
xilinx 高速收發器Serdes深入研究-Comma碼(轉)
一、為什麼要用Serdes
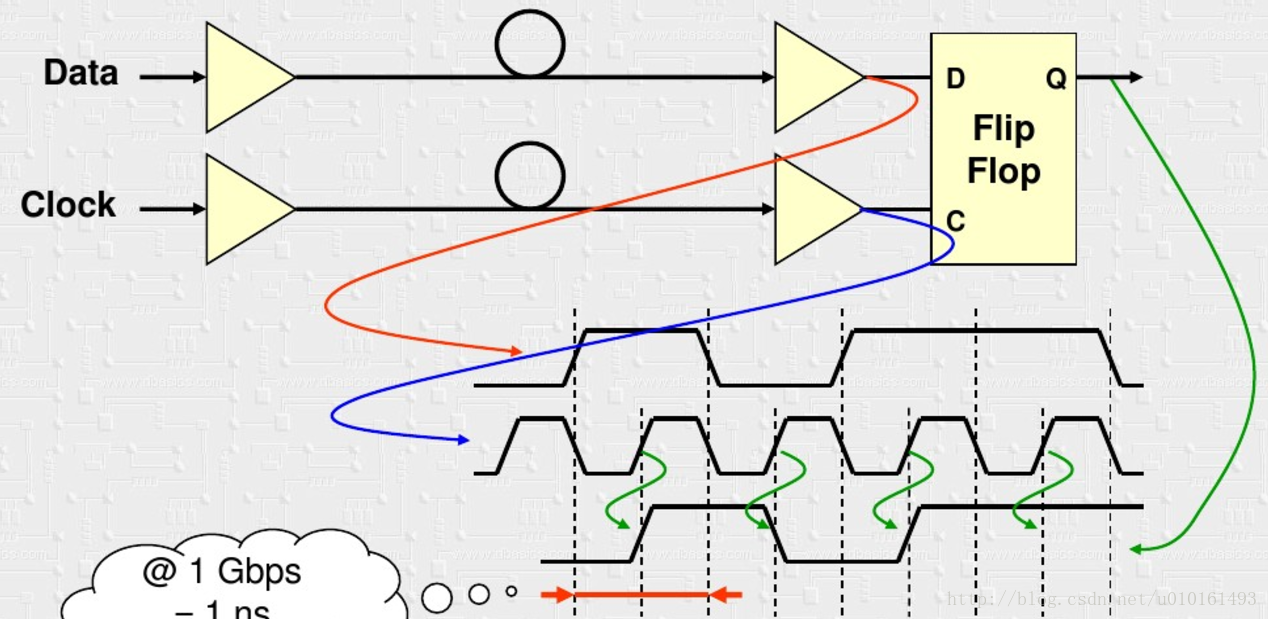
傳統的源同步傳輸,時鐘和資料分離。在速率比較低時(<1000M),沒有問題。
在速率越來越高時,這樣會有問題
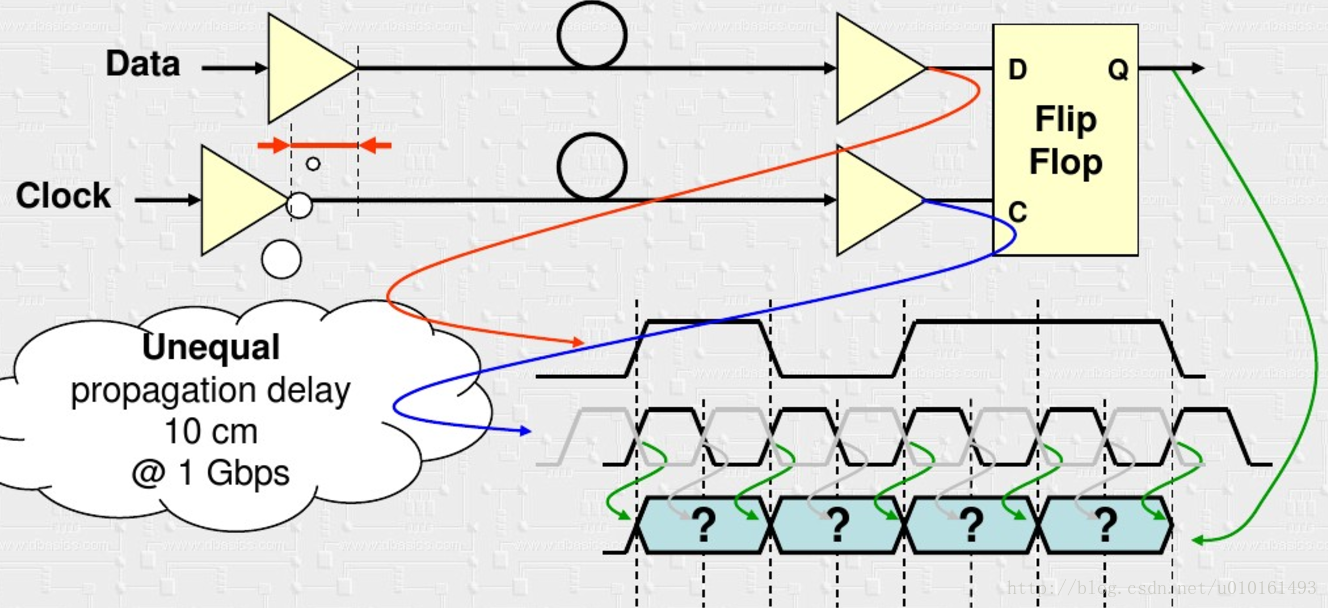
由於傳輸線的時延不一致和抖動存在,接收端不能正確的取樣資料,對不準眼圖中點。
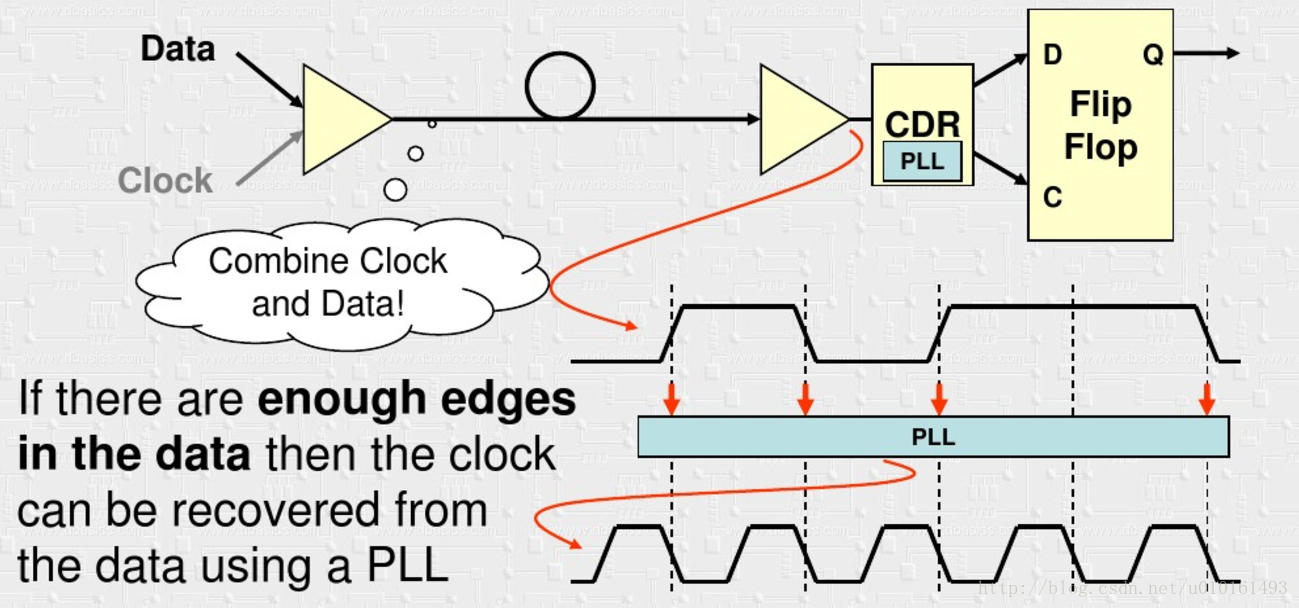
然後就想到了從資料裡面恢復出時鐘去取樣資料,即CDR
這樣就不存在延遲不一致的情況,有輕微的抖動也不會影響取樣(恢復的時鐘會隨著資料一起抖動)。
二 、為什麼要用8b10b,64b66b?
1 提供足夠的跳變來恢復時鐘
這樣還有問題,收發兩端必須共地,但往往很難實現。
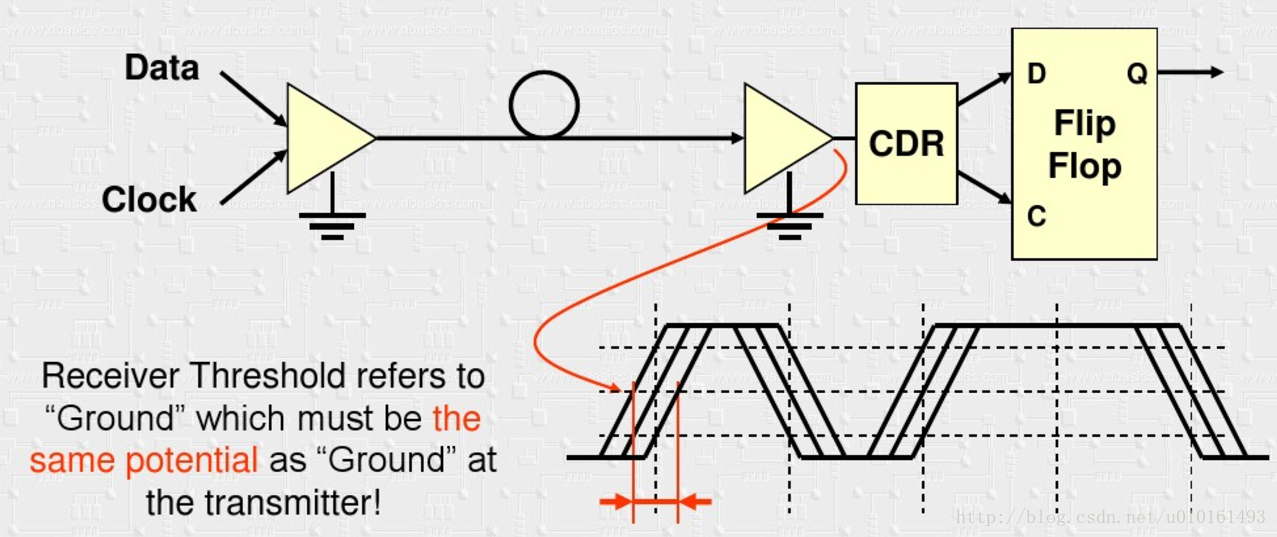
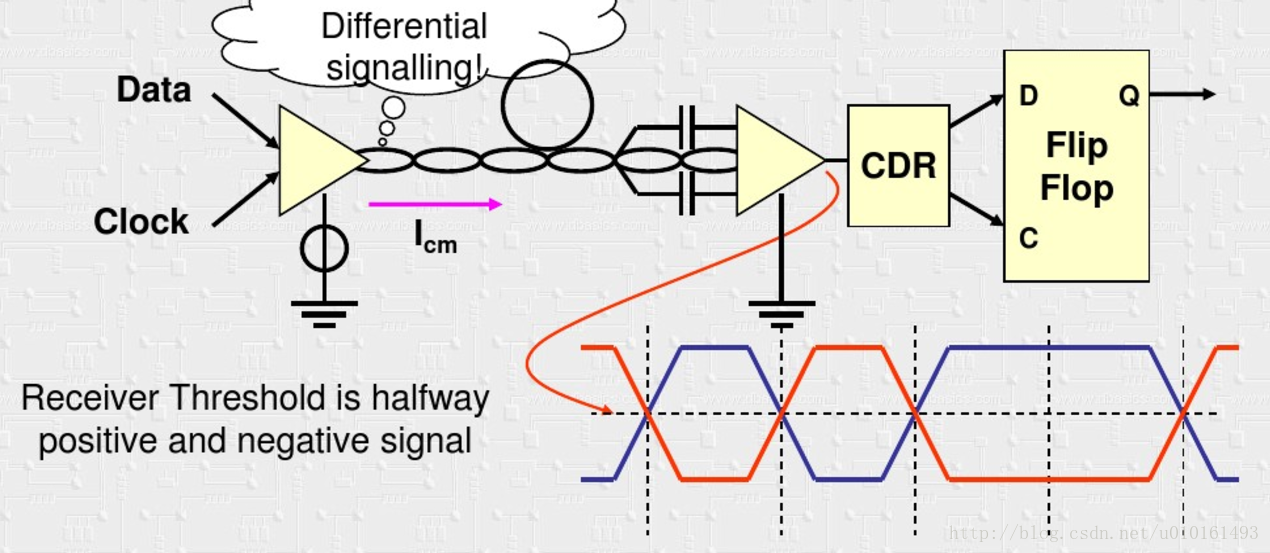
於是取樣差分訊號傳輸,為了防止共模電壓在接收端導致電流過大,使用電流驅動模式。看到接收端有電容進行交流耦合,隔直流。這樣又帶來一個問題,需要DC平衡。所以有了下面另一個原因。
2 DC平衡,即0和1的數量要相等。
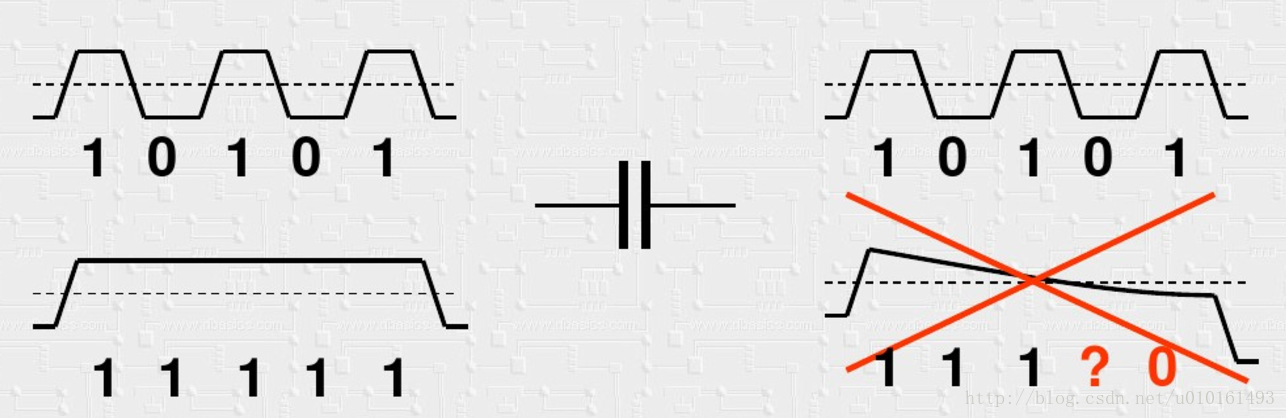
3 run length,0和1連續出現的最大長度
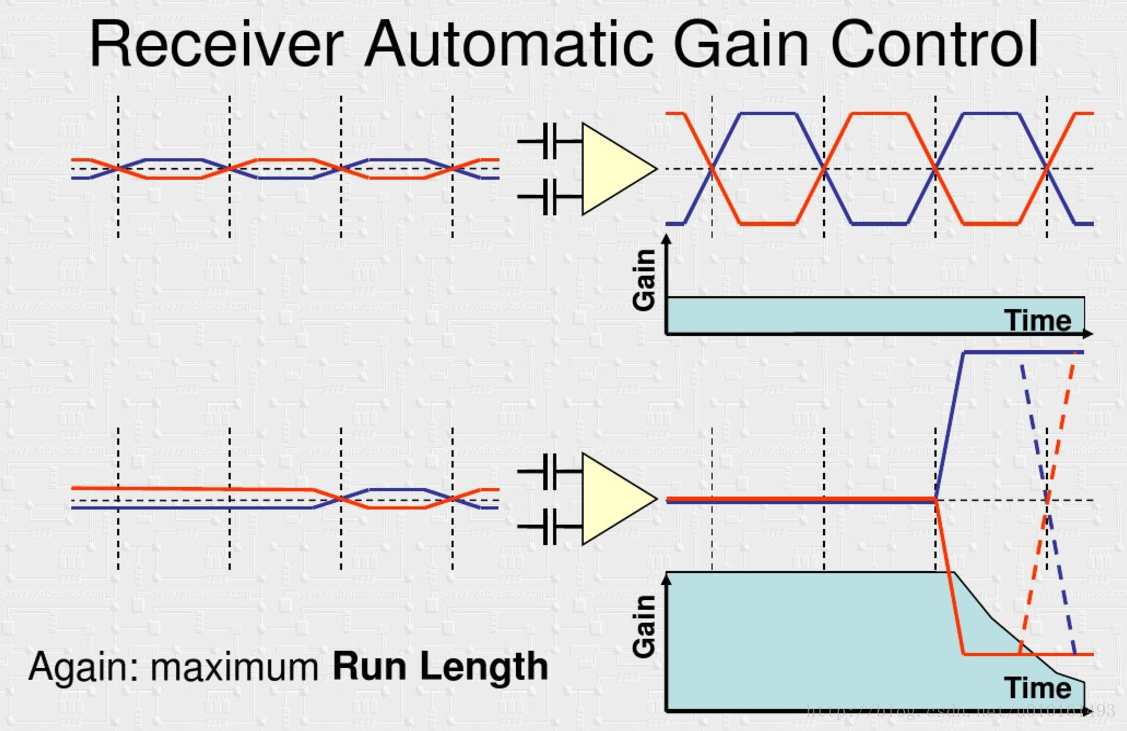
AGC自動增益控制需要交流分量才能實現放大
4 comma碼,K碼
在serdes上面的高速序列流在接收端需要重新串並轉化成多字並行,怎麼找到字的邊界進行對齊呢?
這就需要一個特殊的序列,這就是comma碼。
傳輸過程中需要的一些控制,最好不要和資料衝突了,這就是K碼。
基於以上四個原因,就有了8b10b,64b66b的出現。
三 、8b10b編碼
8b10b編碼一句話概括起來就是把8bit的資料變成10bit的資料,其中所有1或0的個數不會超過6個,並且連續的1或0的個數不會超過4個。這樣原本1024的漢明空間編碼後就大大減小了。其中有256個data碼和12K碼控制碼。這樣資料和控制碼不會重合。 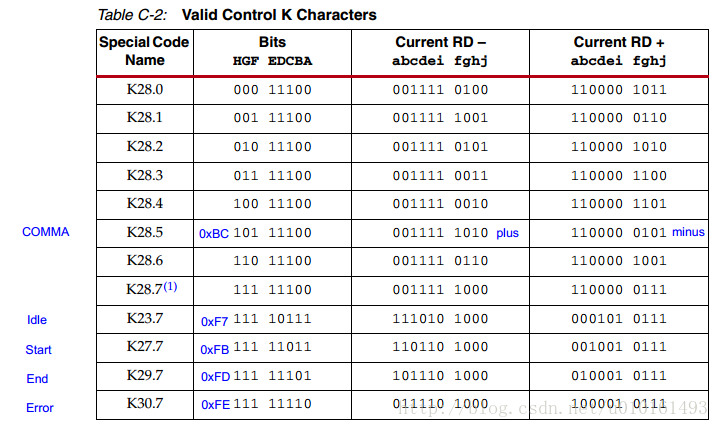
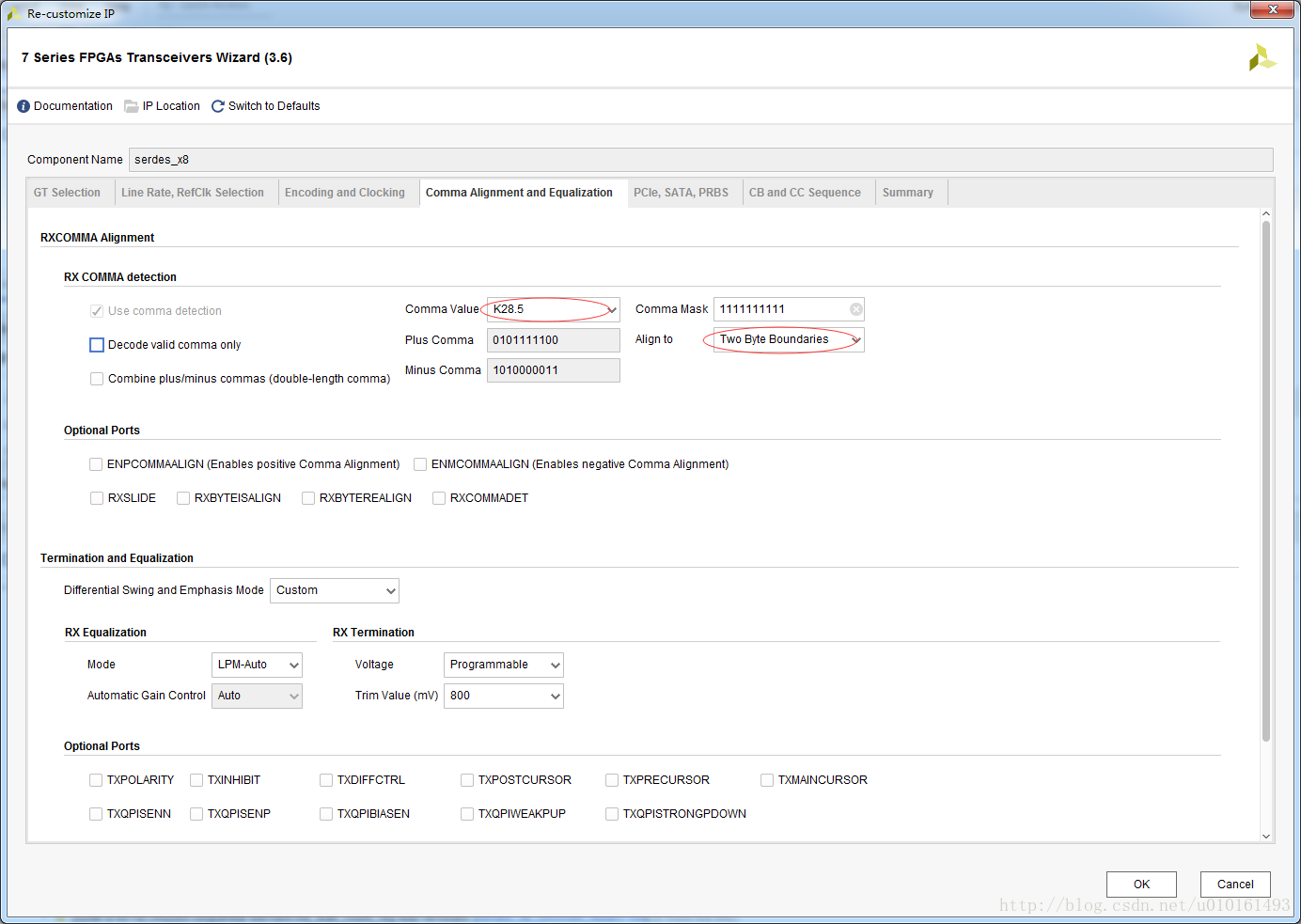
其中K28.1,K28.5,K28.7可以作為分隔碼,也叫comma碼,用於接收端在序列的資料流中找到位元組邊界。常用的K28.5即0xBC。因為正常傳輸的資料也可能有0xBC,怎麼區分呢?是有一根單獨的控制線,tx_is_K在傳輸K碼時拉高,在傳資料時拉低,去控制8b10b的編碼模組到底是編碼成資料還是控制K碼。
四、Xilinx Serdes的幾個細節
1.COMMA碼使用
K28.5,0xBC,+0101_111100,-1010_000011; 為檢測位元組分割。
使用其它K碼,作為幀開始,幀結束,時鐘修正和資料對齊。
2.多位元組處理
在資料率比較高的時候,外部位寬可能是2字(16位)或者4字(32位)。這是如果收發雙方不約定好在高低哪個字傳送comma碼,這時是可以檢測字邊界,但接收端就會出現高低位元組翻轉的情況。在任意對於單COMMA的資料對齊,選擇偶數字節對齊。傳送的時候 0x5ABC->2’b01。
也可以選擇傳送組合的comma碼,就是把NP的comma拼接起來發送,這樣接收端就檢測16bit的雙字邊界。也可以避免上面的情況出現。傳送的時候0xBCBC->2’b11
注意:decode valid comma only不要選,因為還可能傳送其他的K碼用於控制。反正8b10b是用的收發器硬核的資源,不用白不用。

3、環回設定:
1.“000”:正常模式
2.“001”:近端PCS環回
3.“010”:近端PMA環回
4.“100”:遠端PMA環回
5.“110”:遠端PCS環回
注意Xilinx例化的example的檔案中配置的環回是預留環回介面的意思,仍然需要另外手動配置。
4、fsm_down狀態機
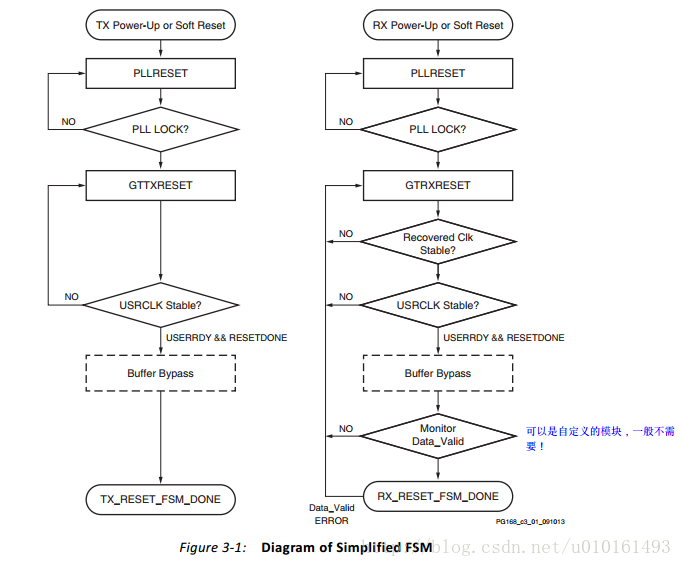
在Monitor Data_Valid模組,是用的frame_check的正確的訊號,校驗失敗會導致復位GTrxreset。可以不用這個反饋,直接置1。需要手動改一下。
5.通道繫結
限於篇幅,單獨列出
6.時鐘糾正
限於篇幅,單獨列出