
BAYES和樸素BAYES
0 前言
本文主要利用貝葉斯對缺失值不敏感這一優點,處理數據。
1 貝葉斯和樸素貝葉斯
2 原理實現和編程
R語言中可以使用bnlearn包來對貝葉斯網絡進行建模。但要註意的是,bnlearn包不能處理混合數據,所以先將連續數據進行離散化(因子型),再進行建模訓練。
(我之前犯過這個錯誤,就是把混合數據直接建模訓練,得出結果為空,還茫然不知所措。。。)

圖片來源:https://blog.csdn.net/sinat_26917383/article/details/51569573
此外還有自助法(bootstrap),交叉驗證(cross-validation)和隨機模擬(stochastic simulation)等功能,附加的繪圖功能需要調用 Rgraphviz and lattice 包。
3 總結
參考文獻
BAYES和樸素BAYES
相關推薦
BAYES和樸素BAYES
tps 參考 合數 OS learn inf 不能 nbsp 錯誤 0 前言 本文主要利用貝葉斯對缺失值不敏感這一優點,處理數據。 1 貝葉斯和樸素貝葉斯 2 原理實現和編程 R語言中可以使用bnlearn包來對貝葉斯網絡進行建模。但要註意的是
機器學習2:Naive Bayes(樸素貝葉斯)
參考:https://blog.csdn.net/syoya1997/article/details/78618885貝葉斯模型的講解 貝葉斯模型 ,二分類中展開為 P(H) – 已知的先驗概率 P(H|E) – 我們想求的後驗概率,即在B事件發生後對於事件A概率的評估
Naive Bayes(樸素貝葉斯)
Naive Bayes Bayes’ theorem(貝葉斯法則) 在概率論和統計學中,Bayes’ theorem(貝葉斯法則)根據事件的先驗知識描述事件的概率。貝葉斯法則表示式如下所示: P(A|B)=P(B|A)P(A)P(B)(1)(1)P
python實現隨機森林、邏輯回歸和樸素貝葉斯的新聞文本分類
ati int ces 平滑 讀取 inf dict http tor 實現本文的文本數據可以在THUCTC下載也可以自己手動爬蟲生成, 本文主要參考:https://blog.csdn.net/hao5335156/article/details/82716923 nb表
(二)貝葉斯和樸素貝葉斯
1、貝葉斯公式 P(Y|X)=P(X|Y)P(Y)P(X) P ( Y |
貝葉斯和樸素貝葉斯,傻瓜式筆記
目標是調參大師!首先要明白自己在調什麼 貝葉斯定理(抄自資料探勘概念與技術(例子部分有篡改)):設X是資料元組。在貝葉斯的術語中,X看做證據。通常,X用n個屬性集的測量值描述(特徵)。令H為某種假設,如資料元組X屬於某個特定類C。對於分類問題,希望確定給定證據或觀測資料元組X,假設H成立的概
貝葉斯公式和樸素貝葉斯分類演算法
先上問題吧,我們統計了14天的氣象資料(指標包括outlook,temperature,humidity,windy),並已知這些天氣是否打球(play)。如果給出新一天的氣象指標資料:sunny,cool,high,TRUE,判斷一下會不會去打球。 table 1 outlook temperat
邏輯迴歸和樸素貝葉斯演算法實現二值分類(matlab程式碼)
資料簡介:共有306組資料,每組資料有三個屬性(x1,x2,x2),屬於0類或者1類。 資料序號末尾為1的是測試集,有31組;其他的作為訓練集,有275組。 clear clc load('
jieba和樸素貝葉斯實現文字分類
#盜取男票年輕時候的程式碼,現在全給我教學使用了,感恩臉#分類文件為多個資料夾 資料夾是以類別名命名 內含多個單個文件#coding: utf-8 from __future__ import print_function, unicode_literals import
LDA和樸素貝葉斯相結合---影象分類
b)用判別結構對測試樣本分類; %以下用NaiveBayes準則進行分類測試 % 測試過程 testsamples = []; %所有測試樣本M*10304, M= nclass*ntest for i = 1 : nclass for j = ntrain+1 : ntrain+ntest
生成模型中的高斯判別分析和樸素貝葉斯
設樣本為X(大寫X表示向量),其類別為y。下面的圖片若非特殊宣告,均來自cs229 Lecture notes 2。 用於分類的機器學習演算法可以分為兩種:判別模型(Discriminative learning algorithms)和生成模型(Generative Le
邏輯迴歸 和 樸素貝葉斯 兩者間的區別
在有監督學習演算法用做分類問題時,有兩種演算法在實際中應用廣泛,它們分別是Logistic regression和Naive bayes。今天我們討論一下這兩類演算法在分類問題上面的異同點,以及它們的優缺點。 1.兩類演算法介紹 Logistic Regressio
決策樹模型(Decision TreeModel)和樸素貝葉斯模型(NaiveBayesianModel,NBC)
貝葉斯分類器的分類原理是通過某物件的先驗概率,利用貝葉斯公式計算出其後驗概率,即該物件屬於某一類的概率,選擇具有最大後驗概率的類作為該物件所屬的類。目前研究較多的貝葉斯分類器主要有四種,分別是:NaiveBayes、TAN、BAN和GBN。應用貝葉斯網路分類器進行分類主要
貝葉斯和樸素貝葉斯是啥
[toc] # 一、貝葉斯 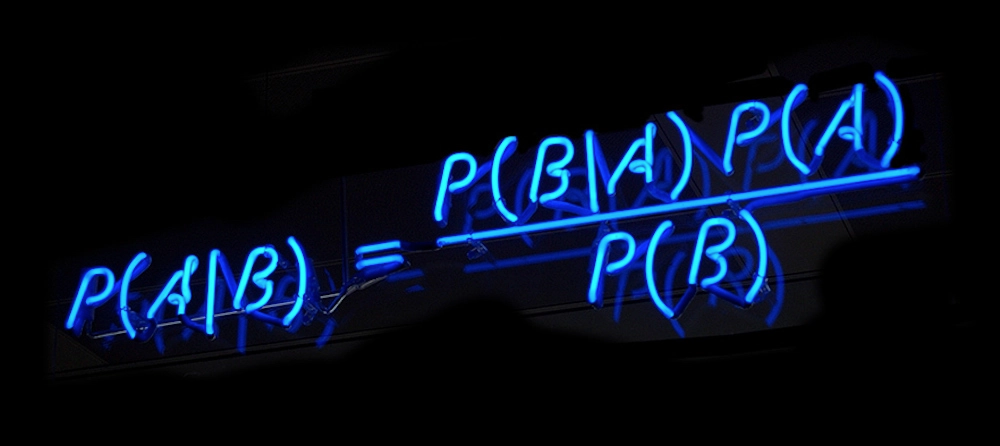 簡單地說,貝葉斯就是貝yes,見到貝克漢姆說了一句yes,研究的是這種概率事件。 開玩笑啦,貝
樸素貝葉斯(Naive Bayes)分類和Gaussian naive Bayes
樸素貝葉斯(Naive Bayes) 參考資料:https://www.cnblogs.com/pinard/p/6069267.html 樸素貝葉斯最關鍵的就是 (強制認為每種指標都是獨立的)。 不同於其它分類器,樸素貝葉斯是一種基於概率理論的分類
利用樸素貝葉斯(Navie Bayes)進行垃圾郵件分類
判斷 ase create numpy water 向量 not in imp img 貝葉斯公式描寫敘述的是一組條件概率之間相互轉化的關系。 在機器學習中。貝葉斯公式能夠應用在分類問題上。這篇文章是基於自己的學習所整理。並利用一個垃圾郵件分類的樣例來加深對於理論的理解
樸素貝葉斯分類器的應用 Naive Bayes classifier
upload dia get 等號 分布 eat 實現 維基 5.5 一、病人分類的例子 讓我從一個例子開始講起,你會看到貝葉斯分類器很好懂,一點都不難。 某個醫院早上收了六個門診病人,如下表。 癥狀 職業 疾病 打噴嚏 護士 感冒 打噴嚏
【黎明傳數==>機器學習速成寶典】模型篇05——樸素貝葉斯【Naive Bayes】(附python代碼)
pytho res tex 機器學習 樸素貝葉斯 spa 什麽 之一 類別 目錄 先驗概率與後驗概率 什麽是樸素貝葉斯 模型的三個基本要素 構造kd樹 kd樹的最近鄰搜索 kd樹的k近鄰搜索 Python代碼(sklearn庫) 先
【Spark MLlib速成寶典】模型篇04樸素貝葉斯【Naive Bayes】(Python版)
width pla evaluate 特征 mem order 一個數 ble same 目錄 樸素貝葉斯原理 樸素貝葉斯代碼(Spark Python) 樸素貝葉斯原理 詳見博文:http://www.cnblogs.com/itmor
機器學習---樸素貝葉斯分類器(Machine Learning Naive Bayes Classifier)
垃圾郵件 垃圾 bubuko 自己 整理 href 極值 multi 帶來 樸素貝葉斯分類器是一組簡單快速的分類算法。網上已經有很多文章介紹,比如這篇寫得比較好:https://blog.csdn.net/sinat_36246371/article/details/601