
LM語言模型
1. LM定義
LM模型有:n-gram,決策樹,最大熵,HMM,條件隨機場,NN。不同點在於對條件概率 的求解。
2. LM用途
1) 用於生成文字,比如給定開頭單詞,生成一個句子(seq to seq);
2) 用於預測一句話的概率;
3. n-gram LM
2.1 假設:馬爾科夫假設,當前詞的概率僅與前n-1個詞有關,常見的有:unigram(每個單詞之間相互獨立),bigram,trigram。
2.2 公式:,一般n-gram時,需要在句首和句尾加n-1個句首標和句尾標。
2.3 引數估計:MLE詞頻估計。
2.4 資料平滑:
Add-1 smoothing (Laplace):
, 缺點:當w1出現次數很少時,本來P很大,但是由於加了一個v(字典大小),使得P變得非常小,影響了模型。
Add- smoothing:
,可以使用train-dev來優化
。缺點:比如當兩個bigram的片語均未出現時,這兩個片語對應的P是相等的。
Interpolation:
, 使用之前的小的n-gram做插值。
back-off:
, 即儘可能地使用大的n-gram,當大的未出現時,使用小的。
n-gram缺點:
1) 指數級引數增長(每個單詞對應一個條件概率,根據鏈式法則,句子概率是各個條件概率的乘積);
2) 稀疏矩陣,即可能某n-gram不存在,使得概率為0。雖然smoothing可以緩解,但是需人工計算平滑,且需考慮不同平滑方法。
4. 神經網路概率語言模型 NN LM (論文地址)
n-gram通過“詞頻+平滑”來計算條件概率, 然後通過乘積來計算整個句子S的預測概率:
在神經概率語言模型中,我們通過一個神經網路來計算上述條件概率。

結構:input(, one-hot)-> word embedding -> tanh-> softmax -> output(
損失函式(目標函式): ,
為懲罰項,可為L1,L2正則項。訓練時,最小化目標函式。
優點:
1) 由於目標函式是“求和的”,因此相比於n-gram的指數級運算,引數量大量減少;
2) 由於網路最後有一個softmax層,將輸出向量轉換為概率分佈,根據softmax的公式,可防止矩陣稀疏的現象。
缺點:
對每個條件概率,仍需要單獨訓練一個網路,引數仍然有些多。
5. RNN LM(論文地址)
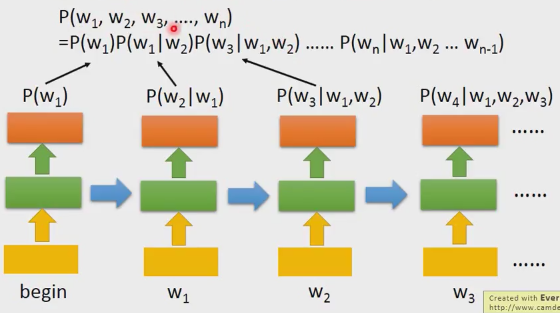
優點:
1)引數共享,大大減少了引數量;
2)NN LM 仍然以馬爾科夫假設為基礎,無法捕捉長期依賴,而RNN可以使用歷史資訊。
6. LM評價:perplexity
cross-entropy:
perplexity:
pplx表示需要多少位(即每個位置多少種類單詞)才能表示該句子,pplx越小越好。
未完待續...