ES篇:ElasticSearch教程——建立索引、型別、文件
ES知識彙總:https://blog.csdn.net/gwd1154978352/article/details/82781731
介紹
- 索引是ElasticSearch存放資料的地方,可以理解為關係型資料庫中的一個數據庫。事實上,我們的資料被儲存和索引在分片(shards)中,索引只是一個把一個或多個分片分組在一起的邏輯空間。然而,這只是一些內部細節——我們的程式完全不用關心分片。對於我們的程式而言,文件儲存在索引(index)中。剩下的細節由Elasticsearch關心既可。(索引的名字必須是全部小寫,不能以下劃線開頭,不能包含逗號)
- 型別用於區分同一個索引下不同的資料型別,相當於關係型資料庫中的表。在Elasticsearch中,我們使用相同型別(type)的文件表示相同的“事物”,因為他們的資料結構也是相同的。每個型別(type)都有自己的對映(mapping)或者結構定義,就像傳統資料庫表中的列一樣。所有型別下的文件被儲存在同一個索引下,但是型別的對映(mapping)會告訴Elasticsearch不同的文件如何被索引。
- 文件是ElasticSearch中儲存的實體,類比關係型資料庫,每個文件相當於資料庫表中的一行資料。 在Elasticsearch中,文件(document)這個術語有著特殊含義。它特指最頂層結構或者根物件(root object)序列化成的JSON資料(以唯一ID標識並存儲於Elasticsearch中)。
- 文件由欄位組成,相當於關係資料庫中列的屬性,不同的是ES的不同文件可以具有不同的欄位集合。
對比關係型資料庫:
Relational DB -> Databases -> Tables -> Rows -> Columns Elasticsearch -> Indices -> Types -> Documents -> Fields
文件元資料
一個文件不只有資料。它還包含了元資料(metadata)——關於文件的資訊。三個必須的元資料節點是:
| 節點 | 說明 |
|---|---|
_index |
文件儲存的地方 |
_type |
文件代表的物件的類 |
_id |
文件的唯一標識 |
_type:型別
_id:id僅僅是一個字串,它與_index和_type組合時,就可以在Elasticsearch中唯一標識一個文件。當建立一個文件,你可以自定義_id
索引建立原則
- 類似的資料放在一個索引,非類似的資料放不同索引:product index(包含了所有的商品),sales index(包含了所有的商品銷售資料),inventory index(包含了所有庫存相關的資料)。如果你把比如product,sales,human resource(employee),全都放在一個大的index裡面,比如說company index,不合適的。
- index中包含了很多類似的document:類似是什麼意思,其實指的就是說,這些document的fields很大一部分是相同的,你說你放了3個document,每個document的fields都完全不一樣,這就不是類似了,就不太適合放到一個index裡面去了。
- 索引名稱必須是小寫的,不能用下劃線開頭,不能包含逗號:product,website,blog
建立索引、型別、文件(介面的方式)
以kibana的方式操作ES的可以檢視ElasticSearch教程——Kibana簡單操作ES
以部落格內容管理為例,索引名為blog,型別為article,自定義id是“1”,新加一個文件:
curl -H 'Content-Type:application/json' -XPUT http://localhost:9200/blog/article/1 -d '
{
"id": "1",
"title": "New version of Elasticsearch released!",
"content": "Version 1.0 released today!",
"priority": 10,
"tags": ["announce", "elasticsearch", "release"]
}'自增ID
當我們想要一個自增ID的時候,直接不用設定id即可,即原來是把文件儲存到某個ID對應的空間,現在是把這個文件新增到某個_type下(注意:這邊是POST不是PUT)
curl -H 'Content-Type:application/json' -XPOST http://localhost:9200/blog/article/ -d '
{
"title": "New version of Elasticsearch released!",
"content": "Version 1.0 released today!",
"priority": 10,
"tags": ["announce", "elasticsearch", "release"]
}'返回結果:
{
"_index": "blog",
"_type": "article",
"_id": "eTmX5mUBtZGWutGW0TNs",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}自動生成的id,長度為20個字元,URL安全,base64編碼,GUID,分散式系統並行生成時不可能會發生衝突。
檢索文件
在對應的瀏覽器位址列輸入如下地址
http://XXX.XXX.XXX.XX:9200/blog/article/1?pretty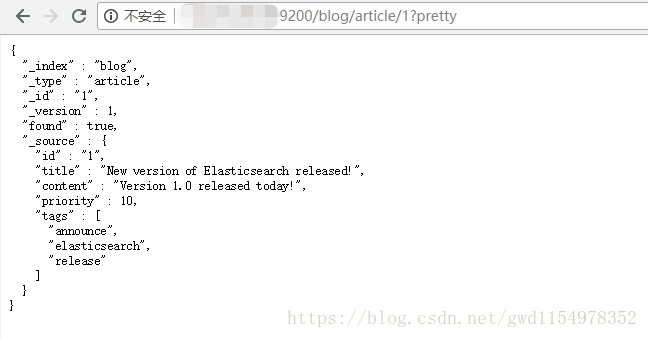
或者在Linux中使用如下指令碼:
curl -H 'Content-Type:application/json' -XGET http://localhost:9200/blog/article/1?pretty
響應包含了現在熟悉的元資料節點,增加了_source欄位,它包含了在建立索引時我們傳送給Elasticsearch的原始文件。
pretty:在任意的查詢字串中增加pretty引數,類似於上面的例子。會讓Elasticsearch美化輸出(pretty-print)JSON響應以便更加容易閱讀。
_source欄位不會被美化,它的樣子與我們輸入的一致,現在只包含我們請求的欄位,而且過濾了date欄位。
或者你只想得到_source欄位而不要其他的元資料,你可以這樣請求:
curl -H 'Content-Type:application/json' -XGET http://localhost:9200/blog/article/1/_source返回結果:
{
"id": "1",
"title": "New version of Elasticsearch released!",
"content": "Version 1.0 released today!",
"priority": 10,
"tags": ["announce", "elasticsearch", "release"]
}請求返回的響應內容包括{"found": true}。這意味著文件已經找到。如果我們請求一個不存在的文件,依舊會得到一個JSON,不過found值變成了false。此外,HTTP響應狀態碼也會變成'404 Not Found'代替'200 OK'。我們可以在curl後加-i引數得到響應頭:
curl -H 'Content-Type:application/json' -i -XGET http://localhost:9200/blog/article/1?pretty顯示結果:
HTTP/1.1 200 OK
content-type: application/json; charset=UTF-8
content-length: 337
{
"_index" : "blog",
"_type" : "article",
"_id" : "1",
"_version" : 1,
"found" : true,
"_source" : {
"id" : "1",
"title" : "New version of Elasticsearch released!",
"content" : "Version 1.0 released today!",
"priority" : 10,
"tags" : [
"announce",
"elasticsearch",
"release"
]
}
}更新文件
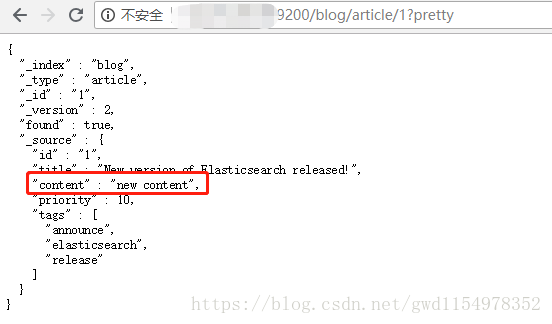
curl -H 'Content-Type:application/json' -XPOST http://localhost:9200/blog/article/1/_update -d '{
"script": "ctx._source.content = \"new content\""
}'
刪除文件
curl -XDELETE http://localhost:9200/blog/article/1