較重要的變數 `cellsBusy`,預設是 `0`,表示當前沒有執行緒在初始化或者擴容,所以這裡判斷如果 `cellsBusy==0`,而 `as` 其實在前面就是把全域性變數 `CounterCell` 陣列的賦值,這裡之所以再判斷一次就是再確認有沒有其他執行緒修改過全域性陣列 `CounterCell`,所以條件滿足的話就會通過 `CAS` 操作修改 `cellsBusy` 為 `1`,表示當前自己在初始化了,其他執行緒就不能同時進來初始化操作了。
最後可以看到,預設是一個長度為 `2` 的陣列,也就是採用了 `2` 個數組位置進行儲存當前 `ConcurrentHashMap` 的元素數量。
##### CounterCell 如何賦值
初始化完成之後,如果再次呼叫 `put` 方法,那麼就會進入 `fullAddCount` 方法的另一個分支:
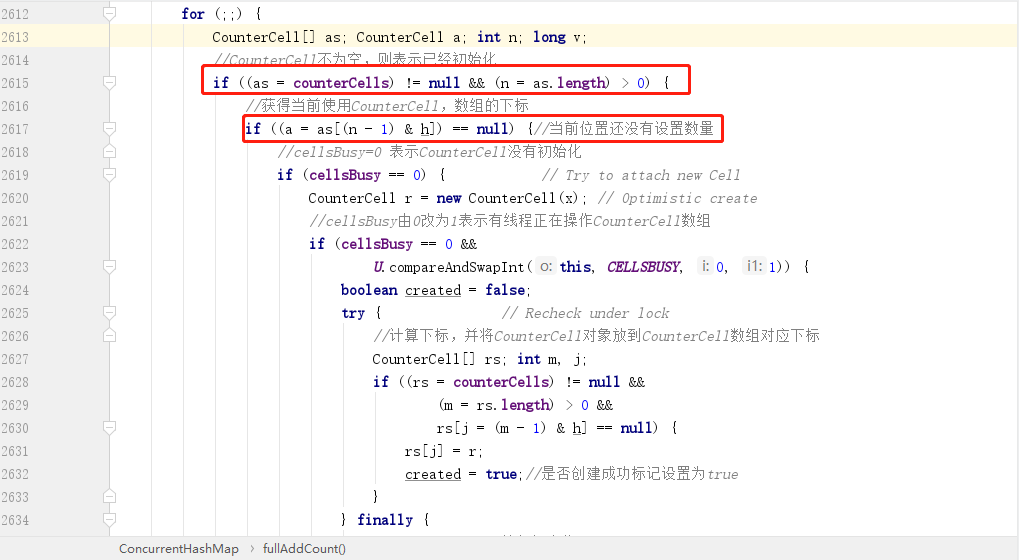
這裡面首先判斷了 `CounterCell` 陣列不為空,然後會再次判斷陣列中的元素是不是為空,因為如果元素為空,就需要初始化一個 `CounterCell` 物件放到陣列,而如果元素不為空,則只需要 `CAS` 操作替換元素中的數量即可。
所以這裡面的邏輯也很清晰,初始化 `CounterCell` 物件的時候也需要將 `cellBusy` 由 `0` 改成 `1`。
##### 技數陣列 CounterCell 也能擴容嗎
最後我們再繼續看其他分支:

主要看上圖紅框中的分支,一旦會進入這個分支,就說明前面所有分支都不滿足,即:
- 當前 `CounterCell` 陣列已經初始化完成。
- 當前通過 `hash` 計算出來的 `CounterCell` 陣列下標中的元素不為 `null`。
- 直接通過 `CAS` 操作修改 `CounterCell` 陣列中指定下標位置中物件的數量失敗,說明有其他執行緒在競爭修改同一個陣列下標中的元素。
- 當前操作不滿足不允許擴容的條件。
- 當前沒有其他執行緒建立了新的 `CounterCell` 陣列,且當前 `CounterCell` 陣列的大小仍然小於 `CPU` 數量。
所以接下來就需要對 `CounterCell` 陣列也進行擴容,這個擴容的方式和 `ConcurrentHashMap` 的擴容一樣,也是將原有容量乘以 `2`,所以其實 `CounterCell` 陣列的容量也是滿足 2 的 N 次冪。
### ConcurrentHashMap 的擴容
接下來我們需要回到 `addCount` 方法,因為這個方法在新增元素數量的同時,也會判斷當前 `ConcurrentHashMap` 的大小是否達到了擴容的閾值,如果達到,需要擴容。
#### 擴容也能支援併發嗎
這裡可能令大家有點意外的是,`ConcurrentHashMap` 擴容也支援多執行緒同時進行,這又是如何做到的呢?接下來就讓我們回到 `addCount` 方法一探究竟。
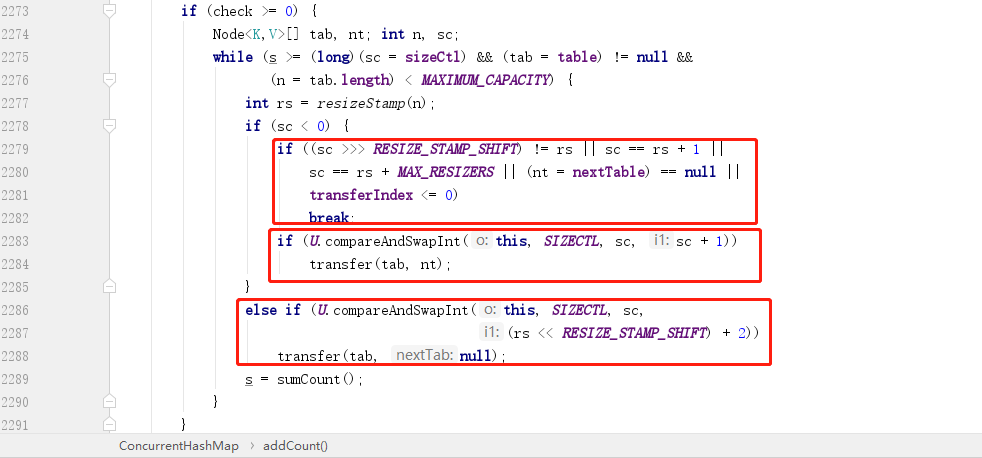
這裡 `check` 是傳進來的連結串列長度,`>=0` 才開始檢查是否需要擴容,緊挨之後是一個 `while` 迴圈,主要是滿足兩個條件:
- 前面我們提到,`sizeCtl`在初始化的時候會被賦值為下一次擴容的大小(擴容之後也會),所以 `>=sizeCtl` 表示的就是是否達到擴容閾值。
- `table` 不為 `null` 且當前陣列長度小於最大值 2 的 30 次方。
##### 擴容戳有什麼用
當滿足擴容條件之後,首先會先呼叫一個方法來獲取擴容戳,這個擴容戳比較有意思,要理解擴容戳,必須從二進位制的角度來分析。`resizeStamp` 方法就一句話,其中 `RESIZE_STAMP_BITS` 是一個預設值 `16`。
```java
static final int resizeStamp(int n) {
return Integer.numberOfLeadingZeros(n) | (1 << (RESIZE_STAMP_BITS - 1));
}
```
這裡面關鍵就是 `Integer.numberOfLeadingZeros(n)` 這個方法,這個方法原始碼就不貼出來了,實際上這個方法就是做一件事,那就是**獲取當前資料轉成二進位制後的最高非 `0` 位前的 `0` 的個數**。
這句話有點拗口,我們舉個例子,就以 `16` 為準,`16` 轉成二進位制是 `10000`,最高非 `0` 位是在第 `5` 位,因為 `int` 型別是 `32` 位,所以他前面還有 `27` 位,而且都是 `0`,那麼這個方法得到的結果就是 `27`(`1` 的前面還有 `27` 個 `0`)。
然後 `1 << (RESIZE_STAMP_BITS - 1)` 在當前版本就是 `1<<15`,也就是得到一個二進位制數 `1000000000000000`,這裡也是要做一件事,把這個 **`1` 移動到第 `16` 位**。最後這兩個數通過 `|` 操作一定得到的結果就是第 `16` 位是 `1`,因為 `int` 是 `32` 位,最多也就是 `32` 個 `0`,而且因為 `n` 的預設大小是 `16`(`ConcurrentHashMap` 預設大小),所以實際上最多也就是 `27`(`11011`)個 `0`,執行 `|` 運算最多也就是影響低 `5` 位的結果。
`27` 轉成二進位制為 `0000000000000000000000000011011`,然後和 `00000000000000001000000000000000` 執行 `|` 運算,最終得到的而結果就是 `00000000000000010000000000011011`,
注意:這裡之所以要保證第 `16` 位為 `1`,是為了保證 `sizeCtl` 變數為負數,因為前面我們提到,這個變數為負數才代表當前有執行緒在擴容,至於這個變數和 `sizeCtl` 的關係後面會介紹。
##### 首次擴容為什麼計數要 +2 而不是 +1
首次擴容一定不會走前面兩個條件,而是走的最後一個紅框內條件,這個條件通過 `CAS` 操作將 `rs` 左移了 `16`(RESIZE_STAMP_SHIFT)位,然後加上一個 `2`,這個代表什麼意思呢?為什麼是加 `2` 呢?
要回答這個問題我們先回答另一個問題,上面通過方法獲得的擴容戳 `rs` 究竟有什麼用?實際上這個擴容戳代表了兩個含義:
- 高 `16` 為代表當前擴容的標記,可以理解為一個紀元。
- 低 `16` 代表了擴容的執行緒數。
知道了這兩個條件就好理解了,因為 `rs` 最終是要賦值給 `sizeCtl` 的,而 `sizeCtl` 負數才代表擴容,而將 `rs` 左移 `16` 位就剛好使得最高位為 `1`,此時低 `16` 位全部是 `0`,而因為低 `16` 位要記錄擴容執行緒數,所以應該 `+1`,但是這裡是 `+2`,原因是 `sizeCtl` 中 `-1` 這個數值已經被使用了,用來代替當前有執行緒準備擴容,所以如果直接 `+1` 是會和標誌位發生衝突。
所以繼續回到上圖中的第二個紅框,就是正常繼續 `+1` 了,只有初始化第一次記錄擴容執行緒數的時候才需要 `+2`。
##### 擴容條件
接下來我們繼續看上圖中第一個紅框,這裡面有 `5` 個條件,代表是滿足這 `5` 個條件中的任意一個,則不進行擴容:
1. `(sc >>> RESIZE_STAMP_SHIFT) != rs` 這個條件實際上有 `bug`,在 `JDK12` 中已經換掉。
2. `sc == rs + 1` 表示最後一個擴容執行緒正在執行首位工作,也代表擴容即將結束。
3. `sc == rs + MAX_RESIZERS` 表示當前已經達到最大擴容執行緒數,所以不能繼續讓執行緒加入擴容。
4. 擴容完成之後會把 `nextTable`(擴容的新陣列) 設為 `null`。
5. `transferIndex <= 0` 表示當前可供擴容的下標已經全部分配完畢,也代表了當前執行緒擴容結束。
#### 多併發下如何實現擴容
在多併發下如何實現擴容才不會衝突呢?可能大家都想到了採用分而治之的思想,在 `ConcurrentHashMap` 中採用的是分段擴容法,即每個執行緒負責一段,預設最小是 `16`,也就是說如果 `ConcurrentHashMap` 中只有 `16` 個槽位,那麼就只會有一個執行緒參與擴容。如果大於 `16` 則根據當前 `CPU` 數來進行分配,最大參與擴容執行緒數不會超過 `CPU` 數。
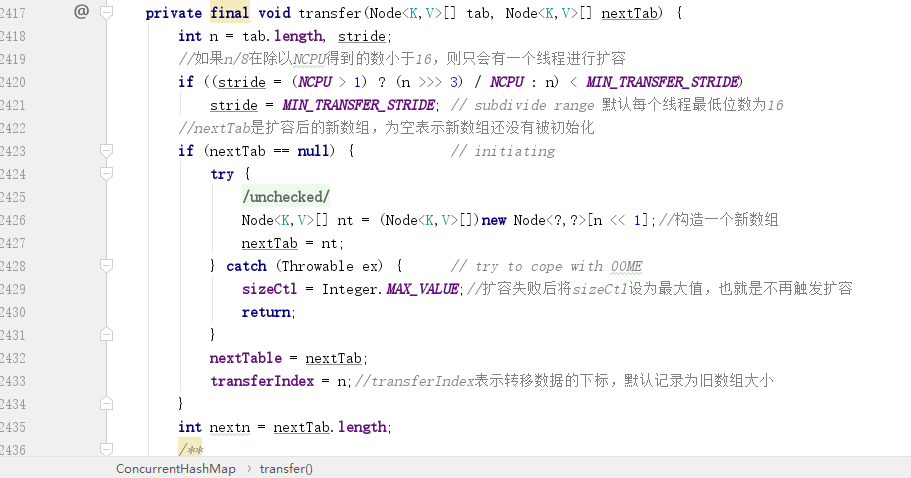
擴容空間和 `HashMap` 一樣,每次擴容都是將原空間大小左移一位,即擴大為之前的兩倍。注意這裡的 `transferIndex` 代表的就是推進下標,預設為舊陣列的大小。
#### 擴容時的資料遷移如何保證安全性
初始化好了新的陣列,接下來就是要準備確認邊界。也就是要確認當前執行緒負責的槽位,確認好之後會從大到小開始往前推進,比如執行緒一負責 `1-16`,那麼對應的陣列邊界就是 `0-15`,然後會從最後一位 `15` 開始遷移資料:
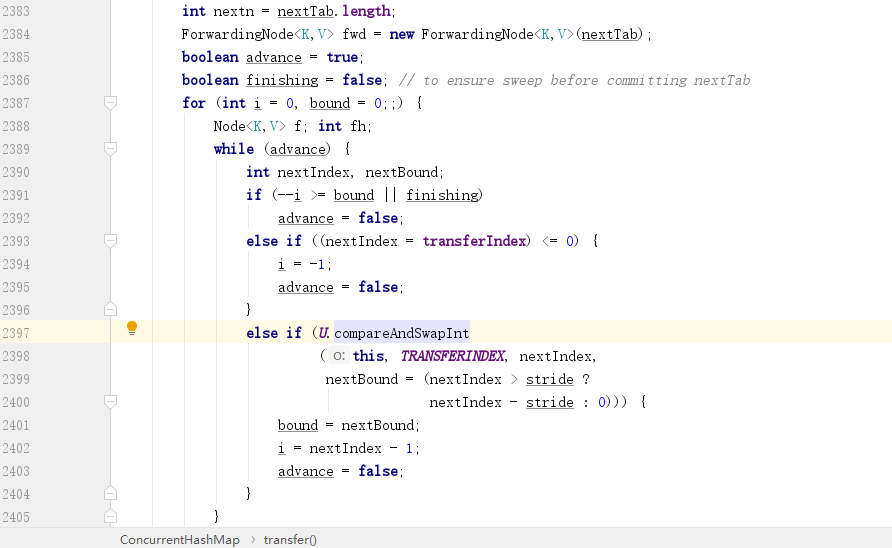
這裡面有三個變數比較關鍵:
- `fwd` 節點,這個代表的是佔位節點,最關鍵的就是這個節點的 `hash` 值為 `-1`,所以一旦發現某一個節點中的 `hash` 值為 `-1` 就可以知道當前節點已經被遷移了。
- `advance`:代表是否可以繼續推進下一個槽位,只有當前槽位資料被遷移完成之後才可以設定為 `true`
- `finishing`:是否已經完成資料遷移。
知道了這幾個變數,再看看上面的程式碼,第一次一定會進入 `while` 迴圈,因為預設 `advance` 為 `true`,第一次進入迴圈的目的為了確認邊界,因為邊界值還沒有確認,所以會直接走到最後一個分支,通過 `CAS` 操作確認邊界。
確認邊界這裡直接表述很難理解,我們通過一個例子來說明:
假設說最開始的空間為 `16`,那麼擴容後的空間就是 `32`,此時 `transferIndex` 為舊陣列大小 `16`,而在第二個 `if`判斷中,`transferIndex` 賦值給了 `nextIndex`,所以 `nextIndex` 為 `1`,而 `stride` 代表的是每個執行緒負責的槽位數,最小就是 `16`,所以 `stride` 也是 `16`,所以 `nextBound= nextIndex > stride ? nextIndex - stride : 0` 皆可以得到:`nextBound=0` 和 `i=15` 了,也就是當前執行緒負責 `0-15` 的陣列下標,且從 `0` 開始推進,確認邊界後立刻將 `advance` 設定為 `false`,也就是會跳出 `while` 迴圈,從而執行下面的資料遷移部分邏輯。
PS:因為 `nextBound=0`,所以 `CAS` 操作實際上也是把 `transferIndex` 變成了 `0`,表示當前擴容的陣列下標已經全部分配完畢,這也是前面不滿足擴容的第 `5` 個條件。
資料遷移時,會使用 `synchronized` 關鍵字對當前節點進行加鎖,也就是說鎖的粒度精確到了每一個節點,可以說大大提升了效率。加鎖之後的資料遷移和 `HashMap` 基本一致,也是通過區分高低位兩種情況來完成遷移,在本文就不重複講述。
當前節點完成資料遷移之後,`advance` 變數會被設定為 `true`,也就是說可以繼續往前推進節點了,所以會重新進入上面的 `while` 迴圈的前面兩個分支,把下標 `i` 往前推進之後再次把 `advance` 設定為 `false`,然後重複操作,直到下標推進到 `0` 完成資料遷移。
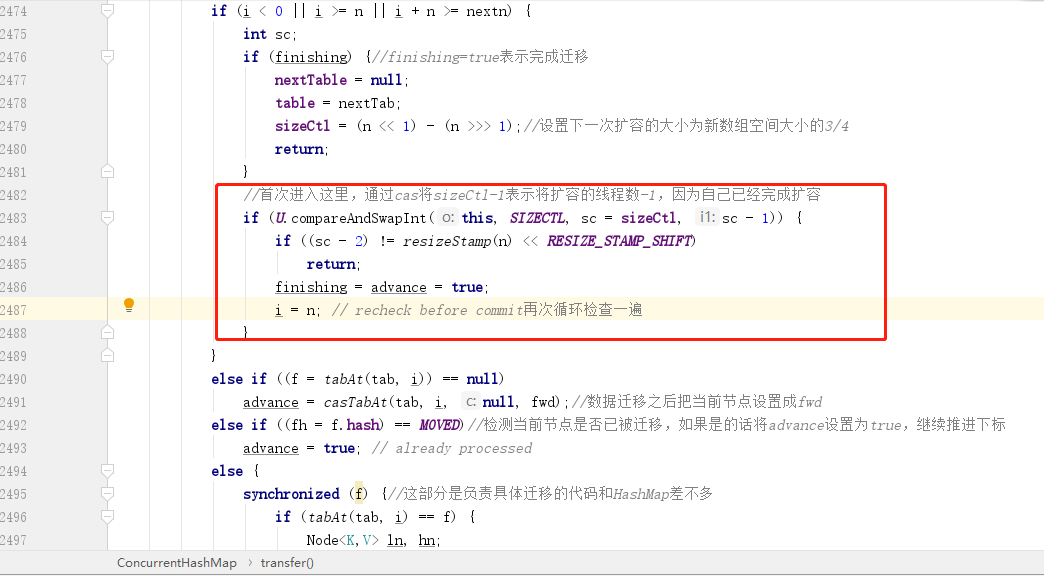
`while` 迴圈徹底結束之後,會進入到下面這個 `if` 判斷,紅框中就是當前執行緒自己完成了遷移之後,會將擴容執行緒數進行遞減,遞減之後會再次通過一個條件判斷,這個條件其實就是前面進入擴容前條件的反推,如果成立說明擴容已經完成,擴容完成之後會將 `nextTable` 設定為 `null`,所以上面不滿足擴容的第 `4` 個條件就是在這裡設定的。
# 總結
本文主要講述了 `ConcurrentHashMap` 中是如何保證安全性的,並且挑選了一些比較經典的面試常用問題進行分析解答,在整個 `ConcurrentHashMap` 中,整個思想就是降低鎖的粒度,減少鎖的競爭,所以採用了大量的分而治之的思想,比如多執行緒同時進行擴容,以及通過一個數組來實現 `size` 的計