
R語言——一元線性回歸
1 一元線性回歸
高爾頓被譽為現代回歸的創始人,"回歸效應"的發現源於高爾頓的豌豆遺傳試驗。在這個試驗中,高爾頓發現,並非尺寸大的豌豆,其後代尺寸也大,尺寸小的豌豆,其後代尺寸也小。而是具有一種不同的趨勢,即尺寸大的豌豆趨向於得到尺寸更小的子代,而尺寸小的豌豆趨向於得到尺寸更大的後代。高爾頓把這一現象稱為"返祖",後來又稱為"向平均值回歸"。"回歸效應"的應用非常廣泛,生活中隨處可見這樣的例子。
1.1 變量之間的關系的度量
1.1.1 變量間的關系
線性回歸分析主要用於數值型數據之間的分析,因此要求所要分析的對象必須是數值型數據,即使不是數值型數據,也要想辦法變成數值型數據,比如性別可以用0-1代替,成績的優良中差可以用1-2-3-4表示等,當然這只是一種粗略的處理方法,當遇到分類型數據時,可以運用其他相應的方法處理,而不必非要使用線性回歸。
變量之間往往具有兩種關系,即確定的函數關系與不確定的相關關系。形如
 ,
,
則可以稱為函數關系,這裏y與x具有一一對應的關系,即x每取一個值,y有一個確定的值與之對應。而當x每取一個值時,y的值雖然不確定,但是總在一個確定的數的周圍變動,則這種不確定的關系可以稱之為相關關系。
1.1.2 相關分析
為了對變量之間的相關性進行描述與度量,提出了相關分析的概念。相關分析主要解決以下幾個問題:
(1)變量之間是否存在關系?
(2)如果存在關系,是什麽樣的關系?
(3)關系強度如何?
(4)樣本所表現的關系是否能夠代表總體變量之間的關系?
在進行相關分析時,需要對總體做出如下兩個假定:
(1)兩個變量之間是線性關系
(2)兩個變量都是隨機變量
①利用散點圖觀察變量的關系





②相關系數的計算

按照上式計算出來的相關系數稱為線性相關系數,也稱為Pearson相關系數.
線性相關系數具有如下幾個性質:
- r的取值範圍在-1到1之間,且包含-1和1;
- r具有對稱性,即
 ;
; - r的取值大小與原點和尺度無關;
- r僅僅是用來度量兩個變量的線性關系強弱,不能用來度量非線性關系;
- 具有相關關系並不代表具有因果關系。
註:一般認為,因果關系是現象之間的引起與被引起的關系。引起一個現象的現象叫做原因,被一個現象引起的現象叫做結果。而同時變化並不意味著具有因果關系。比如,雷聲和閃電往往同時出現,但是並不是雷聲引起了閃電,也不是閃電引起了雷聲,而是雲層之間的摩擦發出的聲音,並且形成了閃電。
一般來說,|r|>=0.8時,可視為高度相關;0.5<=|r|<0.8時,可視為中度相關;0.3<=|r|<0.5時,可視為低度相關;|r|<0.3時,認為不相關。
③相關關系的顯著性檢驗
對相關系數進行顯著性檢驗,往往假設r服從正態分布,因此,可以應用正態分布來檢驗。
第一步:提出假設。


第二步:計算檢驗統計量。

第三步:進行統計決策。
t的自由度為n-2,可查t分布表,如果|t|>|tα/2|,則可以拒絕原假設,認為兩個變量之間存在顯著地線性關系。
在R語言中,可以用cor.test()函數進行相關系數檢驗。
cor.test(x, y,
alternative = c("two.sided", "less", "greater"),
method = c("pearson", "kendall", "spearman"),
exact = NULL, conf.level = 0.95, continuity = FALSE, ...)
x,y:數值型向量或者數據框,x和y必須具有相同的長度
alternative:雙邊檢驗,左單側檢驗還是右單側檢驗
method:計算相關系數的方法
exact:邏輯值,是否計算精確的p值
conf.level:置信度或置信水平
有以下數據,展示的是某校研究生入學考試的初試分數、復試分數與總分,現在探究初試分數與復試分數的關系,看看是否具有相關性。
數據結構如下:
>#first代表初試分數,last代表復試分數,total代表總分
> str(score)
‘data.frame‘: 47 obs. of 3 variables:
$ first: int 422 407 429 410 406 413 419 414 413 396 ...
$ last : num 91 91.3 88.2 90.7 91 ...
$ total: num 530 524 523 523 523 ...
> head(score)
first last total
1 422 90.96 530.0
2 407 91.30 524.0
3 429 88.20 523.4
4 410 90.70 523.3
5 406 91.04 522.6
6 413 90.08 522.5
>#對初試分數和復試分數進行相關分析:
> cor.test(score$first,score$last)
Pearson‘s product-moment correlation
data: score$first and score$last
t = 1.4536, df = 45, p-value = 0.153
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
-0.08027284 0.47033893
sample estimates:
cor
0.2117758
>#從R的輸出結果中可以看出,相關系數為0.21,相應的p值為0.153,由於p遠大於常用的α=0.05,因此,無法拒絕原假設,認為初試分數與復試分數沒有顯著的相關性。
>#接下來探究初試分數與總分的關系。
> cor.test(score$first,score$total)
Pearson‘s product-moment correlation
data: score$first and score$total
t = 2.2898, df = 45, p-value = 0.02678
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
0.03954187 0.55840596
sample estimates:
cor
0.3230405
從上述結果可以看出,即使相關系數r只有0.323,但是p值=0.02678,小於常用的α=0.05,如果僅從p值的角度考慮,可認為初試分數與總分具有顯著的相關性。
1.2 一元線性回歸
回歸分析與相關分析具有本質的區別,具體來說,回歸分析主要解決以下幾個問題:
- 從一組樣本數據出發,確定變量之間的數學表達式;
- 對這些關系式的可信程度進行各種統計檢驗,並確定哪些變量的影響是顯著的,哪些是不顯著的;
- 利用所求的關系式,對目標變量進行預測。
1.2.1 一元線性回歸模型
①回歸模型

其中,y表示被預測的變量,即因變量,x表示預測變量,即自變量。 和
和 分別為模型的參數。
分別為模型的參數。 為隨機誤差項,表示不能被自變量與因變量之間的線性關系解釋的部分。整個方程除去隨機誤差項,則反映了自變量與因變量之間的線性關系對因變量的影響。
為隨機誤差項,表示不能被自變量與因變量之間的線性關系解釋的部分。整個方程除去隨機誤差項,則反映了自變量與因變量之間的線性關系對因變量的影響。
該模型具有幾個假設條件:
- 因變量與自變量之間具有線性關系;
- 在重復抽樣中,自變量x的取值是固定的,即自變量x非隨機變量;
- 隨機誤差項
 服從同方差、0期望的正態分布。即
服從同方差、0期望的正態分布。即
②回歸方程
根據回歸模型中的假定, 的期望為0,則
的期望為0,則 。其中
。其中 表示回歸直線在y軸上的截距,
表示回歸直線在y軸上的截距,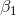 為直線的斜率。上述方程即為回歸方程。
為直線的斜率。上述方程即為回歸方程。
③估計的回歸方程
由於 與
與 是未知的,也就是需要求的總體參數,這就需要用樣本統計量去估計總體參數。因此,用樣本統計量
是未知的,也就是需要求的總體參數,這就需要用樣本統計量去估計總體參數。因此,用樣本統計量 和
和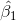 來代替總體參數所得的方程
來代替總體參數所得的方程 即為估計的回歸方程。
即為估計的回歸方程。
1.2.2 參數的最小二乘估計
假如給定一組樣本,我們可以做無數條直線去近似表示自變量與因變量的關系,但是到底那一條直線是最優的?這就需要一個評價準則。也就是說,坐標上的各點 到直線的距離最近。德國數學家卡爾·高斯提出用最小化圖中垂直方向的離差平方和來估計
到直線的距離最近。德國數學家卡爾·高斯提出用最小化圖中垂直方向的離差平方和來估計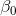 和
和 ,根據這一方法確定模型參數
,根據這一方法確定模型參數 和
和 的方法稱為最小二乘法,它是通過使因變量的觀測值
的方法稱為最小二乘法,它是通過使因變量的觀測值 與估計值
與估計值 之間的離差平方和達到最小來估計
之間的離差平方和達到最小來估計 和
和 的方法。
的方法。
根據最小二乘法,使

最小,令
 ,
,
在給定樣本數據後,Q是 和
和 的函數,且最小值總是存在的。根據微積分的極值定理,對Q求相應於
的函數,且最小值總是存在的。根據微積分的極值定理,對Q求相應於 和
和 的偏導數,並令其等於0,便可求出
的偏導數,並令其等於0,便可求出 和
和 ,即
,即


解上述方程,可得:


由上式可知,直線過樣本的中心,即 。
。
利用上述數據,對總成績與初試成績進行回歸分析,在R中可求出相應的估計值。
> attach(score)
> lm.score<-lm(total~first,data = score)
> summary(lm.score)
Call:
lm(formula = total ~ first, data = score)
Residuals:
Min 1Q Median 3Q Max
-297.189 -5.145 7.302 18.209 31.911
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -26.0397 228.0289 -0.114 0.9096
first 1.3003 0.5679 2.290 0.0268 *
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 47.06 on 45 degrees of freedom
Multiple R-squared: 0.1044, Adjusted R-squared: 0.08445
F-statistic: 5.243 on 1 and 45 DF, p-value: 0.02678
在R中,可以用lm()函數對線性回歸方程進行擬合,該函數返回的是一個回歸對象。用summary()函數可以輸出該對象的一些細節。
Call:公式
Residuals:殘差
Coefficients:估計的回歸系數、標準誤、t值、p值以及R平方等統計量。
1.2.3 回歸直線的擬合優度
①判定系數
在方差分析文章中,已經介紹過R平方的計算原理,這裏回歸直線的擬合優度與之類似,也用R平方來衡量。
記總平方和為SST,即
 ,
,
而每個觀測點的離差可以分解為:
 ,可以證明,
,可以證明,

即
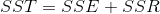
SSE表示除了x對y的線性影響之外的其他因素引起的誤差,是不能被回歸直線解釋的變差部分,稱為誤差平方和。
SSR表示x對y的線性影響,是可以由回歸直線解釋的部分,稱為回歸平方和。
回歸平方和占總平方和的比例,稱為判定系數:

根據R平方,可以判斷直線對數據的擬合程度。
同時,R平方與在數值上是相關系數r的平方,因此,假設即使r已經達到了0.5,但是R平方僅為0.25,不能說明擬合得很好。
②估計標準誤差
估計標準誤差是度量各實際觀測點在直線周圍散布狀況的一個統計量,同時均方殘差(MSE)的平方根,用Se來表示,其計算公式為:
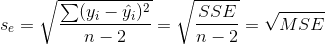 。
。
估計標準誤差是對誤差項的標準差 的估計,可以看做在排除了x對y的線性影響後,y隨機波動大小的一個估計量。
的估計,可以看做在排除了x對y的線性影響後,y隨機波動大小的一個估計量。
1.2.4 顯著性檢驗
①線性關系檢驗
第一步:提出假設。


第二步:計算檢驗統計量F。

第三步:做出統計決策。
F服從第一自由度為1,第二自由度為n-2的F分布,查F分布表,若F大於Fα(1,n-2),則拒絕原假設,認為兩個變量之間的線性關系是顯著的。
②回歸系數檢驗
第一步:提出假設。


第二步:計算檢驗統計量t。
 ,其中,
,其中, ,t服從自由度為n-2的t分布。
,t服從自由度為n-2的t分布。
第三步:進行統計決策。
若|t|>tα/2,則拒絕原假設。
在一元線性回歸中,線性關系的檢驗與回歸系數的檢驗等價。但在多元回歸分析中,具有不同的意義。
下面給出幾個結果的計算公式:
|
名稱 |
計算公式 |
註釋 |
|
調整的R平方 |
|
K為自變量的個數 |
|
截距的抽樣標準誤差 |
|
Se為標準誤 |
|
截距的置信區間 |
|
|
|
斜率的置信區間 |
|




1.3 預測
預測是指通過自變量x的取值來預測因變量y的取值。
1.3.1 點估計
①個別值的點估計
對於一個給定的x0,求出y的一個個別值的估計值 。
。
②平均值的點估計
對於一個給定的值x0,求出y的平均值的一個估計值
1.3.2 區間估計
①置信區間估計
置信區間估計就是對x的一個給定值x0,求出y的平均值的區間估計。用 表示
表示 的標準差的估計量,其計算公式為
的標準差的估計量,其計算公式為
 ,
,
E(y0)在1-α的置信水平下的置信區間為:

②預測區間估計
預測區間估計是對x的一個給定值x0,求出y的一個個別值的區間估計。
y的一個個別值y0的標準差為 ,其計算公式為:
,其計算公式為:
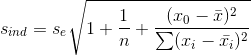
因此,對於給定的x0,y的一個個別值y0在1-α置信水平下的預測區間可表示為:

1.4 殘差分析
確定有關ε的假定是否成立的方法之一就是進行殘差分析。
1.4.1 殘差圖
殘差圖分為關於x的殘差圖、關於 的殘差圖、標準化殘差圖等。該例中,關於x的殘差圖如下:
的殘差圖、標準化殘差圖等。該例中,關於x的殘差圖如下:

發現除了一個點偏離比較嚴重意外,其他的點都較為均勻地分布在0周圍。
1.4.2 標準化殘差
標準化殘差是殘差除以它的標準差以後得到的數值。
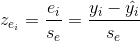 。
。

雖然標準化殘差在0兩側均勻分布,但是似乎具有某種趨勢,不一定滿足隨機誤差項的假設。
R語言——一元線性回歸