
醫學影象配準 | Voxelmorph 微分同胚 | MICCAI2019
阿新 • • 發佈:2021-03-11
- 文章轉載:微信公眾號「機器學習煉丹術」
- 作者:煉丹兄(已授權)
- 聯絡方式:微信cyx645016617(歡迎交流)
- 論文題目:‘Unsupervised Learning for Fast Probabilistic Diffeomorphic Registration’

## 0 綜述
- 本文提出了一個概率生成模型,並給出了一種**基於無監督學習的推理演算法卷積神經網路**;
- 論文中對一個三維腦配準任務進行了驗證,並提供了一個實驗結果;
- 論文的方法在提供**微分同胚**的同時,且具有最先進的精度和非常快的執行速度。
## 1 微分同胚
> Our approach results in state of the art accuracy and very fast runtimes, while providing diffeomorphic guarantees.
這片論文提供了SOTA的配準方式,並且使用了diffeomorphic(微分同胚)。
- diffeomorphic 微分同胚
- deformation field 變形場
- ordinary differential equation (ODE) 常微分方程
- 假設兩個三維圖片滿足:$\phi = R^3 \rightarrow R^3$,表示**從一個圖片的座標到另外一個圖片的座標的變形場**;
- 這個變形場的定義為:
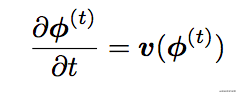
- 假設我們擁有了$t\in [0,1]$的所有靜態速度場,那麼我們就可以integrate(整合)所有的速度場,從而從$\phi^{(0)}$推斷出$\phi^{(1)}$的圖片。(也就是0時刻的位移廠推出1時刻的位移場);
關於微分同胚,經過李代數和群論的推到後的結論:

總的來說,我感覺就是**對於部分圖片變化太大,所以可能不存在靜態位移場,所以用速度場來計算位移場。而這個微分同胚的推斷,通過李代數和群論,得到的結論如下**:
$\phi^{(1)} = \phi^{(1/2)} composition \phi^{(1/2)}$
這部分我也不太能說明具體的含義,在voxelmorph的github程式碼中體現為:
```python
class VecInt(nn.Module):
"""
Integrates a vector field via scaling and squaring.
"""
def __init__(self, inshape, nsteps):
super().__init__()
assert nsteps >= 0, 'nsteps should be >= 0, found: %d' % nsteps
self.nsteps = nsteps
self.scale = 1.0 / (2 ** self.nsteps)
self.transformer = SpatialTransformer(inshape)
def forward(self, vec):
vec = vec * self.scale
for _ in range(self.nsteps):
vec = vec + self.transformer(vec, vec)
return vec
```
重點看最後一行,vec = vec + self.transformer(vec,vec),這個剛好對應上面的:
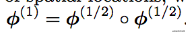
這一塊我的理解也就止步於此,進一步的可能需要李代數和群論的知識把。
## 2 模型結構
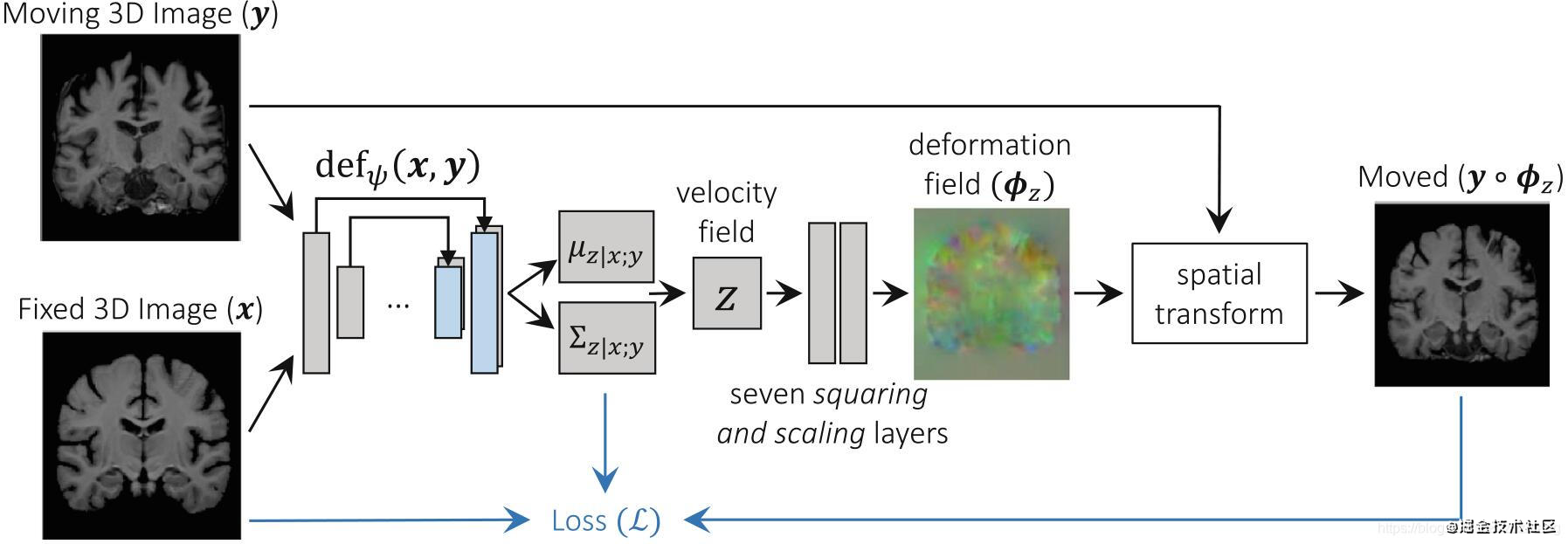
### 2.1 簡單
模型結構不復雜:
- 兩個圖片先做concatenate,然後輸入到Unet中,然後Unet輸出一個從moving到fixed圖片的速度場。
我們來看一下voxelmorph官方提供的pytorch的程式碼,我們只看voxelmorph模型的forward部分,完整程式碼連結:https://github.com/voxelmorph/voxelmorph/blob/master/voxelmorph/torch/networks.py:
我直接在程式碼中標記註釋,來學習這個模型結構的過程。
```python
def forward(self, source, target, registration=False):
'''
Parameters:
source: Source image tensor.
target: Target image tensor.
registration: Return transformed image and flow. Default is False.
'''
# 先把fixed和moving兩個圖片拼接起來,放到Unet模型中,提取中一個特徵
x = torch.cat([source, target], dim=1)
x = self.unet_model(x)
# 把特徵轉換成速度場
flow_field = self.flow(x)
# 對速度場做下采樣
pos_flow = flow_field
if self.resize:
pos_flow = self.resize(pos_flow)
preint_flow = pos_flow
# 這個是如果使用了雙向配準的話
neg_flow = -pos_flow if self.bidir else None
# 微分同胚的整合
if self.integrate:
pos_flow = self.integrate(pos_flow)
neg_flow = self.integrate(neg_flow) if self.bidir else None
# 把尺寸恢復到原來的尺寸
if self.fullsize:
pos_flow = self.fullsize(pos_flow)
neg_flow = self.fullsize(neg_flow) if self.bidir else None
# 計算這個速度場作用在moving上的結果,如果使用了雙向配準,則還需要把速度場反向作用在fixed圖片上
y_source = self.transformer(source, pos_flow)
y_target = self.transformer(target, neg_flow) if self.bidir else None
# return non-integrated flow field if training
if not registration:
return (y_source, y_target, preint_flow) if self.bidir else (y_source, preint_flow)
else:
return y_source, pos_flow
```

整個網路也不難理解,其實這個voxelmorph程式碼中已經使用了微分同胚和雙向配準的方案,目前使用變分推斷的prob-voxelmorph模型github倉庫中作者還沒有提供torch的程式碼,所以目前還沒有這個部分。

關於voxelmorph先介紹這麼多,個人的心得為:
- 微分同胚一定要有,不然很容易不收斂,建議使用預設的引數7,把一個時間間隔劃分成8份;
- 雙向配準的效果還不