
Elasticsearch教程
各位運維同行朋友們,大家好,非常高興能有這麽個機會與大家一起交流一些技術問題。此前的各位分享達人們在技術領域或管理領域均有十分精彩的分享,他們帶給我們的是多個領域中研究或實踐的最前沿知識。這使我本人獲益良多,首先要鄭重感謝他們。
1、搜索引擎組件介紹;
2、ElasticSearch工作原理、查詢及常用插件;
3、日誌收集器Logstash及常見的同類工具;
4、可視化工具Kibina;
5、使用案例及優化思路;
一、關於搜索引擎
各位知道,搜索程序一般由索引鏈及搜索組件組成。
索引鏈功能的實現需要按照幾個獨立的步驟依次完成:檢索原始內容、根據原始內容來創建對應的文檔、對創建的文檔進行索引。
搜索組件用於接收用戶的查詢請求並返回相應結果,一般由用戶接口、構建可編程查詢語句的方法、查詢語句執行引擎及結果展示組件組成。
如圖所示。

著名的開源程序Lucene是為索引組件,它提供了搜索程序的核心索引和搜索模塊,例如圖中的“Index”及下面的部分;而ElasticSearch則更像一款搜索組件,它利用Lucene進行文檔索引,並向用戶提供搜索組件,例如“Index”上面的部分。二者結合起來組成了一個完整的搜索引擎。
二、索引組件
索引是一種數據結構,它允許對存儲在其中的單詞進行快速隨機訪問。當需要從大量文本中快速檢索文本目標時,必須首先將文本內容轉換成能夠進行快速搜索的格式,以建立針對文本的索引數據結構,此即為索引過程。
它通常由邏輯上互不相關的幾個步驟組成。
第一步:獲取內容。
過網絡爬蟲或蜘蛛程序等來搜集及界定需要索引的內容。Lucene並不提供任何獲取內容的組件,因此,需要由其它應用程序負責完成這一功能,例如著名的開源爬蟲程序Solr、Nutch、Grub及Aperture等。必要時,還可以自行開發相關程序以高效獲取自有的特定環境中的數據。獲取到的內容需要建立為小數據塊,即文檔(Document)。
第二步:建立文檔。
獲取的原始內容需要轉換成專用部件(文檔)才能供搜索引擎使用。
一般來說,一個網頁、一個PDF文檔、一封郵件或一條日誌信息可以作為一個文檔。文檔由帶“值(Value)”的“域(Field)”組成,例如標題(Title)、正文(body)、摘要(abstract)、作者(Author)和鏈接(url)等。不過,二進制格式的文檔處理起來要麻煩一些,例如PDF文件。
對於建立文檔的過程來說有一個常見操作:向單個的文檔和域中插入加權值,以便在搜索結果中對其進行排序。權值可在索引操作前靜態生成,也可在搜索期間才動態生成。權值決定了其搜索相關度。
第三步:文檔分析。
搜索引擎不能直接對文本進行索引,確切地說,必須首先將文本分割成一系列被稱為語匯單元(token)的獨立原子元素,此過程即為文檔分析。每個token大致能與自然語言中的“單詞”對應起來,文檔分析就是用於確定文檔中的文本域如何分割成token序列。
此即為切詞,或分詞。
文檔分析中要解決的問題包括如何處理連接一體的各個單詞、是否需要語法修正(例如原始內容存在錯別字)、是否需要向原始token中插入同義詞(例如laptop和notebook)、是否需要將大寫字符統一轉換為小寫字符,以及是否將單數和復數格式的單詞合並成同一個token等。這通常需要詞幹分析器等來完成此類工作,Lucene提供了大量內嵌的分析器,也支持用戶自定義分析器,甚至聯合Lucene的token工具和過濾器創建自定義的分析鏈。
第四步:文檔索引
在索引步驟中,文檔將被加入到索引列表。事實上,Lucene為此僅提供了一個非常簡單的API,而後自行內生地完成了此步驟的所有功能。
接下來,我們說搜索組件。
索引處理就是從索引中查找單詞,從而找到包含該單詞的文檔的過程。搜索質量主要由查準率(Precision)和查全率(Recall)兩個指標進行衡量。查準率用來衡量搜索系列過濾非相關文檔的能力,而查全率用來衡量搜索系統查找相關文檔的能力。
另外,除了快速搜索大量文本和搜索速度之後,搜索過程還涉及到了許多其它問題,例如單項查詢、多項查詢、短語查詢、通配符查詢、結果ranking和排序,以及友好的查詢輸入方式等。這些問題的解決,通常需要多個組件協作完成。
1、用戶搜索界面
UI(User Interface)是搜索引擎的重要組成部分,用戶通過搜索引擎界面進行搜索交互時,他們會提交一個搜索請求,該請求需要先轉換成合適的查詢對象格式,以便搜索引擎能執行查詢。
2、建立查詢
戶提交的搜索請求通常以HTML表單或Ajax請求的形式由瀏覽器提交到搜索引擎服務器,因此,需要事先由查詢解析器一類的組件將這個請求轉換成搜索引擎使用的查詢對象格式。
3、搜索查詢
當查詢請求建立完成後,就需要查詢檢索索引並返回與查詢語句匹配的並根據請求排好序的文檔。搜索查詢組件有著復雜的工作機制,它們通常根據搜索理論模型執行查詢操作。常見的搜索理論模型有純布爾模型、向量空間模型及概率模型三種。Lucene采用了向量空間模型和純布爾模型。
4、展現結果
查詢獲得匹配查詢語句並排好序的文檔結果集後,需要用直觀、經濟的方式為用戶展現結果。UI也需要為後續的搜索或操作提供清晰的向導,如完善搜索結果、尋找與匹配結果相似的文檔、進入下一頁面等。
三、Lucene
Lucene是一款高性能的、可擴展的信息檢索(IR)工具庫,是由Java語言開發的成熟、自由開源的搜索類庫,基於Apache協議授權。Lucene只是一個軟件類庫,如果要發揮Lucene的功能,還需要開發一個調用Lucene類庫的應用程序。
文檔是Lucene索引和搜索的原子單位,它是包含了一個或多個域的容器,而域的值則是真正被搜索的內容。每個域都有其標識名稱,通常為一個文本值或二進制值。將文檔加入索引中時,需要首先將數據轉換成Lucene能識別的文檔和域,域值是被搜索的對象。例如,用戶輸入搜索內容“title:elasticsearch”時,則表示搜索“標題”域值中包含單詞“elasticsearch”的所有文檔。
都是文字,大家可能看的眼花。參考一幅從互聯網上獲取的圖片吧。

如前所述,ElasticSearch在底層利用Lucene完成其索引功能,因此其許多基本概念源於Lucene。
四、ES的基本概念
索引(Index)
ES將數據存儲於一個或多個索引中,索引是具有類似特性的文檔的集合。類比傳統的關系型數據庫領域來說,索引相當於SQL中的一個數據庫,或者一個數據存儲方案(schema)。索引由其名稱(必須為全小寫字符)進行標識,並通過引用此名稱完成文檔的創建、搜索、更新及刪除操作。一個ES集群中可以按需創建任意數目的索引。
類型(Type)
類型是索引內部的邏輯分區(category/partition),然而其意義完全取決於用戶需求。因此,一個索引內部可定義一個或多個類型(type)。一般來說,類型就是為那些擁有相同的域的文檔做的預定義。例如,在索引中,可以定義一個用於存儲用戶數據的類型,一個存儲日誌數據的類型,以及一個存儲評論數據的類型。類比傳統的關系型數據庫領域來說,類型相當於“表”。
文檔(Document)
文檔是Lucene索引和搜索的原子單位,它是包含了一個或多個域的容器,基於JSON格式進行表示。文檔由一個或多個域組成,每個域擁有一個名字及一個或多個值,有多個值的域通常稱為“多值域”。每個文檔可以存儲不同的域集,但同一類型下的文檔至應該有某種程度上的相似之處。
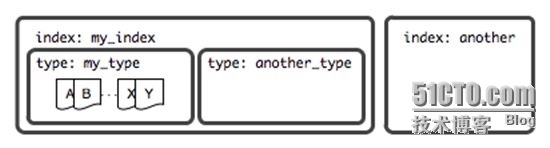
三者關系,如圖中所示。
映射(Mapping)
ES中,所有的文檔在存儲之前都要首先進行分析。用戶可根據需要定義如何將文本分割成token、哪些token應該被過濾掉,以及哪些文本需要進行額外處理等等。另外,ES還提供了額外功能,例如將域中的內容按需排序。事實上,ES也能自動根據其值確定域的類型。

節點(Node)
運行了單個實例的ES主機稱為節點,它是集群的一個成員,可以存儲數據、參與集群索引及搜索操作。類似於集群,節點靠其名稱進行標識,默認為啟動時自動生成的隨機Marvel字符名稱。用戶可以按需要自定義任何希望使用的名稱,但出於管理的目的,此名稱應該盡可能有較好的識別性。節點通過為其配置的ES集群名稱確定其所要加入的集群。
分片(Shard)和副本(Replica)
ES的“分片(shard)”機制可將一個索引內部的數據分布地存儲於多個節點,它通過將一個索引切分為多個底層物理的Lucene索引完成索引數據的分割存儲功能,這每一個物理的Lucene索引稱為一個分片(shard)。每個分片其內部都是一個全功能且獨立的索引,因此可由集群中的任何主機存儲。創建索引時,用戶可指定其分片的數量,默認數量為5個。
Shard有兩種類型:primary和replica,即主shard及副本shard。Primary shard用於文檔存儲,每個新的索引會自動創建5個Primary shard,當然此數量可在索引創建之前通過配置自行定義,不過,一旦創建完成,其Primary shard的數量將不可更改。Replica shard是Primary Shard的副本,用於冗余數據及提高搜索性能。每個Primary shard默認配置了一個Replica shard,但也可以配置多個,且其數量可動態更改。ES會根據需要自動增加或減少這些Replica shard的數量。
ES集群可由多個節點組成,各Shard分布式地存儲於這些節點上。
ES可自動在節點間按需要移動shard,例如增加節點或節點故障時。簡而言之,分片實現了集群的分布式存儲,而副本實現了其分布式處理及冗余功能。
如圖所示。

ElasticSearch的RESTful API通過tcp協議的9200端口提供,可通過任何趁手的客戶端工具與此接口進行交互,這其中包括最為流行的curl。curl與ElasticSearch交互的通用請求格式如下面所示。
| 1 2 3 4 5 6 7 |
curl -X<VERB> ‘<PROTOCOL>://<HOST>/<PATH>?<QUERY_STRING>‘ -d ‘<BODY>‘
VERB:HTTP協議的請求方法,常用的有GET、POST、PUT、HEAD以及DELETE;
PROTOCOL:協議類型,http或https;
HOST:ES集群中的任一主機的主機名;
PORT:ES服務監聽的端口,默認為9200;
QUERY_STRING:查詢參數,例如?pretty表示使用易讀的JSON格式輸出;
BODY:JSON格式的請求主體;
|
例如,查看ElasticSearch工作正常與否的信息。
| 1 |
~]$ curl ‘http://localhost:9200/?pretty‘
|
與ElasticSearch集群交互時,其輸出數據均為JSON格式,多數情況下,此格式的易讀性較差。cat API會在交互時以類似於Linux上cat命令的格式對結果進行逐行輸出,因此有著較JSON好些的可讀性。調用cat API僅需要向“_cat”資源發起GET請求即可。具體使用方法請查閱官方文檔。
另外,ES集群的CRUD操作也非常容易進行,朋友們參考官方文檔即可。
五、ES中的數據查詢簡介
需要註意的是,文檔中每個域的值可能會存儲為特定類型,而非字符串類型,因此,_all域的索引方式與特域的索引方式未必完全相同。
文檔中,域的數據存儲時支持“string”、“numbers”、“Booleans”和“dates”幾種類型,不同類型的數據在索引時是略有區別的。在創建文檔時,Elasticsearch會通過檢查域的值來動態為其創建mapping,可通過Mapping API來查看type的mapping,其訪問端點是_mapping。
下面,我們聊一個麻煩一點的問題,ES的精確值、full-text及倒排索引。
精確值(Exact values)就是指數據未曾加工過的原始值,而Full-text則用於引用文本中的數據。在查詢中,精確值是很容易進行搜索的,但full-text則需要判斷文檔在“多大程度上”匹配查詢請求,換句話講,即需要評估文檔與給定查詢的相關度(relevant)。因此,所謂的full-text查詢通常是指在給定的文本域內部搜索指定的關鍵字,但搜索操作該需要真正理解查詢者的目的。
例如:
(1) 搜索“UK”應該返回包含“United Kingdom”的相關文檔;
(2) 搜索“jump”應該返回包含“JUMP”、“jumped”、“jumps”、“jumping”甚至是“leap”的文檔;
(3) 搜索“johnny walker”應該匹配包含“Johnnie Walker”的文檔;
為了完成此類full-text域的搜索,ES必須首先分析文本並將其構建成為倒排索引(inverted index),倒排索引由各文檔中出現的單詞列表組成,列表中的各單詞不能重復且需要指向其所在的各文檔。因此,為了創建倒排索引,需要先將各文檔中域的值切分為獨立的單詞(也稱為term或token),而後將之創建為一個無重復的有序單詞列表。這個過程稱之為“分詞(tokenization)”。
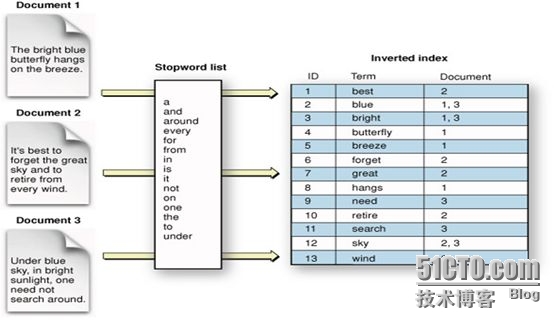
六、Queries and Filters
盡管統一稱之為query DSL,事實上Elasticsearch中存在兩種DSL:查詢DSL(query DSL)和過濾DSL(filter DSL)。查詢子句和過濾子句的自然屬性非常相近,但在使用目的上略有區別。簡單來講,當執行full-text查詢或查詢結果依賴於相關度分值時應該使用查詢DSL,當執行精確值(extac-value)查詢或查詢結果僅有“yes”或“no”兩種結果時應該使用過濾DSL。
Filter DSL計算及過濾速度較快,且適於緩存,因此可有效提升後續查詢請求的執行速度。而query DSL不僅要查找匹配的文檔,還需要計算每個文件的相關度分值,因此為更重量級的查詢,其查詢結果不會被緩存。不過,得益於倒排索引,一個僅返回少量文檔的簡單query或許比一個跨數百萬文檔的filter執行起來並得顯得更慢。
Filter DSL中常見的有term Filter、terms Filter、range Filter、exists and missing Filters和bool Filter。而Query DSL中常見的有match_all、match 、multi_match及bool Query。鑒於時間關系,這裏不再細述,朋友們可參考官方文檔學習。
Queries用於查詢上下文,而filters用於過濾上下文,不過,Elasticsearch的API也支持此二者合並運行。組合查詢可用於合並查詢子句,組合過濾用於合並過濾子句,然而,Elasticsearch的使用習慣中,也常會把filter用於query上進行過濾。不過,很少有機會需要把query用於filter上的。
原博主:平和的心 請多多關註噶
Elasticsearch教程