
排序——堆排序算法
堆排序利用的完全二叉樹這種數據結構所設計的一種算法,不過也是選擇排序的一種。
堆實質上是滿足如下性質的完全二叉樹:k[i]<=k[2*i]&&k[i]<=k[2*i+1]或者k[i]>=k[2*i]&&k[i]>=k[2*i+1],
樹中任一非葉子結點的關鍵字均不大於(或不小於)其左右孩子(若存在)結點的關鍵字。

堆分大頂堆和小頂堆:k[i]<=k[2*i]&&k[i]<=k[2*i+1]是小頂堆,k[i]>=k[2*i]&&k[i]>=k[2*i+1]是大頂堆。堆排序利用了大頂堆(或小頂堆)堆頂記錄的關鍵字最大(或最小)這一特征,使得在當前無序區中選取最大(或最小)關鍵字的記錄變得簡單。
堆排序的實現:首先,初始化堆,是對所有的非葉子結點進行篩選。最後一個非葉子節點元素的下標是[n/2]向下取最大值,所以篩選只需要從第[n/2]向下取整個元素開始,從後往前進行調整。然後從最後一個非葉子節點開始,每次都是從父節點、左孩子、右孩子中進行比較交換,交換可能會引起孩子節點不滿足堆的性質,所以每次交換之後需要重新對被交換的孩子將節點進行調整。有了初始堆之後就可以進行排序了。
堆排序是一種選擇排序。建立的初始堆為初始的無序區。
排序開始,首先輸出堆頂元素(因為它是最值),將堆頂元素和最後一個元素交換,這樣,第n個位置(即最後一個位置)作為有序區,前n-1個位置仍是無序區,對無序區進行調整,得到堆之後,再交換堆頂和最後一個元素,這樣有序區長度變為2。
不斷進行此操作,將剩下的元素重新調整為堆,然後輸出堆頂元素到有序區。每次交換都導致無序區-1,有序區+1。不斷重復此過程直到有序區長度增長為n-1,排序完成。
舉例:一個10位數的數列[5 4 3 1 2 9 7 8 0 6]
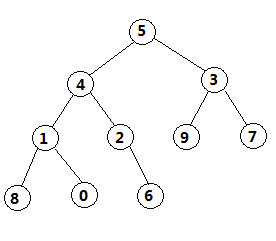
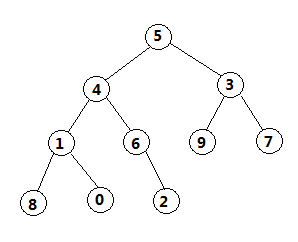
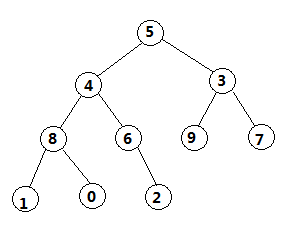
按照這樣步驟,循環往復,即每次調整都是從父節點、左孩子節點、右孩子節點三者中選擇最大者跟父節點進行交換(交換之後可能造成被交換的孩子節點不滿足堆的性質,因此每次交換之後要重新對被交換的孩子節點進行調整)。有了初始堆之後就可以進行排序了。
從上述過程可知,堆排序其實也是一種選擇排序,是一種樹形選擇排序。只不過直接選擇排序中,為了從R[1...n]中選擇最大記錄,需比較n-1次,然後從R[1...n-2]中選擇最大記錄需比較n-2次。事實上這n-2次比較中有很多已經在前面的n-1次比較中已經做過,而樹形選擇排序恰好利用樹形的特點保存了部分前面的比較結果,因此可以減少比較次數。對於n個關鍵字序列,最壞情況下每個節點需比較log2(n)次,因此其最壞情況下時間復雜度為nlogn。堆排序為不穩定排序,不適合記錄較少的排序。
代碼(C語言):
void HeapAdjust(int *a,int i,int size) { int lchild=2*i; int rchild=2*i+1; int max=i; if(i<=size/2) { if(lchild<=size&&a[lchild]>a[max]) { max=lchild; } if(rchild<=size&&a[rchild]>a[max]) { max=rchild; } if(max!=i) { swap(a[i],a[max]); HeapAdjust(a,max,size); } } } void HeapSort(int *a,int size) { int i; for(i=size/2; i>=1; i--){ HeapAdjust(a,i,size); } for(i=size;i>=1;i--) { //cout<<a[1]<<" "; swap(a[1],a[i]); //BuildHeap(a,i-1); HeapAdjust(a,1,i-1); } }
排序——堆排序算法