
TensorFlow實戰--閱讀筆記part1
這本書適合看過官方文檔或其他基礎教程的人,講的多是些具體網絡的實現
一、tensorflow基礎

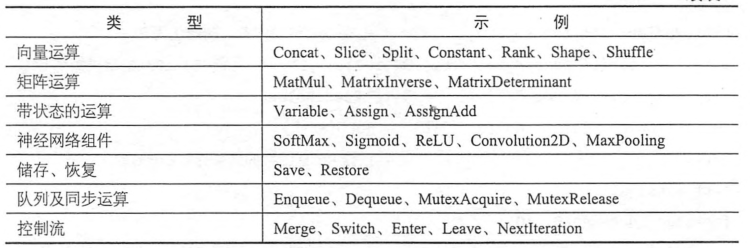
tensorflow的操作流程
1. 自定義節點,自定義有向圖,一般是把整個流程圖都定義完整

每個需要看輸出結果的節點都必須有顯式地進行定義,形式如 node=...... 比如2,3,4,5,6行等
對於不需要進行輸出的節點可以不進行顯示定義,比如Add
2. 通過Session的run方法進行執行計算圖
每次run都是指定一個節點計算,比如說: tf.Session.run(ReLU)
我們要計算ReLU的話,同時它依賴的一些節點都會按順序進行計算,比如說Add,MatMul,
同時我們看到還需要有輸入x, 那麽我們需要把x作為參數輸入到run函數:
tf.Session.run(ReLU,feed_dict={x:input})
其中x是定義的placeholder節點,作為外部輸入的節點類型都為tf.placeholder
input是實際的數據(矩陣或者列表)
W,b是定義的變量節點 tf.Variable, 註意V是大寫
3. 總結
- 如果創建圖之後發現圖不夠完整還需要添加邊或者節點,可以通過Session的Extend方法添加新的節點或者邊
- Session的run方法執行計算圖時,用戶需要給出需要計算的結點,也就是你所想要看到的結果,同時還要提供輸入數據,Tensorflow就會自動尋找所有需要計算的節點並按依賴順序執行它們。通常來說,都是創建一次計算圖,然後反復地執行整個計算圖或是其中的一部分子圖
- 計算圖會被執行多次,但是數據(tensor)不會被持續保留,只是在計算圖中過一遍,也就是為什麽取名叫tensorflow了,數據流過無痕
- 比如說你計算ReLU節點的時候會計算Matmul結點,但是數據不會保留,則是只會輸入ReLU結果,所以當你還要看Matmul結果時,你需要重新計算Matmul節點
- 上面所說的是計算的中間結果不會保存,但是Variable作為一種特殊的運算操作,它可以將一些需要保留的tensor存儲在內存或顯存中,比如神經網絡模型中的系數。每一次執行計算圖後,Variable中的數據tensor會被保存,同時在計算過程中這些tensor也可以被更新,比如神經網絡的每一次mini-batch訓練時,神經網絡的系數將會被更新並保存
Tensorflow的實現原理(設備管理)
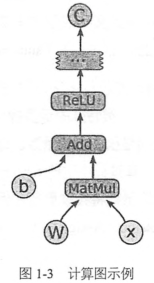
client客戶端, 通過Session的接口與master及多個worker相連。其中每一個worker與多個硬件設備相連(CPU/GPU),並負責管理這些硬件
master則負責指導所有worker按流程執行計算圖
Tensorflow有單機模式和分布式模式兩種實現:
- 單機模式:client,master,worker全部在一臺機器上的同一個進程中
- 分布式模式:允許client,master,worker在不同機器的不同進程中,同時由集群調度系統統一管理各項任務
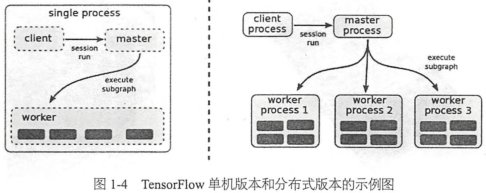
Tensorflow中每一個worker可以管理多個設備,每一個設備的name包含硬件類別、編號、任務號(單機版本中沒有),示例如下:
單機模式:/job:localhost/device:cpu:0
分布式模式:/job:worker/task:17/device:gpu:3
在只有一個硬件設備的情況下,計算圖會按依賴關系被順序執行。當一個節點的所有上遊依賴都被執行完時(依賴數為0),這個節點就會被加入ready queue以等待執行。同時,它下遊所有節點的依賴數減1,實際上這就是標準的計算拓撲序的方式。當有多個設備時,情況就比較復雜了,難點有二:
- 每一個節點該讓什麽硬件設備執行: tensorflow設計了一套為節點分配設備的策略,有相應的代價模型,會選擇一個綜合實踐最短的設備作為節點的運算設備。以後還會改進
- 如何管理節點間的數據通信:把數據通信的問題轉變為發送節點和接收節點的實現問題,用戶不需要為不同的硬件環境實現通信方法
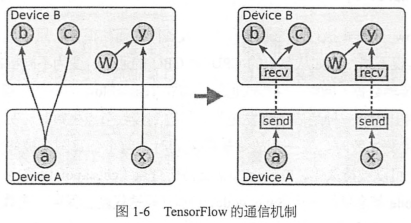
Tensorflow分布式執行時的通信和單機設備間的通信很像,只不過是對發送節點和接收節點的實現不同:比如從單機的CPU到GPU的通信,變為不同機器之間使用TCP或者RDMA傳輸數據。
Tensorflow擴展功能
tensorflow自動求導
如下圖,當tensorflow計算一個tensor C關於tensor I的梯度時,會先尋找從I到C的正向路徑,然後從C回溯到I,對這條回溯路徑上的每一個節點增加一個對應求解梯度的節點,並根據鏈式法則計算總的梯度,這就是反向傳播算法。這些新增的節點會計算梯度函數比如[db,dW,dx] = tf.gradients(C,[b,W,x])
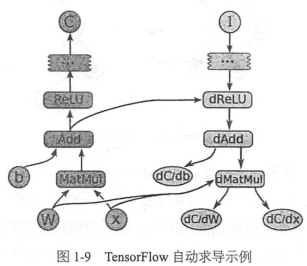
問題:當計算反向傳播時,可能需要用到前面圖開頭的一些tensor,然而這些中間結果tensorflow不會保存,保存tensor會占用太多內存或顯存,所以一般不進行保存而選擇重新計算,tensorflow仍在持續改進這些問題
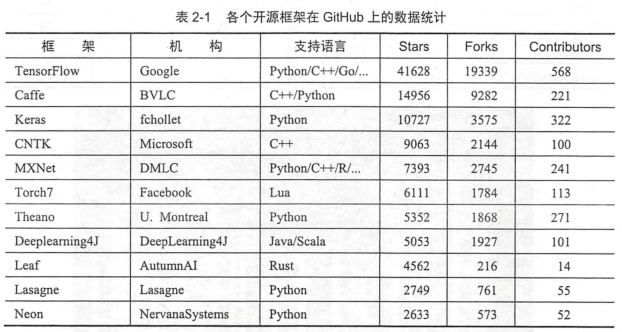
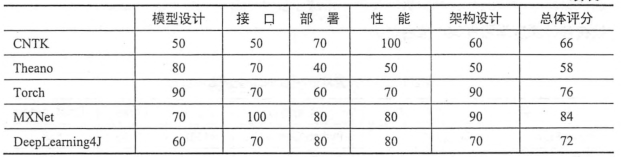
二、Tensorflow和其他深度學習框架的對比
tensorflow優點
設計神經網絡結構的代碼的簡潔度
分布式深度學習算法的執行效率
部署的便利性

Caffe
caffe優點:
- 容易上手,網絡結構都是以配置文件形式定義,不需要用代碼設計網絡
- 訓練速度快,能夠訓練state-of-the-art 的模型和大規模的數據
- 組件模塊化,可以方便地拓展到新的模型和學習任務上
- 擁有大量的訓練好的經典模型,收藏在 Model Zoo
caffe缺點:
- 實現新layer時,需要將正向和反向兩種計算過程的函數都實現,這部分計算需要用戶自己寫C++或CUDA(當需要運行在GPU上)代碼,對普通用戶來說非常難上手
- Caffe最初設計時的目標只針對圖像,沒有考慮文本語音等時間序列數據,所以caffe對CNN支持非常好, 但是對RNN支持不充分
- caffe的配置文件不能用編程的方式調整超參,不方便進行交叉驗證,超參數的Grid Search等
Theano
theano優點:
- 集成Numpy,可以直接使用Numpy的ndarray,API接口學習成本低
- 計算穩定性好,比如可以精準地計算輸出值很小的函數(像log(1+x))
- 動態地生成C或者CUDA代碼,用以編譯成高效的機器代碼
- theano自動求導
- theano派生出了大量基於它的深度學習庫,比如Keras,Lasagne
- Keras比較適合在探索階段快速地嘗試各種網絡結構,組件都是可插拔的模塊,只需要將一個個組件(比如卷積層、激活函數等)連接起來,但是設計新模塊或者新的Layer就不太方便
- 學術界喜愛的Lasagne,對神經網絡內的每一層的定義都非常嚴謹
theano缺點:
- 更多作為一個研究工具而不是產品
- 沒有底層C++接口,所以模型部署非常不方便,依賴於各種python庫,不支持各種移動設備,所以幾乎沒有在工業生產環境的應用
- Theano在調試時輸出的錯誤信息非常難看懂,debug很痛苦
Torch
用lua語言編程
MXNet
- 各個框架中率先支持多GPU和分布式的
- MXNet的核心是一個動態的依賴調度器,支持自動將計算任務並行化到多個GPU或分布式集群
- 支持非常多的語言封裝
CNTK
- 在語音識別領域中使用廣泛
- 支持自動求解梯度
TensorFlow實戰--閱讀筆記part1