
Mysql之索引選擇及優化
阿新 • • 發佈:2021-03-26
## 索引模型
- 雜湊表
- 適用於只有等值查詢的場景,Memory引擎預設索引
- InnoDB支援自適應雜湊索引,不可干預,由引擎自行決定是否建立
- 有序陣列:在等值查詢和範圍查詢場景中的效能都非常優秀,但插入和刪除資料需要進行資料移動,成本太高。因此,只適用於靜態儲存引擎
- 二叉平衡樹:每個節點的左兒子小於父節點,父節點又小於右兒子,時間複雜度是 O(log(N))
- 多叉平衡樹:索引不止存在記憶體中,還要寫到磁碟上。為了讓一個查詢儘量少地讀磁碟,就必須讓查詢過程訪問儘量少的資料塊。因此,要使用“N 叉”樹。
## B+Tree
> B-Tree 與 B+Tree
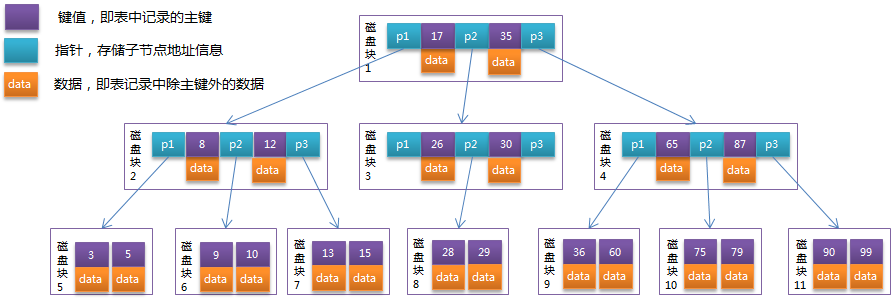
- B-Tree
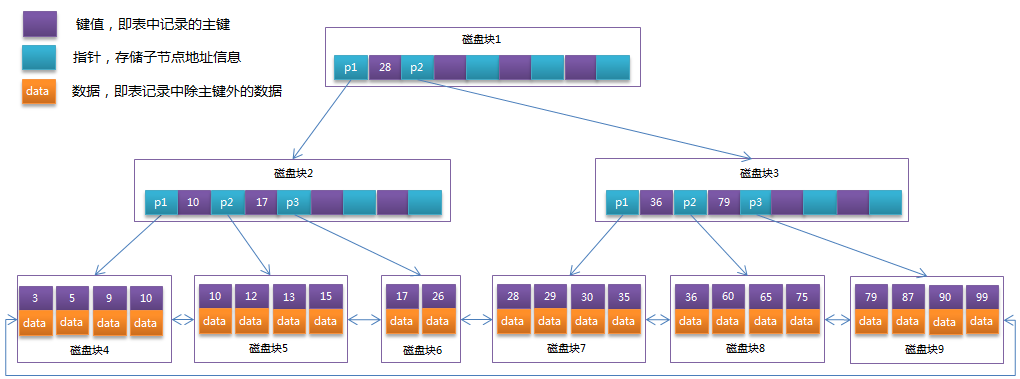
- B+Tree
InnoDB 使用了 B+ 樹索引模型。假設,我們有一個主鍵列為 ID 的表,表中有欄位 k,並且在 k 上有索引,如下所示:
 - 主鍵索引:也被稱為聚簇索引,葉子節點存的是整行資料
- 非主鍵索引:也被稱為二級索引,葉子節點內容是主鍵的值
> 注意事項
- 索引基於資料頁有序儲存,可能發生資料頁的分裂(頁儲存空間不足)和合並(資料刪除造成頁利用率低)
- 資料的無序插入會造成資料的移動,甚至資料頁的分裂
- 主鍵長度越小,普通索引的葉子節點就越小,普通索引佔用的空間也就越小
- 索引欄位越小,單層可儲存資料量越多,可減少磁碟IO
```java
// 假設一個數據頁16K、一行資料1K、索引間指標6位元組、索引欄位bigint型別(8位元組)
// 索引個數
K = 16*1024/(8+6) =1170
// 單個葉子節點記錄數
N = 16/1 = 16
// 三層B+記錄數
V = K*K*N = 21902400
```
**MyISAM也是使用B+Tree索引,區別在於不區分主鍵和非主鍵索引,均是非聚簇索引,葉子節點儲存的是資料檔案的指標**
## 索引選擇
優化器選擇索引的目的,是找到一個最優的執行方案,並用最小的代價去執行語句。在資料庫裡面,掃描行數是影響執行代價的因素之一。掃描的行數越少,意味著訪問磁碟資料的次數越少,消耗的 CPU 資源越少。
當然,掃描行數並不是唯一的判斷標準,優化器還會結合是否使用臨時表、是否排序等因素進行綜合判斷。
>
- 主鍵索引:也被稱為聚簇索引,葉子節點存的是整行資料
- 非主鍵索引:也被稱為二級索引,葉子節點內容是主鍵的值
> 注意事項
- 索引基於資料頁有序儲存,可能發生資料頁的分裂(頁儲存空間不足)和合並(資料刪除造成頁利用率低)
- 資料的無序插入會造成資料的移動,甚至資料頁的分裂
- 主鍵長度越小,普通索引的葉子節點就越小,普通索引佔用的空間也就越小
- 索引欄位越小,單層可儲存資料量越多,可減少磁碟IO
```java
// 假設一個數據頁16K、一行資料1K、索引間指標6位元組、索引欄位bigint型別(8位元組)
// 索引個數
K = 16*1024/(8+6) =1170
// 單個葉子節點記錄數
N = 16/1 = 16
// 三層B+記錄數
V = K*K*N = 21902400
```
**MyISAM也是使用B+Tree索引,區別在於不區分主鍵和非主鍵索引,均是非聚簇索引,葉子節點儲存的是資料檔案的指標**
## 索引選擇
優化器選擇索引的目的,是找到一個最優的執行方案,並用最小的代價去執行語句。在資料庫裡面,掃描行數是影響執行代價的因素之一。掃描的行數越少,意味著訪問磁碟資料的次數越少,消耗的 CPU 資源越少。
當然,掃描行數並不是唯一的判斷標準,優化器還會結合是否使用臨時表、是否排序等因素進行綜合判斷。
>
- 主鍵索引:也被稱為聚簇索引,葉子節點存的是整行資料
- 非主鍵索引:也被稱為二級索引,葉子節點內容是主鍵的值
> 注意事項
- 索引基於資料頁有序儲存,可能發生資料頁的分裂(頁儲存空間不足)和合並(資料刪除造成頁利用率低)
- 資料的無序插入會造成資料的移動,甚至資料頁的分裂
- 主鍵長度越小,普通索引的葉子節點就越小,普通索引佔用的空間也就越小
- 索引欄位越小,單層可儲存資料量越多,可減少磁碟IO
```java
// 假設一個數據頁16K、一行資料1K、索引間指標6位元組、索引欄位bigint型別(8位元組)
// 索引個數
K = 16*1024/(8+6) =1170
// 單個葉子節點記錄數
N = 16/1 = 16
// 三層B+記錄數
V = K*K*N = 21902400
```
**MyISAM也是使用B+Tree索引,區別在於不區分主鍵和非主鍵索引,均是非聚簇索引,葉子節點儲存的是資料檔案的指標**
## 索引選擇
優化器選擇索引的目的,是找到一個最優的執行方案,並用最小的代價去執行語句。在資料庫裡面,掃描行數是影響執行代價的因素之一。掃描的行數越少,意味著訪問磁碟資料的次數越少,消耗的 CPU 資源越少。
當然,掃描行數並不是唯一的判斷標準,優化器還會結合是否使用臨時表、是否排序等因素進行綜合判斷。
>
```mysql
-- 只需要查 ID 的值,而 ID 的值已經在 k 索引樹上了,因此可以直接提供查詢結果,不需要回表
select ID from T where k between 3 and 5
-- 增加欄位V,每次查詢需要返回V,可考慮把k、v做成聯合索引
select ID,V from T where k between 3 and 5
```
### 最左字首原則+索引下推
```mysql
-- id、name、age三列,name、age上建立聯合索引
-- 滿足最左字首原則,name、age均走索引
select * from T where name='xxx' and age=12
-- Mysql自動優化,調整name、age順序,,name、age均走索引
select * from T where age=12 and name='xxx'
-- name滿足最左字首原則走索引,MySQL5.6引入索引下推優化(index condition pushdown),即索引中先過濾掉不滿足age=12的記錄再回表
select * from T where name like 'xxx%' and age=12
-- 不滿足最左字首原則,均不走索引
select * from T where name like '%xxx%' and age=12
-- 滿足最左字首原則,name走索引
select * from T where name='xxx'
-- 不滿足最左字首原則,不走索引
select * from T where age=12
```
聯合索引建立原則:
- 如果通過調整順序,可以少維護一個索引,那麼這個順序往往就是需要優先考慮採用的
- 空間:優先小欄位單獨建立索引,例如:name、age,可建立(name,age)聯合索引和(age)單欄位索引
### 字首索引
```mysql
mysql> create table SUser(
ID bigint unsigned primary key,
name varchar(64),
email varchar(64),
...
)engine=innodb;
-- 以下查詢場景
mysql> select name from SUser where email='xxx';
-- 方案1:全文字索引,回表次數由符合條件的資料量決定
mysql> alter table SUser add index index1(email);
-- 方案2:字首索引,回表次數由字首匹配結果決定
mysql> alter table SUser add index index2(email(6));
```
字首索引可以節省空間,但需要注意字首長度的定義,在節省空間的同時,不能增加太多查詢成本,即減少回表驗證次數
> 如何設定合適的字首長度?
```mysql
-- 預設一個可以接受的區分度損失比,選擇滿足條件中最小的字首長度
select count(distinct left(email,n))/count(distinct email) from SUser;
```
> 如果合適的字首長度較長?
比如身份證號,如果滿足區分度要求,可能需要12位以上的字首索引,節約的空間有限,又增加了查詢成本,就沒有必要使用字首索引。此時,我們可以考慮使用以下方式:
- 倒序儲存
```mysql
-- 查詢時字串反轉查詢
mysql> select field_list from t where id_card = reverse('input_id_card_string');
```
- 使用hash欄位
```mysql
-- 建立一個整數字段,來儲存身份證的校驗碼,同時在這個欄位上建立索引
mysql> alter table t add id_card_crc int unsigned, add index(id_card_crc);
-- 查詢時使用hash欄位走索引查詢,再使用原欄位精度過濾
mysql> select field_list from t where id_card_crc=crc32('input_id_card_string') and id_card='input_id_card_string'
```
以上兩種方式的缺點:
- 不支援範圍查詢
- 使用hash欄位需要額外佔用空間,新增了一個欄位
- 讀寫時需要額外的處理,reverse或者crc32等
> 字首索引對覆蓋索引的影響?
```mysql
-- 使用字首索引就用不上覆蓋索引對查詢效能的優化
select id,email from SUser where email='xxx';
```
### 唯一索引
建議使用普通索引,唯一索引無法使用change buffer,記憶體命中率低
### 索引失效
- 不做列運算,包括函式的使用,可能破壞索引值的有序性
- 避免 `%xxx` 式查詢使索引失效
- or語句前後沒有同時使用索引,當or左右查詢欄位只有一個是索引,該索引失效
- 組合索引ABC問題,最左字首原則
- 隱式型別轉化
- 隱式字元編碼轉換
- 優化器放棄索引,回表、排序成本等因素影響,改走其它索引或者全