
TensorFlow實戰--閱讀筆記part2
一、Tensorflow編譯安裝
推薦使用Anaconda作為python環境,可以避免大量的兼容性問題
tensorflow安裝過程
以在服務器上安裝為例(linux)
1.在anaconda官網上下載與自己機器對應的版本 下載.sh形式的文件
2.在anaconda下載目錄中輸入以下路徑(下載的文件名可能不同)
$ bash Anaconda-4.2.0-Linux-x86_64.sh
3. 安裝tensorflow-cpu版本 如果要安裝gpu,請跳到第4步
推薦安裝編譯好的release版本,裝起來比較簡單 也就是直接用網上的已經編譯好的.whl文件
$ pip install--upgrade https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-1.0.0rc0-cp35-cp35m-linux_x86_64.whl
後面的網址可以到網上找相應的版本進行替換
4. 安裝tensorflow-gpu版本
需要預先安裝顯卡驅動,CUDA和cuDNN
CUDA的安裝包裏一般集成了顯卡驅動,直接在官網下載 CUDA下載 下載.run文件
註意:安裝之前先看下網上已經編譯好的tensorflow-gpu支持的CUDA和cuDNN的具體版本再安裝,這樣之後就不會出現不兼容的問題
安裝CUDA:
$ chmodu+x cuda_8.0.44_linux.run $ sudo ./cuda_8.0.44_linux.run
在安裝過程中根據提示可以自己設置安裝路徑,一般可以選擇不安裝CUDA samples,因為只是通過tensorflow調用cuda,並不需要寫cuda代碼
安裝cuDNN:
官網下載.tgz壓縮包, 並到下載路徑,輸入命令
$ sudo tar -xzvf cudnn-8.0-linux-x64-v5.1.tgz
通常是要把cuDNN的文件裏的內容全部復制到cuda-8.0的相應目錄下
設置系統環境中CUDA路徑:
$ vim ~/.bashrc 在文件底部加入 export LD_LIBRARY_PATH=/usr/local/cuda08.0/lib64:/usr/local/cuda-8.0/extras/CUPTI/lib64:$LD_LIBRARY_PATH export CUDA_HOME=/usr/local/cuda-8.0 export PATH=/usr/local/cuda-8.0/bin:$PATH 保存退出 $source ~/.bashrc
安裝tensorflow-gpu:
同樣推薦安裝編譯好的release版本,一步到位
pip install --upgrade https://storage.googleapis.com/tensorflow/linux/gpu/tensorflow_gpu-1.0.0rc0-cp35-cp35m-linux_x86_64.whl
二、Tensorflow實現softmax regression識別手寫數字
1. 下載MNIST數據:
from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets("MNIST_data/",one_hot=True)
MNIST數據集是28x28像素的圖像,這裏為了簡便,拉伸成一個784維的特征
共有55000張訓練圖片,所以訓練數據特征是一個55000x784的tensor
label是55000x10的tensor, 每一個樣本的label是相應的one-hot表示
2. 分類模型選擇softmax regression的算法,常用於多分類任務
對於後面的CNN和RNN,如果是分類模型,最後一層同樣是softmax regression,用於對每個類別進行估算概率
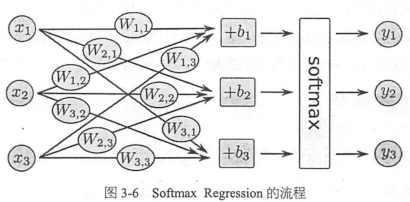
每個類別都有自己的一套W和b, b表示數據本身的一些傾向,比如大部分數字都是0,那麽0對應的bias會很大
import tensorflow as tf sess = tf.InteractiveSession() #將這個session註冊為默認的session x = tf.placeholder(tf.float32,[None,784]) #輸入數據 W = tf.Variable(tf.zeros(784,10])) b = tf.Variable(tf.zeros([10]) y = tf.nn.softmax(tf.matmul(x,W)+b)
tf.nn包含了大量神經網絡組件,tensorflow最厲害的地方不是定義公式,而是將forward和backword的內容都自動實現(無論是CPU或者GPU),只要接下來定義好loss,訓練時將會自動求導並進行梯度下降,完成對softmax regression模型參數的自動學習
3.定義loss function
對於多分類問題,通常使用cross-entropy作為loss function
y_ = tf.placeholder(tf.float32,[None,10]) #輸入正確的label cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1]))
這裏的*是element-wise乘法,只是選出正確標簽位置的相應預測概率, reduction_indices=[1]是按行加和,最後再reduce_mean對所有樣本的loss做平均
4.定義優化算法進行自動求解
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
全局初始化參數:
tf.global_variables_initializer().run()
只要定義了variables,就一定要有這麽一句,位置就放在所有變量定義之後
5.進行叠代訓練
這裏每次都隨機從訓練集中抽取100條樣本高層一個mini-batch,並feed給placeholder,然後調用train_step對這些樣本進行訓練
for i in range(1000): batch_xs, batch_ys = mnist.train.next_batch(100) train_step.run({x:batch_xs, y_:batch_ys})
完成了訓練,就可以對模型的準確率進行驗證
correct_prediction= tf.equal(tf.argmax(y,1),tf.argmax(y_,1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32)) print(accuracy.eval({x:mnist.test.images,y_:mnist.test.labels}))
tf.argmax是尋找一個向量中最大值的序號,1表示是按行找每行最大值的下標
tf.equal則是判斷預測的數字類別是否就是正確的類別,返回的是True,False矩陣
tf.cast是把True,False投射到實數上,比如True表示1,False表示0
然後tf.reduce_mean是計算所有樣本中預測正確樣本所占的比例
其實上面correct_prediction和accuracy都是定義的計算圖中的兩個節點,並沒有實際計算它們的輸出結果
所以第三行代碼accuracy.eval(feed_dict={x:mnist.test.images,y_:mnist.test.labels})才是真正的運行計算圖
註意這裏是因為使用了交互式的接口sess = tf.InteractiveSession()
所以這裏可以用node.run(feed_dict={})運行節點,node.eval(feed_dict={})計算輸出值 其他方法的話需要用sess.run(node,feed_dict={})
以上的這個簡單的算法可以達到92%的精確度,所以說神經網絡的效果很驚人
設計神經網絡流程:
- 定義算法公式,也就是神經網絡forward時的計算
- 定義loss,選定優化器,並制定優化器優化loss
- 叠代地對數據進行訓練
- 在測試集或驗證集上對準確率進行評測
定義的各個公式其實就是計算圖,在執行這行代碼時,計算還沒實際發生,只有等調用run方法,並feed數據時計算才真正執行
比如cross_entropy,train_step,accuracy等都是計算圖中的節點,不是數據結構,只有通過run方法執行這些節點才能得到計算結果
三、Tensorflow實現自編碼器
深度學習是一種無監督的特征學習,模仿了人腦的對特征逐層抽象提取的過程
早年學者研究稀疏編碼時,收集了大量黑白風景照,並提取了許多16x16的圖像碎片,他們發現幾乎所有圖像碎片都可以有64種正交邊組合得到,而且組合一張圖像碎片所需要的邊的數量是很少的,即稀疏的。同樣聲音也存在這種現象,絕大多數聲音可以有一些基本結構線性組合得到,這其實就是特征的稀疏表達,使用少量的基本特征組合拼接得到更高層抽象的特征。多層神經網絡中前一層的輸出都是未加工的項數,後一層則是對像素進行加工組織成更高階的特征(即前面提到的將邊組合成圖像碎片)
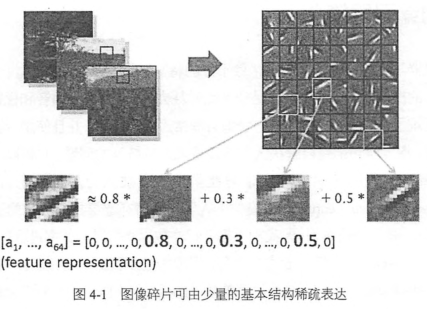
自編碼器AutoEncoder
對於沒有標註的數據,可以使用無監督的自編碼器來提取特征
自編碼器也是一種神經網絡,它的輸入和輸出是一致的,借助稀疏編碼的思想,目標是使用稀疏的一些高階特征重新組合來重構自己
特點:
- 期望輸入/輸出一致
- 希望使用高階特征來重構自己,而不是復制像素點
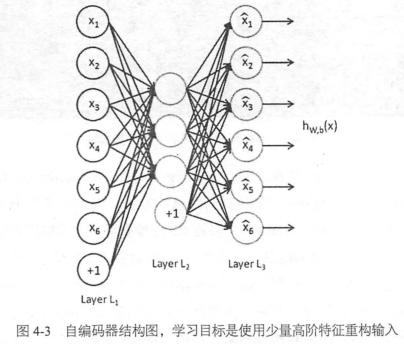
Tensorflow實現自編碼器
實現的是去噪自編碼器,給輸入加上高斯加性噪聲,希望輸出原數據
用scikit-learn中的preprocessing模塊對數據進行預處理
import numpy as np import sklearn.preprocessing as prep imiport tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data
參數初始化方法xavier initialization,根據某一層網絡中的輸入輸出節點數量自動調整為最合適的分布,滿足0均值,方差為2/(Nin+Nout),分布可以為均勻分布或者高斯分布
下面代碼設置的均勻分布,可以用公式計算方差D(x) = (max-min)^2/12 = 2/(Nin+Nout)
def xavier_init(fan_in,fan_out,constant=1): low = -constant * np.sqrt(6.0/(fan_in+fan_out)) high = constant * np.sqrt(6.0/(fan_in+fan_out)) return tf.random_uniform((fan_in,fan_out),minval=low,maxval=high,dtype=tf.float32)
下面定義一個去噪自編碼器的class
class AdditiveGaussianNoiseAutoencoder(object): def __init__(self,n_input,n_hidden,transfer_function=tf.nn.softplus, optimizer=tf.train.AdamOptimizer(),scale=0.1): # initialize the parameters self.n_input = n_input self.n_hidden = n_hidden self.transfer = transfer_function self.scale = tf.placeholder(tf.float32) self.training_scale = scale network_weights = self._initialize_weights() self.weights = network_weights # define the network architecture self.x = tf.placeholder(tf.float32,[None,self.n_input]) self.hidden = self.transfer(tf.add(tf.matmul( self.x + scale * tf.random_normal((n_input,)), self.weights[‘w1‘]),self.weights[‘b1‘])) self.reconstruction = tf.add(tf.matmul(self.hidden, self.weights[‘w2‘]),self.weights[‘b2‘]) # define loss function self.cost = 0.5 * tf.reduce_sum(tf.pow(tf.subtract( self.reconstruction,self.x),2.0)) self.optimizer = optimizer.minimize(self.cost) # run the session init = tf.global_variables_initializer() self.sess = tf.Session() self.sess.run(init) # define initialization function def _initialize_weights(self): all_weights = dict() all_weights[‘w1‘] = tf.Variable(xavier_init(self.n_input,self.n_hidden)) all_weights[‘b1‘] = tf.Variable(tf.zeros([self.n_hidden],dtype=tf.float32)) # reconstruction layer has no activate function, so can initialized by zero all_weights[‘w2‘] = tf.Variable(tf.zeros([self.n_hidden,self.n_input],dtype=tf.float32)) all_weights[‘b2‘] = tf.Variable(tf.zeros([self.n_input],dtype = tf.float32)) return all_weights # define a train step with a batch def partial_fit(self,X): cost, opt = self.sess.run((self.cost,self.optimizer), feed_dict = {self.x:X, self.scale:self.training_scale}) return cost # calculate the total cost def calc_total_cost(self,X): return self.sess.run(self.cost, feed_dict={self.x:X, self.scale:self.training_scale}) # output the hidden state of the data def transform(self,X): return self.sess.run(self.hidden,feed_dict={self.x:X, self.scale:self.training_scale}) # reconstruct data by the hidden state def generate(self,hidden=None): if hidden is None: hidden = np.random.normal(size=self.weights[‘b1‘]) return self.sess.run(self.reconstruction,feed_dict = {self.hidden:hidden}) # transform + generate input original data, output reconstructed data def reconstruct(self,X): return self.sess.run(self.reconstruction,feed_dict={self.x:X,self.scale:self.training_scale}) def getWeights(self): return self.sess.run(self.weights[‘w1‘]) def getBiases(self): return self.sess.run(self.weights[‘b1‘])
去噪自編碼器的class定義如上,其中包括神經網絡的設計,權重的初始化以及常用的成員函數
接下來用定義好的AGN自編碼器在MNIST數據集上進行一些測試看數據復原的效果如何
mnist = input_data.read_data_sets(‘MNIST_data‘,one_hot=True) # preprocess the data as 0-mean 1-std distribution # train and test should use the same scaler def standard_scale(X_train,X_test): preprocessor = prep.StandardScaler().fit(X_train) X_train = preprocessor.transform(X_train) X_test = preprocessor.transform(X_test) return X_train, X_test # define no return sampling function with a batch def get_random_block_from_data(data,batch_size): start_index = np.random.randint(0,len(data)-batch_size) return data[start_index:(start_index+batch_size)] X_train,X_test = standard_scale(mnist.train.images,mnist.test.images)
以上定義了兩個函數,一個是用來標準化數據的函數,將數據標準化到0均值,標準差為1的分布
第二個函數就是獲取一個隨機的batch_size大小block的數據,下面是實例測試:
# define parameters n_samples = int(mnist.train.num_examples) training_epochs = 20 batch_size = 128 display_step = 1 autoencoder = AdditiveGaussianNoiseAutoencoder(n_input=784, n_hidden=200,transfer_function=tf.nn.softplus, optimizer=tf.train.AdamOptimizer(learning_rate=0.001), scale=0.01) for epoch in range(training_epochs): avg_cost = 0. total_batch = int(n_samples/batch_size) for i in range(total_batch): bach_xs = get_random_block_from_data(X_train,batch_size) cost = autoencoder.partial_fit(batch_xs) avg_cost += cost / n_samples * batch_size if epoch % display_step == 0: print("Epoch:", ‘%04d‘ %(epoch+1),"cost=","{:.9f}".format(avg_cost)) print("total cost: "+str(autoencoder.calc_total_cost(X_test)))
運行結果如下:
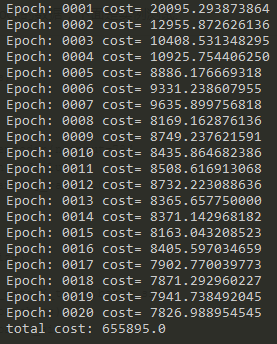
可以看到通過叠代,loss逐漸降低,說明還原效果逐漸變好
總結:
自編碼器作為一種無監督學習的方法,它與其他無監督學習的主要不同在於,它不是對數據進行聚類,而是提取其中最有用,最頻繁出現的額高階特征,根據這些高階特征重構數據。
三、Tensorflow實現多層感知機
有理論研究表明,為了擬合復雜函數需要的隱含節點的數目,基本上隨著隱含層的書領真多呈指數下降趨勢,也就是說層數越多,神經網絡所需要的隱含節點可以越少,這也是深度學習的特點之一,層數越深,概念越抽象,需要背誦的知識點(神經網絡隱含節點)就越少。
過擬合意味著泛化性能不好,模型只是記憶了當前數據的特征,不具備推廣能力,通過dropout的方式可以防止過擬合,隨機丟棄層中的節點,表示丟棄了某些特征,也是一種bagging的思想,我們可以理解為每次丟棄節點數據都是對特征的一種采樣。相當於我們訓練了一個ensemble的神經網絡模型,對每個樣本都做特征采樣。
參數難以調試也是一個大問題,有理論表示,神經網絡可能有很多個局部最優解都可以達到比較好的分類效果,而全局最優反而容易是過擬合的解
對SGD,一開始我們希望學習速率大一些,可以加速收斂,但是訓練的後期又希望學習速率可以小一點,這裏可以比較穩定地落入一個局部最優解,不同的機器學習問題所需要的學習速率也不太好設置,需要反復調試,因此就有像Adagrad,Adam,Adadelta等自適應的方法可以減輕調試參數的負擔
tensorflow實例
from tensorflow.examples.tutorials.mnist import input_data import tensorflow as tf mnist = input_data.read_data_sets("MNIST_data/",one_hot=True) sess = tf.InteractiveSession() in_units = 784 h1_units = 300 W1 = tf.Variable(tf.truncated_normal([in_units,h1_units],stddev=0.1)) b1 = tf.Variable(tf.zeros([h1_units])) W2 = tf.Variable(tf.zeros([h1_units,10])) b2 = tf.Variable(tf.zeros([10])) x = tf.placeholder(tf.float32,[None,in_units]) keep_prob = tf.placeholder(tf.float32)
下面定義網絡結構,比之前的softmax模型多了一個隱含層
# define network structure hidden1 = tf.nn.relu(tf.matmul(x,W1)+b1) hidden1_drop = tf.nn.dropout(hidden1,keep_prob) y = tf.nn.softmax(tf.matmul(hidden1_drop,W2)+b2) #define loss y_ = tf.placeholder(tf.float32,[None,10]) cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y),reduction_indices=[1])) train_step = tf.train.AdagradOptimizer(0.3).minimize(cross_entropy)
在訓練的時候,輸入dropout參數,keep_prob表示保留結點的占比,其余置0
註意在測試過程中不要進行dropout,所以keep_prob設為1
tf.global_variables_initializer().run() for i in range(3000): batch_xs,batch_ys = mnist.train.next_batch(100) train_step.run({x:batch_xs,y_:batch_ys,keep_prob:0.75}) correct_prediction= tf.equal(tf.argmax(y,1),tf.argmax(y_,1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32)) print(accuracy.eval({x:mnist.test.images,y_:mnist.test.labels,keep_prob:1.0}))
測試結果:
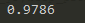
僅僅是加了一層隱含層,精確度就由92%到98%,課件多層神經網絡的效果有多顯著,同時也使用了一些trick來進行輔助,比如dropout,adagrad,relu等,但是起決定性作用的還是隱含層本身,它能對特征進行抽象和轉化
沒有隱含層的softmax regression只能直接從圖像的額像素點推斷是哪個數字,而沒有特征抽象的過程。多層神經網絡依靠隱含層,這可以組合出高階特征,比如橫線,豎線,圓圈等,之後可以將這些高階特征或者說組件再組合成數字,就能實現精準地匹配和分類。隱含層輸出的高階特征經常是可以復用額,所以每一類的判別,概率輸出都共享這些高階特征,而不是個字連接獨立的高階特征
TensorFlow實戰--閱讀筆記part2