
批量梯度下降法(Batch Gradient Descent)
批量梯度下降:在梯度下降的每一步中都用到了所有的訓練樣本。
思想:找能使代價函數減小最大的下降方向(梯度方向)。
ΔΘ = - α▽J α:學習速率
梯度下降的線性回歸
線性模型的代價函數:
![]()
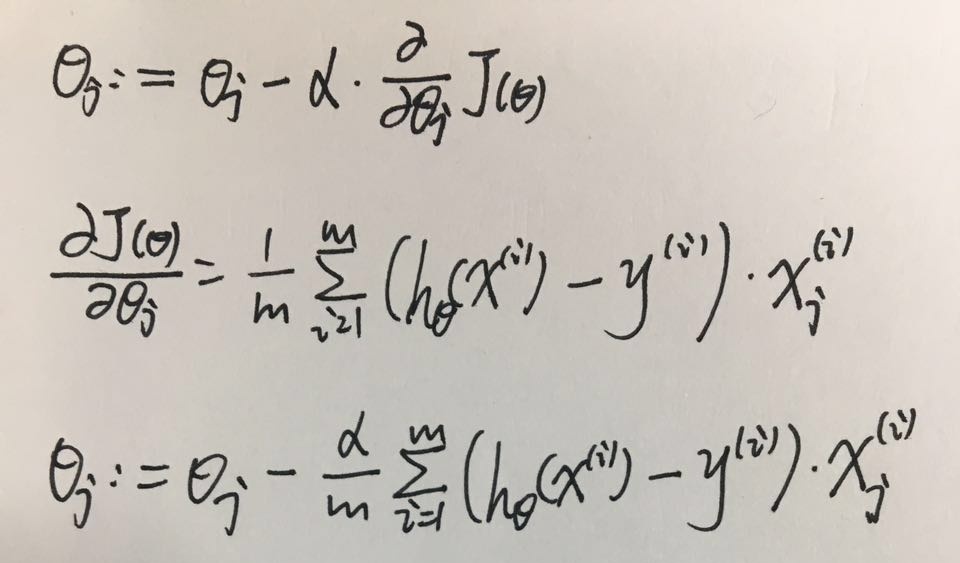
對於更新項,為什麽是 - α▽J :
Θ如果在極值點右邊,偏導大於0,則Θ要減去偏導的值(Θ偏大,減去一個正值)
Θ如果在極值點左邊,偏導小於0,則Θ要減去偏導的值(Θ偏小,減去一個負值)
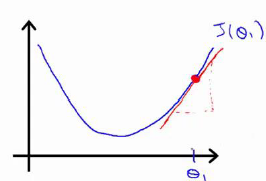
實現方法:同步更新每個Θ
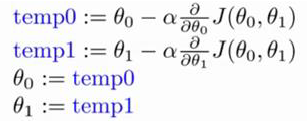
特點:梯度下降法即使α取很大也可以收斂到局部最小值。
隨著算法的進行,越接近最小值點偏導的那一項越小,Θ的變化量也就越小。
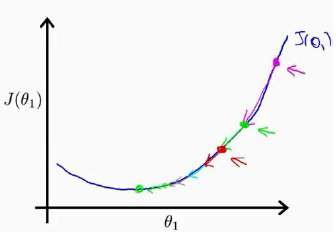
圖中可以看出,初始Θ取粉色點所在的值,隨著算法的進行步長越來越小。
批量梯度下降法(Batch Gradient Descent)
相關推薦
批量梯度下降法(Batch Gradient Descent)
所有 margin 初始 ont 模型 log eight 梯度下降 img 批量梯度下降:在梯度下降的每一步中都用到了所有的訓練樣本。 思想:找能使代價函數減小最大的下降方向(梯度方向)。 ΔΘ = - α▽J α:學習速率 梯度下降的線性回歸
隨機梯度下降法(Stochastic Gradient Descent)和批量梯度下降法(Batch Gradient Descent )總結
梯度下降法常用於最小化風險函式或者損失函式,分為隨機梯度下降(Stochastic Gradient Descent)和 批量梯度下降(Batch Gradient Descent )。除此之外,還有梯度上升法(Gradient Ascent),應用於極大似
學習筆記13:隨機梯度下降法(Stochastic gradient descent, SGD)
假設我們提供了這樣的資料樣本(樣本值取自於y=3*x1+4*x2):x1x2y1419252651194229x1和x2是樣本值,y是預測目標,我們需要以一條直線來擬合上面的資料,待擬合的函式如下:我們
吳恩達深度學習筆記(8)-重點-梯度下降法(Gradient Descent)
梯度下降法(Gradient Descent)(重點) 梯度下降法可以做什麼? 在你測試集上,通過最小化代價函式(成本函式) J(w,b) 來訓練的引數w和b , 如圖,在第二行給出和之前一樣的邏輯迴歸演算法的代價函式(成本函式)(上一篇文章已講過) 梯度下降法的形象化
高斯混合模型(GMM model)以及梯度下降法(gradient descent)更新引數
關於GMM模型的資料和 EM 引數估算的資料,網上已經有很多了,今天想談的是GMM的協方差矩陣的分析、GMM的引數更新方法 1、GMM協方差矩陣的物理含義 涉及到每個元素,是這樣求算: 用中文來描述就是: 注意後面的那個除以(樣本數-1),就是大括號外面的E求期望 (這叫
梯度下降法(Gradient Descent)
第一次寫部落格,好激動啊,哈哈。之前看了許多東西但經常是當時花了好大功夫懂了,但過一陣子卻又忘了。現在終於決定追隨大牛們的腳步,試著把學到的東西總結出來,一方面梳理思路,另一方面也作為備忘。接觸機器學習不久,很多東西理解的也不深,文章中難免會有不準確和疏漏的
機器學習與高數:梯度(Gradient)與梯度下降法(Gradient Descent)
一篇經典部落格: http://blog.csdn.net/walilk/article/details/50978864 1.導數定義:導數代表了在自變數變化趨於無窮小的時候,函式值的變化與自變數的變化的比值。幾何意義是這個點的切線。物理意義是該時刻的(瞬時)變化率。
梯度下降法(GD,SGD,Mini-Batch GD)線上性迴歸中的使用
https://github.com/crystal30/SGDLinrearRegression一. 梯度下降法(Batch Gradient Descent)1.梯度下降法的原理(1) 梯度下降法是一種基於搜尋的最優化方法,不是一個機器學習演算法。(2) 作用:
梯度下降法的三種形式批量梯度下降法、隨機梯度下降以及小批量梯度下降法
梯度下降法的三種形式BGD、SGD以及MBGD 梯度下降法的三種形式BGD、SGD以及MBGD 閱讀目錄 1. 批量梯度下降法BGD 2. 隨機梯度下降法SGD 3. 小批量梯度下降法MBGD 4. 總結 在應用機器學習演
隨機梯度下降法,批量梯度下降法和小批量梯度下降法以及程式碼實現
前言 梯度下降法是深度學習領域用於最優化的常見方法,根據使用的batch大小,可分為隨機梯度下降法(SGD)和批量梯度下降法(BGD)和小批量梯度下降法(MBGD),這裡簡單介紹下並且提供Python程式碼演示。 如有謬誤,請聯絡指正。轉載請註明出處。 聯
機器學習(7)--梯度下降法(GradientDescent)的簡單實現
曾經在 機器學習(1)--神經網路初探 詳細介紹了神經網路基本的演算法,在該文中有一句weights[i] += 0.2 * layer.T.dot(delta) #0.2學習效率,應該是一個小於0.5的數,同時在 tensorflow例項(2)--機器學習初試
梯度下降法(上升法)的幾何解釋
梯度下降法是機器學習和神經網路學科中我們最早接觸的演算法之一。但是對於初學者,我們對於這個演算法是如何迭代執行的從而達到目的有些迷惑。在這裡給出我對這個演算法的幾何理解,有不
機器學習金典演算法(二)--梯度下降法(2)
機器學習金典演算法(二)–梯度下降法 本人上篇博文梯度下降法(1)解釋了梯度下降法在機器學習中位置及思想,本文將繼續討論梯度下降法,梯度下降法存在的問題及改進思路,以及現有的幾種流行的變種梯度下降法。 目錄
斯坦福大學機器學習筆記——單變數的線性迴歸以及損失函式和梯度下降法(包含程式碼)
迴歸問題: 所謂的迴歸問題就是給定的資料集,且每個資料集中的每個樣例都有其正確的答案,通過給定的資料集進行擬合,找到一條能夠最好代表該資料集的曲線,然後對於給定的一個樣本,能夠預測出該樣本的答案(對於迴歸問題來說,最終的輸出結果是一個連續的數值)。比如
梯度下降法、隨機梯度下降法、批量梯度下降法及牛頓法、擬牛頓法、共軛梯度法
引言 李航老師在《統計學習方法》中將機器學習的三要素總結為:模型、策略和演算法。其大致含義如下: 模型:其實就是機器學習訓練的過程中所要學習的條件概率分佈或者決策函式。 策略:就是使用一種什麼樣的評價,度量模型訓練過程中的學習好壞的方法,同時根據這個方
梯度下降,隨機梯度下降,批量梯度下降,mini-batch 梯度下降
最近在看到一些神經網路優化的問題, 再進行模型的訓練的時候,總是希望得到一個能較好的反映實際的模型,在對模型訓練的時候其實是在學習其中的引數, 其中主要使用的損失函式來模擬我們的目標,只要使得損失函式可以達到最小或是比較小(可以滿足對問題的求解)就行 在對損失函式進行學習
線性迴歸和批量梯度下降法python
通過學習斯坦福公開課的線性規劃和梯度下降,參考他人程式碼自己做了測試,寫了個類以後有時間再去擴充套件,程式碼註釋以後再加,作業好多: import numpy as np import matplotlib.pyplot as plt import random clas
梯度下降演算法Python程式碼實現--批量梯度下降+隨機梯度下降+小批量梯度下降法
在學習線性迴歸的時候很多課程都會講到用梯度下降法求解引數,對於梯度下降演算法怎麼求出這個解講的較少,自己實現一遍演算法比較有助於理解演算法,也能注意到比較細節的東西。具體的數學推導可以參照這一篇部落格(http://www.cnblogs.com/pinard/p
batch gradient descent(批量梯度下降) 和 stochastic gradient descent(隨機梯度下降)
批量梯度下降是一種對引數的update進行累積,然後批量更新的一種方式。用於在已知整個訓練集時的一種訓練方式,但對於大規模資料並不合適。 隨機梯度下降是一種對引數隨著樣本訓練,一個一個的及時update的方式。常用於大規模訓練集,當往往容易收斂到區域性最優解。 詳細參見:Andrew Ng 的Machine
梯度下降算法(gradient descent)
調整 none 算法 方向導數 分享圖片 後繼 常用 也有 計算 簡述梯度下降法又被稱為最速下降法(Steepest descend method),其理論基礎是梯度的概念。梯度與方向導數的關系為:梯度的方向與取得最大方向導數值的方向一致,而梯度的模就是函數在該點的方向導數