
TensorFlow 框架
TensorFlow
TensorFlow核心程序由2個獨立部分組成:
a:Building the computational graph構建計算圖 b:Running the computational graph運行計算圖 1.一個computational graph(計算圖)是一系列的TensorFlow操作排列成一個節點圖。 1.1 構建計算圖node1 = tf.constant(3.0, dtype=tf.float32) node2 = tf.constant(4.0)# also tf.float32 implicitly print(node1, node2)
結果:
Tensor("Const:0", shape=(), dtype=float32) Tensor("Const_1:0",shape=(), dtype=float32)
1.2運行計算圖
我們必須用到session:一個session封裝了TensorFlow運行時的控制和狀態
sess = tf.Session() print(sess.run([node1, node2]))
1.3 我們可以組合Tensor節點操作(操作仍然是一個節點)來構造更加復雜的計算,
node3 = tf.add(node1, node2) print("node3:", node3)print("sess.run(node3):", sess.run(node3))
運行結果:
node3:Tensor("Add:0", shape=(), dtype=float32) sess.run(node3):7.0
1.4 TensorFlow提供一個統一的調用稱之為TensorBoard,它能展示一個計算圖的圖片;如下面這個截圖就展示了這個計算圖
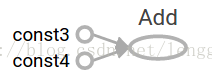 1.5 一個計算圖可以參數化的接收外部的輸入,作為一個placeholders(占位符),一個占位符是允許後面提供一個值的。
1.5 一個計算圖可以參數化的接收外部的輸入,作為一個placeholders(占位符),一個占位符是允許後面提供一個值的。
a = tf.placeholder(tf.float32) b = tf.placeholder(tf.float32) adder_node這裏有點像一個function (函數)或者lambda表達式,我們定義了2個輸入參數a和b,然後提供一個在它們之上的操作。我們可以使用 feed_dict(傳遞字典)參數傳遞具體的值到run方法的占位符來進行多個輸入,從而來計算這個圖。= a + b # + provides a shortcut for tf.add(a, b)
print(sess.run(adder_node, {a:3, b:4.5})) print(sess.run(adder_node, {a: [1,3], b: [2,4]}))
7.5
[3. 7.]
在TensorBoard,計算圖類似於這樣:
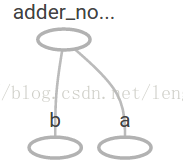 1.6我們可以增加另外的操作來讓計算圖更加復雜,比如
1.6我們可以增加另外的操作來讓計算圖更加復雜,比如
add_and_triple = adder_node *3. print(sess.run(add_and_triple, {a:3, b:4.5})) 輸出結果是: 22.5在TensorBoard,計算圖類似於這樣:
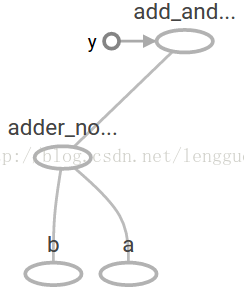 1.7 在機器學習中,我們通常想讓一個模型可以接收任意多個輸入,比如大於1個,好讓這個模型可以被訓練,在不改變輸入的情況下,
我們需要改變這個計算圖去獲得一個新的輸出。變量允許我們增加可訓練的參數到這個計算圖中,它們被構造成有一個類型和初始值:
1.7 在機器學習中,我們通常想讓一個模型可以接收任意多個輸入,比如大於1個,好讓這個模型可以被訓練,在不改變輸入的情況下,
我們需要改變這個計算圖去獲得一個新的輸出。變量允許我們增加可訓練的參數到這個計算圖中,它們被構造成有一個類型和初始值:
W = tf.Variable([.3], dtype=tf.float32) b = tf.Variable([-.3], dtype=tf.float32) x = tf.placeholder(tf.float32) linear_model = W*x + b
1.8 當你調用tf.constant時常量被初始化,它們的值是不可以改變的,而變量當你調用tf.Variable時沒有被初始化,
在TensorFlow程序中要想初始化這些變量,你必須明確調用一個特定的操作,如下:1 init = tf.global_variables_initializer() 2 sess.run(init)
1.9 要實現初始化所有全局變量的TensorFlow子圖的的處理是很重要的,直到我們調用sess.run,這些變量都是未被初始化的。
既然x是一個占位符,我們就可以同時地對多個x的值進行求值linear_model,例如:1 print(sess.run(linear_model, {x: [1,2,3,4]})) 2 求值linear_model 3 輸出為 4 [0. 0.30000001 0.60000002 0.90000004]
1.10 我們已經創建了一個模型,但是我們至今不知道它是多好,在這些訓練數據上對這個模型進行評估,我們需要一個
y占位符來提供一個期望的值,並且我們需要寫一個loss function(損失函數),一個損失函數度量當前的模型和提供 的數據有多遠,我們將會使用一個標準的損失模式來線性回歸,它的增量平方和就是當前模型與提供的數據之間的損失 ,linear_model - y創建一個向量,其中每個元素都是對應的示例錯誤增量。這個錯誤的方差我們稱為tf.square。然後 ,我們合計所有的錯誤方差用以創建一個標量,用tf.reduce_sum抽象出所有示例的錯誤。1 y = tf.placeholder(tf.float32) 2 squared_deltas = tf.square(linear_model - y) 3 loss = tf.reduce_sum(squared_deltas) 4 print(sess.run(loss, {x: [1,2,3,4], y: [0, -1, -2, -3]})) 5 輸出的結果為 6 23.66
1.11 我們分配一個值給W和b(得到一個完美的值是-1和1)來手動改進這一點,一個變量被初始化一個值會調用tf.Variable,
但是可以用tf.assign來改變這個值,例如:fixW=tf.assign(W,[1.]) fixb = tf.assign(b, [1.]) sess.run([fixW, fixb]) print(sess.run(loss, {x: [1,2,3,4], y: [0, -1, -2, -3]})) 最終打印的結果是: 0.0
1.12 tf.train APITessorFlow提供optimizers(優化器),它能慢慢改變每一個變量以最小化損失函數,最簡單的優化器是
gradient descent(梯度下降),它根據變量派生出損失的大小,來修改每個變量。通常手工計算變量符號是乏味且容易出錯的, 因此,TensorFlow使用函數tf.gradients給這個模型一個描述,從而能自動地提供衍生品,簡而言之,優化器通常會為你做這個。例如:optimizer = tf.train.GradientDescentOptimizer(0.01) train = optimizer.minimize(loss) sess.run(init)# reset values to incorrect defaults. for iin range(1000): sess.run(train, {x: [1,2,3,4], y: [0, -1, -2, -3]}) print(sess.run([W, b])) 輸出結果為 [array([-0.9999969], dtype=float32), array([ 0.99999082], dtype=float32)]
本文僅用於學習研究,非商業用途,如需參考,請註明出處,作者:木子龍。
本文參考了以下地址的講解,萬分感謝,如有侵權,請聯系我會盡快刪除,[email protected]:
https://blog.csdn.net/lengguoxing/article/details/78456279
https://www.cnblogs.com/kang06/p/9373600.html
TensorFlow 框架