
EM 最大似然概率估計
轉載請註明出處 Leavingseason http://www.cnblogs.com/sylvanas2012/p/5053798.html
EM框架是一種求解最大似然概率估計的方法。往往用在存在隱藏變量的問題上。我這裏特意用"框架"來稱呼它,是因為EM算法不像一些常見的機器學習算法例如logistic regression, decision tree,只要把數據的輸入輸出格式固定了,直接調用工具包就可以使用。可以概括為一個兩步驟的框架:
E-step:估計隱藏變量的概率分布期望函數(往往稱之為Q函數 ,它的定義在下面會詳細給出);
,它的定義在下面會詳細給出);
M-step:求出使得Q函數最大的一組參數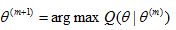
實際使用過程中,我們先要根據不同的問題先推導出Q函數,再套用E-M兩步驟的框架。
下面來具體介紹為什麽要引入EM算法?
不妨把問題的全部變量集(complete data)標記為X,可觀測的變量集為Y,隱藏變量集為Z,其中X = (Y , Z) . 例如下圖的HMM例子, S是隱變量,Y是觀測值:

又例如,在GMM模型中(下文有實例) ,Y是所有觀測到的點,z_i 表示 y_i 來自哪一個高斯分量,這是未知的。
問題要求解的是一組參數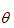 , 使得
, 使得 最大。在求最大似然時,往往求的是對數最大:
最大。在求最大似然時,往往求的是對數最大:  (1)
(1)
對上式中的隱變量做積分(求和):
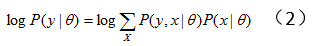
(2)式往往很難直接求解。於是產生了EM方法,此時我們想要最大化全變量(complete data)X的對數似然概率 :假設我們已經有了一個模型參數
:假設我們已經有了一個模型參數
 的期望函數,然後解出使得期望函數最大的
的期望函數,然後解出使得期望函數最大的 值,作為更新的
值,作為更新的 參數。基於這個更新的再重復計算X的概率分布,以此叠代。流程如下:
參數。基於這個更新的再重復計算X的概率分布,以此叠代。流程如下:
Step 1: 隨機選取初始值
Step 2:給定![]() 和觀測變量Y, 計算條件概率分布
和觀測變量Y, 計算條件概率分布
Step 3:在step4中我們想要最大化,但是我們並不完全知道X(因為有一些隱變量),所以我們只好最大化的期望值, 而X的概率分布也在step 2 中計算出來了。所以現在要做的就是求期望,也稱為Q函數:
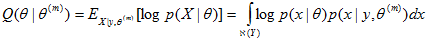
其中,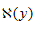 表示給定觀測值y時所有可能的x取值範圍,即
表示給定觀測值y時所有可能的x取值範圍,即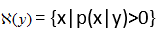
Step 4 求解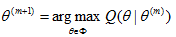
Step 5 回到step 2, 重復叠代下去。
為什麽要通過引入Q函數來更新theta的值呢?因為它和我們的最大化終極目標(公式(1))有很微妙的關系:
定理1:
證明:在step4中,既然求解的是arg max, 那麽必然有 。於是:
。於是:

其中,(3)到(4)是因為X=(Y , Z), y=T(x), T是某種確定函數,所以當x確定了,y也就確定了(但反之不成立);即:  而(4)中的log裏面項因為不包含被積分變量x,所以可以直接提到積分外面。
而(4)中的log裏面項因為不包含被積分變量x,所以可以直接提到積分外面。
所以E-M算法的每一次叠代,都不會使目標值變得更差。但是EM的結果並不能保證是全局最優的,有可能收斂到局部最優解。所以實際使用中還需要多取幾種初始值試驗。
實例:高斯混合模型GMM
假設從一個包含k個分量的高斯混合模型中隨機獨立采樣了n個點 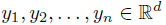 , 現在要估計所有高斯分量的參數
, 現在要估計所有高斯分量的參數 。 例如圖(a)就是一個k=3的一維GMM。
。 例如圖(a)就是一個k=3的一維GMM。

高斯分布函數為:

令 為第m次叠代時,第i個點來自第j個高斯分量的概率,那麽:
為第m次叠代時,第i個點來自第j個高斯分量的概率,那麽:
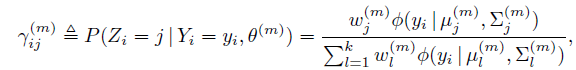 並且
並且 
因為每個點是獨立的,不難證明有:

於是首先寫出每個 :
:

忽略常數項,求和,完成E-step:

為簡化表達,再令 ,
,
Q函數變為:
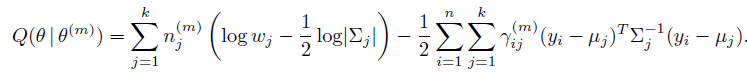
現在到了M-step了,我們要解出使得Q函數最大化的參數。最簡單地做法是求導數為0的值。
首先求w。 因為w有一個約束:

可以使用拉格朗日乘子方法。 除去和w無關的項,寫出新的目標函數:
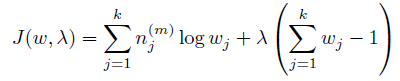
求導:
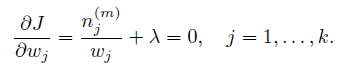
很容易解出w:

同理解出其他參數:



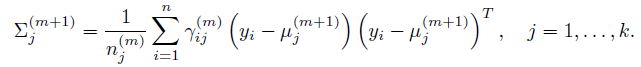
總結:個人覺得,EM算法裏面最難懂的是Q函數。初次看教程的時候, 很能迷惑人,要弄清楚是變量,是需要求解的;
很能迷惑人,要弄清楚是變量,是需要求解的; 是已知量,是從上一輪叠代推導出的值。
是已知量,是從上一輪叠代推導出的值。
EM 最大似然概率估計