
【Weka】Weka工具包
阿新 • • 發佈:2018-11-01
用久了scikitlearn,突然換回weka各種不適應
weka的tree分類器輸出的樹後面的括號的含義
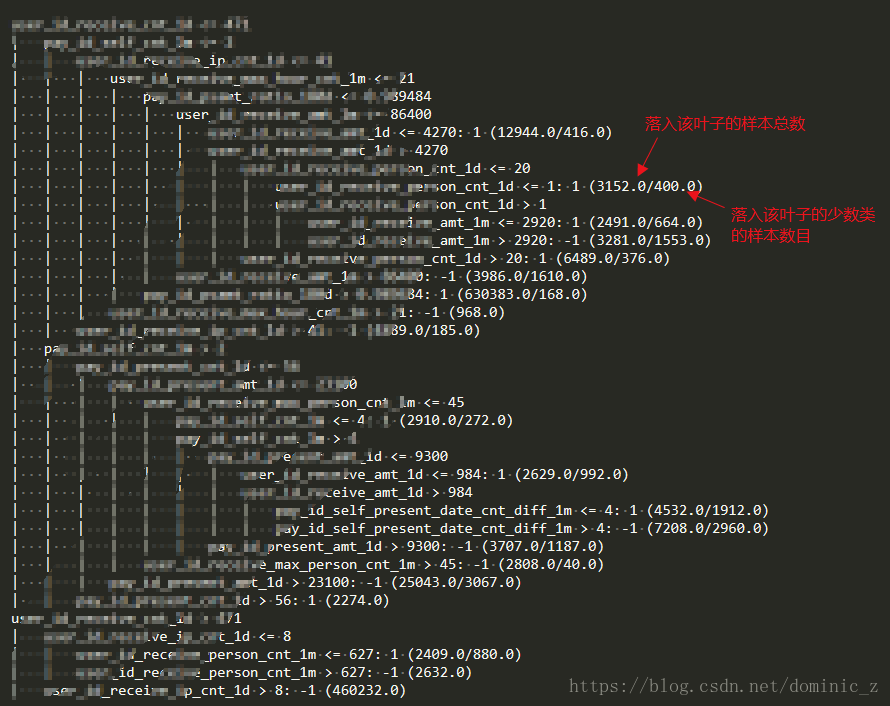
呼叫API對樣本進行分類
在分類問題中,當呼叫如下程式碼對testInstance進行分類,輸出的是一個double,預測的結果是一個index,假設預測結果為0.0
double index = classifier.classifyInstance(testInstance)
假如訓練arff檔案中的label欄位是如下
@attribute label {1,-1}
那麼index=0.0的意思就是:模型預測結果為1
又假如訓練arff檔案
@attribute label {-1,1}
那麼index=0.0的意思就是:模型預測結果為-1
distributionForInstance函式同理,輸出的double[]代表後驗概率,與訓練集中的類標籤順序是一一對應的
雖然這兩個函式的輸出不會受到測試資料集的影響,但假如你的訓練資料中的label欄位是如下
@attribute label {1,-1}
而測試資料的Instances物件的label欄位是如下
@attribute label {-1,1}
並且假如此時index=0.0,也就是說模型預測的類為1
double index = classifier.classifyInstance(testInstance)
但是下面的程式碼並不會把testInstance的類設定為1,而是會設定為-1,因為下面的程式碼會受到Instances物件的label欄位的順序影響
testInstance.setClassValue(classifier.classifyInstance(testInstance))