
TensorFlow實戰--閱讀筆記part3
一、Tensorflow實現卷積神經網絡
卷積神經網絡的概念最早出自19世紀60年代科學技術提出的感受野。當時科學家通過對貓的視覺皮層細胞研究發現,每一個視覺神經元只會處理一小塊區域的視覺圖像,即感受野。
一個卷積層中可以有多個不同的卷積核,而每一個卷積核都對應一個濾波後映射出的新圖像,同一個新圖像中每一個像素都來自完全相同的卷積核,這就是卷積核的權值共享。
權值共享是為了降低模型復雜度,減輕過擬合並降低計算量。
一個隱含節點對應於新產生的圖的一個像素點
1994年LeNet (Yann LeCun)
Tensorflow實現簡單的卷積網絡
1.首先載入MNIST數據集,並創建默認的Session
from tensorflow.examples.tutorials.mnist import input_data import tensorflow as tf mnist = input_data.read_data_sets("MNIST_data/",one_hot=True) sess = tf.InteractiveSession()
2. 定義常用函數,對於權重要制造一些隨機的噪聲來打破完全對稱,比如截斷的正態分布噪聲,標準差設為0.1
對偏置也增加一些小的正值(0.1)來避免死亡節點(dead neurons)
對於conv2d函數,W是卷積核,shape=[5,5,1,32],表示卷積核大小為5x5,channel為1,共有32個
strides代表卷積模板移動的步長,因為都是二維平面移動,所以一般第一維和第四維固定為1,中間兩維表示平面兩個方向的步長[1,1,1,1]
padding表示邊界的處理方式,這裏SAME代表給邊界加上padding讓卷積的輸出和輸入保持同樣的尺寸
pooling中的ksize表示窗口的大小,通常第一,第四維固定為1,中間兩維表示平面窗口的大小
def weight_variable(shape): initial = tf.truncated_normal(shape,stddev=0.1) return tf.Variable(initial) def bias_variable(shape): initial= tf.constant(0.1,shape=shape) return tf.Variable(initial) def conv2d(x,W): return tf.nn.conv2d(x,W,strides=[1,1,1,1],padding=‘SAME‘) def max_pool_2x2(x): return tf.nn.max_pool(x,ksize=[1,2,2,1],strides=[1,2,2,1],padding=‘SAME‘)
3. 定義網絡結構
註意輸入是要reshape成平面結構用於卷積網絡
所以若輸入為[None,784],要將其轉換成28x28的形狀用作卷積 -1表示通過原尺寸自動計算該維的值,比如說 x = [4,7] x‘ = tf.reshape(x,[-1,14]) 那麽 x‘ = [2,14]
x = tf.placeholder(tf.float32,[None,784]) y_ = tf.placeholder(tf.float32,[None,10]) x_image = tf.reshape(x,[-1,28,28,1]) W_conv1 = weight_variable([5,5,1,32]) b_conv1 = bias_variable([32]) h_conv1 = tf.nn.relu(conv2d(x_image,W_conv1)+b_conv1) h_pool1 = max_pool_2x2(h_conv1) W_conv2 = weight_variable([5,5,32,64]) b_conv2 = bias_variable([64]) h_conv2 = tf.nn.relu(conv2d(h_pool1,W_conv2)+b_conv2) h_pool2 = max_pool_2x2(h_conv2) W_fc1 = weight_variable([7*7*64,1024]) b_fc1 = bias_variable([1024]) h_pool2_flat = tf.reshape(h_pool2,[-1,7*7*64]) h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat,W_fc1)+b_fc1) keep_prob = tf.placeholder(tf.float32) h_fc1_drop = tf.nn.dropout(h_fc1,keep_prob) W_fc2= weight_variable([1024,10]) b_fc2 = bias_variable([10]) y_conv =tf.nn.softmax(tf.matmul(h_fc1_drop,W_fc2)+b_fc2) cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_*tf.log(y_conv),reduction_indices=[1])) train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy) correct_prediction = tf.equal(tf.argmax(y_conv,1),tf.argmax(y_,1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
4. 進行訓練
通常在整點處用下一個batch進行簡單測試效果,要先測試再訓練
註意測試時keep_prob=1.0, 即不用dropout
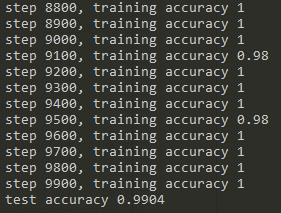
tf.global_variables_initializer().run() for i in range(20000): batch = mnist.train.next_batch(50) if i%100 == 0: train_accuracy = accuracy.eval(feed_dict={x:batch[0],y_:batch[1],keep_prob:10}) print("step %d, training accuracy %g" %(i,train_accuracy)) train_step.run(feed_dict={x:batch[0],y_:batch[1],keep_prob:0.5}) pritn("test accuracy %g" %accuarcy.eval(feed_dict={x:mnist.test.images,y_:mnist.test.labels,keep_prob:1.0}))
5.測試結果
相比於mlp的98%,卷積神經網絡可以達到99%的精確度
二、Tensorflow實現進階的卷積神經網絡
這裏使用CIFAR-10數據集,相比於MNIST的手寫數字識別(黑白),CIFAR中object識別更難(彩色)
60000張32x32的彩色圖像,其中五萬張訓練,一萬張測試,共有10類,每一張圖片只有一個目標
相比簡單版,這裏使用的新技巧:
(1)對weights進行了L2的正則化
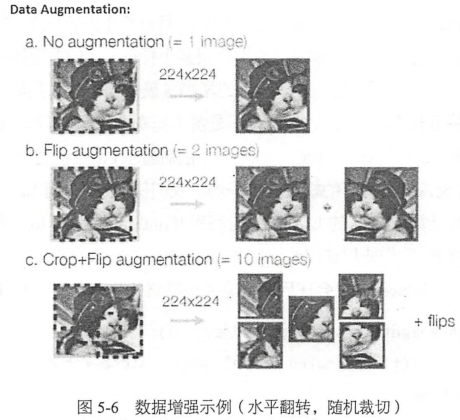
(2)對圖片進行了翻轉,隨機剪切等數據增強,制造了更多樣本,data augmentation
(3)在每個卷積-最大池化層後面使用了LRN層,增強了模型的泛化能力
代碼實現進階版卷積神經網絡
首先要下載Tensorflow Models庫,以便使用其中提供CIFAR-10數據的類
git clone https://github.com/tensorflow/models.git
cd models/tutorials/image/cifar10
然後載入一些常用庫及一些參數定義,數據下載的默認路徑
import cifar10,cifar10_input import tensorflow as tf import numpy as np import time max_steps = 3000 batch_size = 128 data_dir = ‘/tmp/cifar10_data/cifar-10-batches-bin‘
定義初始化weight的函數,這裏給weight加了一個L2的loss,相當於做了一個L2的正則化處理
特征過多容易過擬合,可以通過減少特征或者懲罰不重要的特征來緩解這個問題,通常我們不知道該懲罰哪些特征的權重,而正則化就是幫助我們懲罰特征權重的,即特征的權重也會成為模型的損失函數的一部分。可以理解為,為了使用某個特征,我們需要付出loss的代價,除非這個特征非常有效,否則就會被loss上的增加覆蓋效果。這樣就可以篩選出最有效的特征,減少特征權重防止過擬合。這也即是奧卡姆剃刀法則,越簡單的東西越有效。
一般來說,L1正則會制造稀疏的特征,大部分無用特征的權重會被置0,而L2正則會讓特征的權重不過大,使得特征的權重比較平均。
用tf.add_to_collection把weight loss統一存到一個collection,名字為“losses”,在後面計算神經網絡總體loss的時候會用上
def variable_with_weigth_loss(shape,stddev,w1): var = tf.Variable(tf.truncated_normal(shape,stddev=stddev)) if w1 is not None: weight_loss = tf.multiply(tf.nn.l2_loss(var),w1,name=‘weight_loss‘) tf.add_to_collection(‘losses‘,weight_loss) return var
使用cifar10類下載數據集,並解壓,展開到默認位置
cifar10.maybe_download_and_extract()
再使用cifar10_input類中的distorted_inputs函數產生訓練需要使用的數據,包括特征及label,每次執行都會生成一個batch_size數量的樣本,這裏對數據進行了data augmentation,具體細節可以看相應函數
數據增強包括隨機的水平翻轉,隨機剪切一塊24x24大小的圖片,設置隨機的亮度和對比度,以及對數據進行標準化(減去均值,除以方差,保證數據零均值,方差為1)
通過這些操作,可以獲得更多的樣本(帶噪聲)原來一張圖片贗本可以變為多張圖片,相當於擴大樣本量,對提高準備率很有幫助
需要註意,對圖像增強的操作需要耗費大量CPU時間,因此distorted_input使用了16個獨立的線程來加速任務,函數內部會產生線程池,在需要使用時會通過tensorflow queue進行調度
images_train,labels_train = cifar10_input.distorted_inputs(data_dir=data_dir,batch_size=batch_size)
再通過cifar10_input.inputs函數生成測試數據,這裏不需要進行太多處理,不需要對圖片進行翻轉或修改亮度,對比度,不過需要裁剪圖片正中間的24x24大小的區塊,並進行數據標準化操作
images_test,labels_test = cifar10_input.inputs(eval_data=True,data_dir=data_dir,batch_size=batch_size)
第一層卷積層的L2正則系數為0,bias也初始化為0
最大池化的尺寸和步長不一致,可以增加數據的豐富性
LRN最早見於AlexNet,解釋說LRN層模仿了生物神經系統的“側抑制”機制,對局部神經元的活動創建競爭環境,使得其中相應比較大的值變得相對更大,並抑制其他反饋較小的神經元,增強了模型的泛化能力。
LRN層對ReLU這種沒有上限邊界的激活函數會比較有用,因為它會從附近的多個卷積核的響應中挑選比較大的反饋,但不適合Sigmoid這種有固定邊界並且能抑制過大值的激活函數
weight1 = variable_with_weigth_loss(shape=[5,5,3,64],stddev=5e-2,w1=0.0) kernel1 = tf.nn.conv2d(image_holder,weight1,[1,1,1,1],padding=‘SAME‘) bias1 = tf.Variable(tf.constant(0.0,shape=[64])) conv1 = tf.nn.relu(tf.nn.bias_add(kernel1,bias1)) pool1 = tf.nn.max_pool(conv1,ksize=[1,3,3,1],strides=[1,2,2,1],padding=‘SAME‘) norm1 = tf.nn.lrn(pool1,4,bias=1.0,alpha=0.001/9.0,beta=0.75)
第二層卷積層L2正則系數為0,bias初始化為0.1,而且調換了最大池化和LRN的順序
weight2 = variable_with_weigth_loss(shape=[5,5,64,64],stddev=5e-2,w1=0.0) kernel2 = tf.nn.conv2d(norm1,weight2,[1,1,1,1],padding=‘SAME‘) bias2 = tf.Variable(tf.constant(0.1,shape=[64])) conv2 = tf.nn.relu(tf.nn.bias_add(kernel2,bias2)) norm2 = tf.nn.lrn(conv2,4,bias=1.0,alpha=0.001/9.0,beta=0.75) pool2 = tf.nn.max_pool(norm2,ksize=[1,3,3,1],strides=[1,2,2,1],padding=‘SAME‘)
兩層全連接層
我們希望這個全連接層不要過擬合,因此設了一個非0的weight loss為0.004,讓這一層的所有參數都被L2正則所約束,bias初始化為0.1
reshape = tf.reshape(pool2,[batch_size,-1])
dim = reshape.get_shape()[1].value
weight3 = variable_with_weigth_loss(shape=[dim,384],stddev=0.04,w1=0.004)
bias3 = tf.Variable(tf.constant(0.1,shape=[384]))
local3 = tf.nn.relu(tf.matmul(reshape,weight3)+bias3)
weight4 = variable_with_weigth_loss(shape=[384,192],stddev=0.04,w1=0.004)
bias4 = tf.Variable(tf.constant(0.1,shape=[192]))
local4 = tf.nn.relu(tf.matmul(local3,weight4)+bias4)
最後一層,不計L2正則,正態分布的標準差設為上一個隱含層的節點數的倒數,而且這裏沒有使用softmax作為輸出,而是放在了計算loss的部分
weight5 = variable_with_weigth_loss(shape=[192,10],stddev=1/192.0,w1=0.0) bias5 = tf.Variable(tf.constant(0.0,shape=[10])) logits = tf.add(tf.matmul(local4,weight5),bias5)
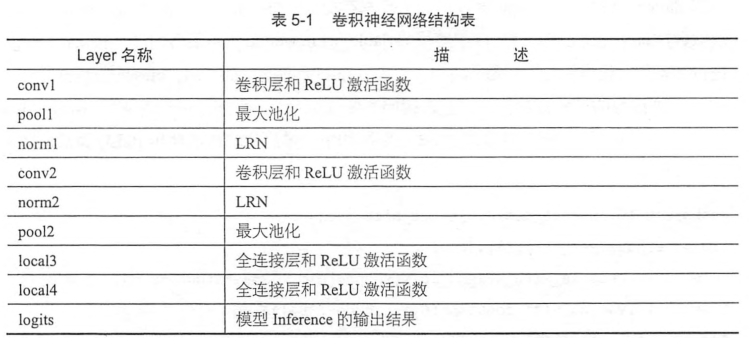
以上完成了整個網絡的inference部分,如下表,是整個神經網絡從輸入到輸出的流程,可以發現,設計CNN主要就是安排卷積層,池化層,全連接層的分布和順序,以及其中超參數的設置,trick的使用等。
設計性能良好的CNN是有一定規律可循的,但是想要針對某個問題設計最合適的網絡結構是需要大量實踐摸索的
開始計算loss
使用tf.add_n將整體losses的collection中全部loss求和,得到最終的loss,其中包括cross entropy loss,還有後面兩個全連接層中weight的L2 loss
這裏in_top_k表示label在不在top_k結果中,這裏使用tf.nn.in_toop_k函數求輸出結果中top k的準確率
def loss(logits,labels): labels = tf.cast(labels,tf.int64) cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits( logits=logits,labels=labels,name=‘cross_entropy_per_example‘) cross_entropy_mean = tf.reduce_mean(cross_entropy,name=‘cross_entropy‘) tf.add_to_collection(‘losses‘,cross_entropy_mean) return tf.add_n(tf.get_collection(‘losses‘),name=‘total_loss‘) loss = loss(logits,label_holder) train_op = tf.train.AdamOptimizer(1e-3).minimize(loss) top_k_op = tf.nn.in_top_k(logits,label_holder,1) sess = tf.InteractiveSession() tf.global_variables_initializer().run()
啟動圖片數據增強的線程隊列,這裏一共使用了16個線程來進行加速,註意,如果這裏不啟動線程,那麽後續的inference及訓練操作都是無法開始的
tf.train.start_queue_runners()
開始正式訓練,會輸出一些時間的信息
for step in range(max_steps): start_time = time.time() image_batch,label_batch = sess.run([images_train,labels_train]) _,loss_value = sess.run([train_op,loss], feed_dict={image_holder:image_batch,label_holder:label_batch}) duration = time.time() - start_time if step % 10 ==0: examples_per_sec = batch_size / duration sec_per_batch = float(duration) format_str=(‘step %d,loss=%.2f (%.1f examples/sec; %3f sec/batch‘) print(format_str %(step,loss_value,examples_per_sec,sec_per_batch))
進行測試
執行top_k_op計算模型在這個batch的top1上預測正確的樣本數,然後匯總所有預測正確的結果,求得全部測試樣本中預測正確的數量
num_examples = 10000 import math num_iter = int(math.ceil(num_examples/batch_size)) true_count = 0 total_sample_count = num_iter * batch_size step = 0 while step < num_iter: image_batch,label_batch = sess.run([images_test,labels_test]) predictions = sess.run([top_k_op],feed_dict={image_holder:image_batch, label_holder:label_batch}) true_count += np.sum(predictions) step += 1 precision = true_count /total_sample_count print(‘precision @ 1 = %.3f‘ % precision)
實驗結果
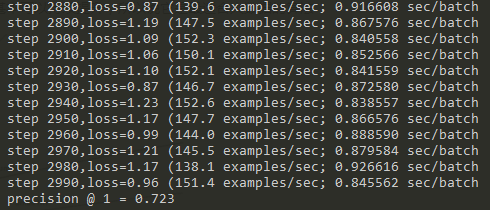
持續增加max_steps,可以期望準確率逐漸增加
總結
如果max_steps比較大,推薦使用學習速率衰減的SGD進行訓練,這樣訓練過程中能達到的準確率峰值會比較高
數據增強在訓練中作用很大,它可以給單幅圖增加多個副本,提高圖片的利用率,防止對某一張圖片結構的學習過擬合。這剛好是利用率圖片數據本身的性質,圖片的冗余信息量比較大,因此可以制造不同的噪聲並讓圖片依然可以被識別出來。如果神經網絡可以克服這些噪聲並準確識別,那麽它的泛化性能必然會很好。
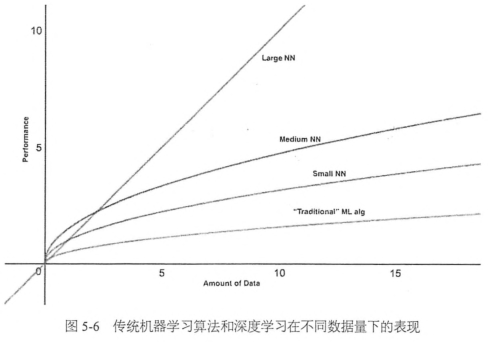
數據增強大大增加了樣本量,而數據量的大小恰恰是深度學習最看重的,深度學習可以再圖像識別上領先其他算法的一大因素就是它對海量數據的利用效率非常高。用其他算法,可能在數據量達到一定程度時,準確率就不再上升了,而深度學習只要提供足夠多的樣本,準確率基本可以持續提升,所以說它是最適合大數據的算法
前面的卷積層主要是做特征提取的工作,知道最後的全連接層才開始對特征進行組合匹配,並進行分類。
卷積層的訓練相對於全連接層更復雜,訓練全連接層基本是進行一些矩陣乘法運算,而目前卷積層的訓練基本依賴於cuDNN的實現
TensorFlow實戰--閱讀筆記part3