
10 種機器學習演算法的要點(附 Python 和 R 程式碼)
1. 監督式學習
監督式學習演算法包括一個目標變數(因變數)和用來預測目標變數的預測變數(自變數)。通過這些變數我們可以搭建一個模型,從而對於一個已知的預測變數值,我們可以得到對應的目標變數值。重複訓練這個模型,直到它能在訓練資料集上達到預定的準確度。
屬於監督式學習的演算法有:迴歸模型,決策樹,隨機森林,K鄰近演算法,邏輯迴歸等。
2. 無監督式學習
與監督式學習不同的是,無監督學習中我們沒有需要預測或估計的目標變數。無監督式學習是用來對總體物件進行分類的。它在根據某一指標將客戶分類上有廣泛應用。
屬於無監督式學習的演算法有:關聯規則,K-means聚類演算法等。
3. 強化學習
這個演算法可以訓練程式做出某一決定。程式在某一情況下嘗試所有的可能行動,記錄不同行動的結果並試著找出最好的一次嘗試來做決定。
屬於這一類演算法的有馬爾可夫決策過程。
常見的機器學習演算法
以下是最常用的機器學習演算法,大部分資料問題都可以通過它們解決:
1.線性迴歸 (Linear Regression)
2.邏輯迴歸 (Logistic Regression)
3.決策樹 (Decision Tree)
4.支援向量機(SVM)
5.樸素貝葉斯 (Naive Bayes)
6.K鄰近演算法(KNN)
7.K-均值演算法(K-means)
8.隨機森林 (Random Forest)
9.降低維度演算法(Dimensionality Reduction Algorithms)
10.Gradient Boost和Adaboost演算法
1.線性迴歸 (Linear Regression)
線性迴歸是利用連續性變數來估計實際數值(例如房價,呼叫次數和總銷售額等)。我們通過線性迴歸演算法找出自變數和因變數間的最佳線性關係,圖形上可以確定一條最佳直線。這條最佳直線就是迴歸線。這個迴歸關係可以用Y=aX+b 表示。
我們可以假想一個場景來理解線性迴歸。比如你讓一個五年級的孩子在不問同學具體體重多少的情況下,把班上的同學按照體重從輕到重排隊。這個孩子會怎麼做呢?他有可能會通過觀察大家的身高和體格來排隊。這就是線性迴歸!這個孩子其實是認為身高和體格與人的體重有某種相關。而這個關係就像是前一段的Y和X的關係。
在Y=aX+b這個公式裡:
Y- 因變數
a- 斜率
X- 自變數
b- 截距
a和b可以通過最小化因變數誤差的平方和得到(最小二乘法)。
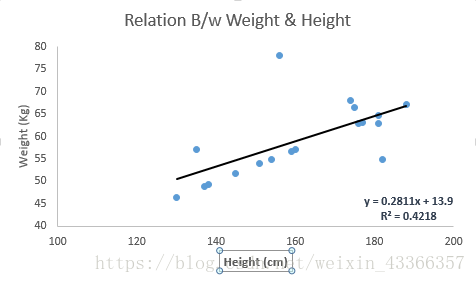
下圖中我們得到的線性迴歸方程是 y=0.2811X+13.9。通過這個方程,我們可以根據一個人的身高得到他的體重資訊。
Python 程式碼
#Import Library
#Import other necessary libraries like pandas, numpy…
fromsklearn importlinear_model
#Load Train and Test datasets
#Identify feature and response variable(s) and values must be numeric and numpy arrays
x_train=input_variables_values_training_datasets
y_train=target_variables_values_training_datasets
x_test=input_variables_values_test_datasets
# Create linear regression object
linear =linear_model.LinearRegression()
# Train the model using the training sets and check score
linear.fit(x_train,y_train)
linear.score(x_train,y_train)
#Equation coefficient and Intercept
print(‘Coefficient: \n’,linear.coef_)
print(‘Intercept: \n’,linear.intercept_)
#Predict Output
predicted=linear.predict(x_test)
R 程式碼
#Load Train and Test datasets
#Identify feature and response variable(s) and values must be numeric and numpy arrays
x_train <-input_variables_values_training_datasets
y_train <-target_variables_values_training_datasets
x_test <-input_variables_values_test_datasets
x <-cbind(x_train,y_train)
# Train the model using the training sets and check score
linear <-lm(y_train ~.,data =x)
summary(linear)
#Predict Output
predicted=predict(linear,x_test)
2.邏輯迴歸
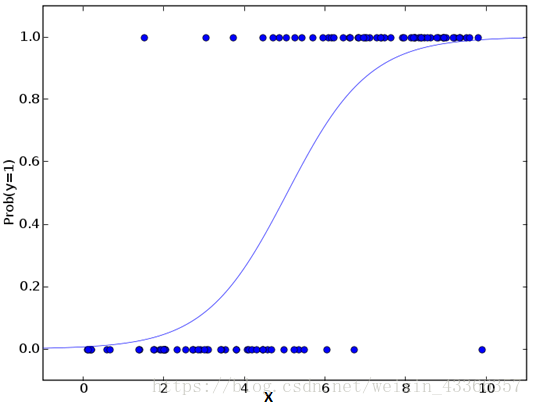
別被它的名字迷惑了,邏輯迴歸其實是一個分類演算法而不是迴歸演算法。通常是利用已知的自變數來預測一個離散型因變數的值(像二進位制值0/1,是/否,真/假)。簡單來說,它就是通過擬合一個邏輯函式(logit fuction)來預測一個事件發生的概率。所以它預測的是一個概率值,自然,它的輸出值應該在0到1之間。
同樣,我們可以用一個例子來理解這個演算法。
假設你的一個朋友讓你回答一道題。可能的結果只有兩種:你答對了或沒有答對。為了研究你最擅長的題目領域,你做了各種領域的題目。那麼這個研究的結果可能是這樣的:如果是一道十年級的三角函式題,你有70%的可能效能解出它。但如果是一道五年級的歷史題,你會的概率可能只有30%。邏輯迴歸就是給你這樣的概率結果。
回到數學上,事件結果的勝算對數(log odds)可以用預測變數的線性組合來描述:
odds= p/ (1-p) = probability of event occurrence / probability of not event occurrence
ln(odds) = ln(p/(1-p))
logit§ = ln(p/(1-p)) = b0+b1X1+b2X2+b3X3…+bkXk
在這裡,p 是我們感興趣的事件出現的概率。它通過篩選出特定引數值使得觀察到的樣本值出現的概率最大化,來估計引數,而不是像普通迴歸那樣最小化誤差的平方和。
你可能會問為什麼需要做對數呢?簡單來說這是重複階梯函式的最佳方法。因本篇文章旨不在此,這方面就不做詳細介紹了。
#Import Library
fromsklearn.linear_model importLogisticRegression
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create logistic regression object
model =LogisticRegression()
# Train the model using the training sets and check score
model.fit(X,y)
model.score(X,y)
#Equation coefficient and Intercept
print(‘Coefficient: \n’,model.coef_)
print(‘Intercept: \n’,model.intercept_)
#Predict Output
predicted=model.predict(x_test)
R 程式碼
x <-cbind(x_train,y_train)
# Train the model using the training sets and check score
logistic <-glm(y_train ~.,data =x,family=‘binomial’)
summary(logistic)
#Predict Output
predicted=predict(logistic,x_test)
延伸:
以下是一些可以嘗試的優化模型的方法:
加入互動項(interaction)
減少特徵變數
正則化(regularization)
使用非線性模型
3.決策樹
這是我最喜歡也是能經常使用到的演算法。它屬於監督式學習,常用來解決分類問題。令人驚訝的是,它既可以運用於類別變數(categorical variables)也可以作用於連續變數。這個演算法可以讓我們把一個總體分為兩個或多個群組。分組根據能夠區分總體的最重要的特徵變數/自變數進行。更詳細的內容可以閱讀這篇文章Decision Tree Simplified。
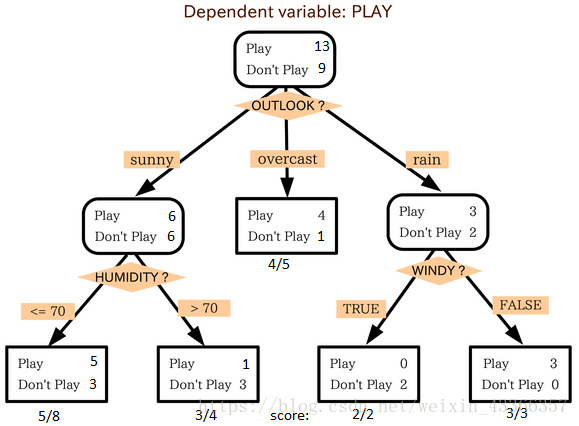
從上圖中我們可以看出,總體人群最終在玩與否的事件上被分成了四個群組。而分組是依據一些特徵變數實現的。用來分組的具體指標有很多,比如Gini,information Gain, Chi-square,entropy。
理解決策樹原理的最好的辦法就是玩Jezzball遊戲。這是微軟的一款經典遊戲(見下圖)。這個遊戲的最終任務是在一個有移動牆壁的房間裡,通過建造牆壁來儘可能地將房間分成儘量大的,沒有小球的空間。

每一次你用建牆來分割房間,其實就是在將一個總體分成兩部分。決策樹也是用類似方法將總體分成儘量多的不同組別。
延伸閱讀: Simplified Version of Decision Tree Algorithms
Python 程式碼
#Import Library
#Import other necessary libraries like pandas, numpy…
fromsklearn importtree
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create tree object
model =tree.DecisionTreeClassifier(criterion=‘gini’)# for classification, here you can change the algorithm as gini or entropy (information gain) by default it is gini
# model = tree.DecisionTreeRegressor() for regression
# Train the model using the training sets and check score
model.fit(X,y)
model.score(X,y)
#Predict Output
predicted=model.predict(x_test)
R 程式碼
library(rpart)
x <-cbind(x_train,y_train)
# grow tree
fit <-rpart(y_train ~.,data =x,method=“class”)
summary(fit)
#Predict Output
predicted=predict(fit,x_test)
4. 支援向量機(SVM)
這是一個分類演算法。在這個演算法中我們將每一個數據作為一個點在一個n維空間上作圖(n是特徵數),每一個特徵值就代表對應座標值的大小。比如說我們有兩個特徵:一個人的身高和髮長。我們可以將這兩個變數在一個二維空間上作圖,圖上的每個點都有兩個座標值(這些座標軸也叫做支援向量)。
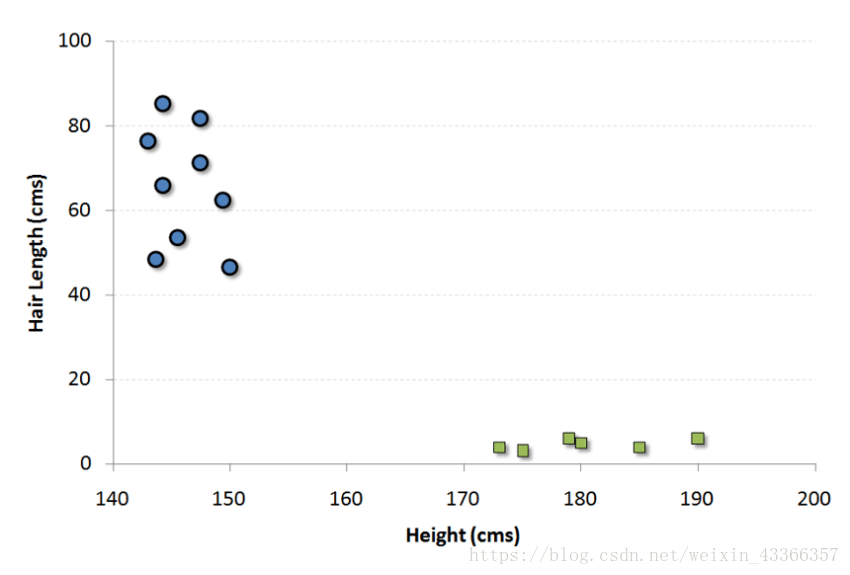
現在我們要在圖中找到一條直線能最大程度將不同組的點分開。兩組資料中距離這條線最近的點到這條線的距離都應該是最遠的。
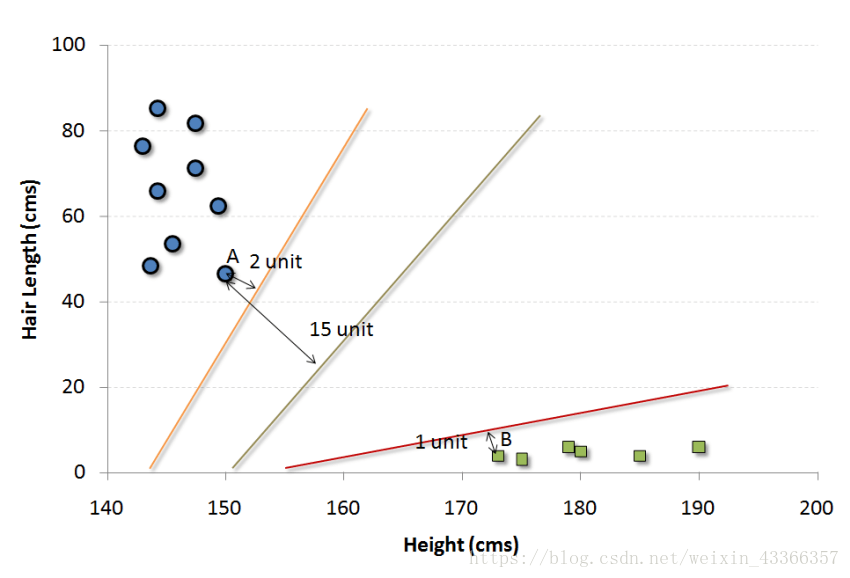
在上圖中,黑色的線就是最佳分割線。因為這條線到兩組中距它最近的點,點A和B的距離都是最遠的。任何其他線必然會使得到其中一個點的距離比這個距離近。這樣根據資料點分佈在這條線的哪一邊,我們就可以將資料歸類。
更多閱讀: Simplified Version of Support Vector Machine
我們可以把這個演算法想成n維空間裡的JezzBall遊戲,不過有一些變動:
你可以以任何角度畫分割線/分割面(經典遊戲中只有垂直和水平方向)。
現在這個遊戲的目的是把不同顏色的小球分到不同空間裡。
小球是不動的。
Python 程式碼
#Import Library
fromsklearn importsvm
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create SVM classification object
model =svm.svc()# there is various option associated with it, this is simple for classification. You can refer link, for mo# re detail.
# Train the model using the training sets and check score
model.fit(X,y)
model.score(X,y)
#Predict Output
predicted=model.predict(x_test)
R 程式碼
library(e1071)
x <-cbind(x_train,y_train)
# Fitting model
fit <-svm(y_train ~.,data =x)
summary(fit)
#Predict Output
predicted=predict(fit,x_test)
5. 樸素貝葉斯
這個演算法是建立在貝葉斯理論上的分類方法。它的假設條件是自變數之間相互獨立。簡言之,樸素貝葉斯假定某一特徵的出現與其它特徵無關。比如說,如果一個水果它是紅色的,圓狀的,直徑大概7cm左右,我們可能猜測它為蘋果。即使這些特徵之間存在一定關係,在樸素貝葉斯演算法中我們都認為紅色,圓狀和直徑在判斷一個水果是蘋果的可能性上是相互獨立的。
樸素貝葉斯的模型易於建造,並且在分析大量資料問題時效率很高。雖然模型簡單,但很多情況下工作得比非常複雜的分類方法還要好。
貝葉斯理論告訴我們如何從先驗概率P©,P(x)和條件概率P(x|c)中計算後驗概率P(c|x)。演算法如下:

P(c|x)是已知特徵x而分類為c的後驗概率。
P©是種類c的先驗概率。
P(x|c)是種類c具有特徵x的可能性。
P(x)是特徵x的先驗概率。
例子: 以下這組訓練集包括了天氣變數和目標變數“是否出去玩”。我們現在需要根據天氣情況將人們分為兩組:玩或不玩。整個過程按照如下步驟進行:
步驟1:根據已知資料做頻率表
步驟2:計算各個情況的概率製作概率表。比如陰天(Overcast)的概率為0.29,此時玩的概率為0.64.
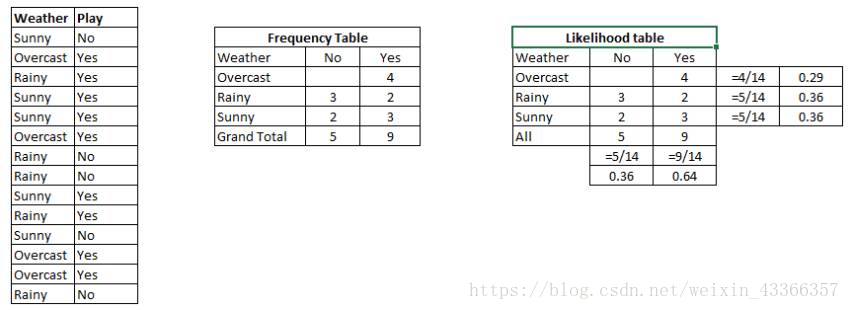
步驟3:用樸素貝葉斯計算每種天氣情況下玩和不玩的後驗概率。概率大的結果為預測值。
提問: 天氣晴朗的情況下(sunny),人們會玩。這句陳述是否正確?
我們可以用上述方法回答這個問題。P(Yes | Sunny)=P(Sunny | Yes) * P(Yes) / P(Sunny)。
這裡,P(Sunny |Yes) = 3/9 = 0.33, P(Sunny) = 5/14 = 0.36, P(Yes)= 9/14 = 0.64。
那麼,P (Yes | Sunny) = 0.33 * 0.64 / 0.36 = 0.60>0.5,說明這個概率值更大。
當有多種類別和多種特徵時,預測的方法相似。樸素貝葉斯通常用於文字分類和多類別分類問題。
Python 程式碼
#Import Library
fromsklearn.naive_bayes importGaussianNB
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create SVM classification object model = GaussianNB() # there is other distribution for multinomial classes like Bernoulli Naive Bayes, Refer link
# Train the model using the training sets and check score
model.fit(X,y)
#Predict Output
predicted=model.predict(x_test)
R 程式碼
library(e1071)
x <-cbind(x_train,y_train)
# Fitting model
fit <-naiveBayes(y_train ~.,data =x)
summary(fit)
#Predict Output
predicted=predict(fit,x_test)
6.KNN(K-鄰近演算法)
這個演算法既可以解決分類問題,也可以用於迴歸問題,但工業上用於分類的情況更多。 KNN先記錄所有已知資料,再利用一個距離函式,找出已知資料中距離未知事件最近的K組資料,最後按照這K組資料裡最常見的類別預測該事件。
距離函式可以是歐式距離,曼哈頓距離,閔氏距離 (Minkowski Distance), 和漢明距離(Hamming Distance)。前三種用於連續變數,漢明距離用於分類變數。如果K=1,那問題就簡化為根據最近的資料分類。K值的選取時常是KNN建模裡的關鍵。
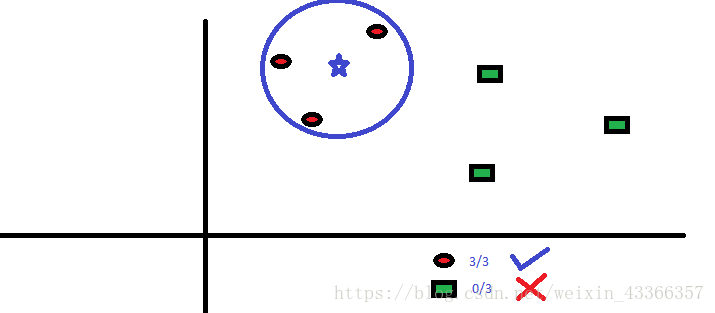
KNN在生活中的運用很多。比如,如果你想了解一個不認識的人,你可能就會從這個人的好朋友和圈子中瞭解他的資訊。
在用KNN前你需要考慮到:
KNN的計算成本很高
所有特徵應該標準化數量級,否則數量級大的特徵在計算距離上會有偏移。
在進行KNN前預處理資料,例如去除異常值,噪音等。
Python 程式碼
#Import Library
fromsklearn.neighbors importKNeighborsClassifier
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create KNeighbors classifier object model
KNeighborsClassifier(n_neighbors=6)# default value for n_neighbors is 5
# Train the model using the training sets and check score
model.fit(X,y)
#Predict Output
predicted=model.predict(x_test)
R 程式碼
library(knn)
x <-cbind(x_train,y_train)
# Fitting model
fit <-knn(y_train ~.,data =x,k=5)
summary(fit)
#Predict Output
predicted=predict(fit,x_test)
7. K均值演算法(K-Means)
這是一種解決聚類問題的非監督式學習演算法。這個方法簡單地利用了一定數量的叢集(假設K個叢集)對給定資料進行分類。同一叢集內的資料點是同類的,不同叢集的資料點不同類。
還記得你是怎樣從墨水漬中辨認形狀的麼?K均值演算法的過程類似,你也要通過觀察叢集形狀和分佈來判斷叢集數量!

K均值演算法如何劃分叢集:
從每個叢集中選取K個數據點作為質心(centroids)。
將每一個數據點與距離自己最近的質心劃分在同一叢集,即生成K個新叢集。
找出新叢集的質心,這樣就有了新的質心。
重複2和3,直到結果收斂,即不再有新的質心出現。
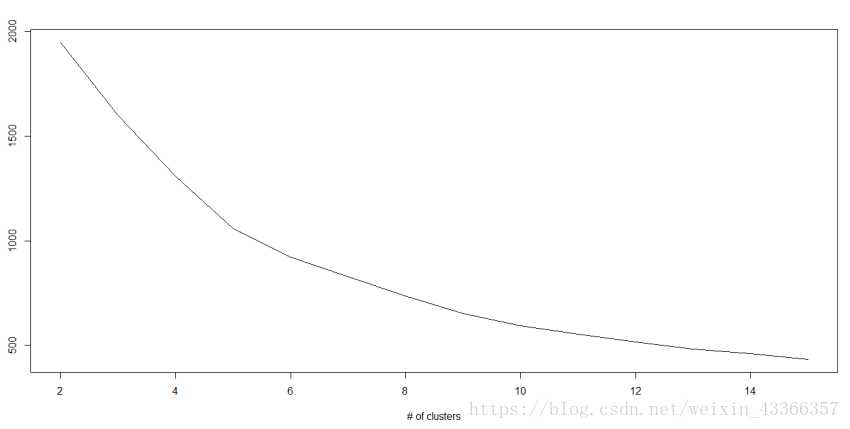
怎樣確定K的值:
如果我們在每個叢集中計算叢集中所有點到質心的距離平方和,再將不同叢集的距離平方和相加,我們就得到了這個叢集方案的總平方和。
我們知道,隨著叢集數量的增加,總平方和會減少。但是如果用總平方和對K作圖,你會發現在某個K值之前總平方和急速減少,但在這個K值之後減少的幅度大大降低,這個值就是最佳的叢集數。
#Import Library
fromsklearn.cluster importKMeans
#Assumed you have, X (attributes) for training data set and x_test(attributes) of test_dataset
# Create KNeighbors classifier object model
k_means =KMeans(n_clusters=3,random_state=0)
# Train the model using the training sets and check score
model.fit(X)
#Predict Output
predicted=model.predict(x_test)
R 程式碼
library(cluster)
fit <-kmeans(X,3)# 5 cluster solution
8.隨機森林
隨機森林是對決策樹集合的特有名稱。隨機森林裡我們有多個決策樹(所以叫“森林”)。為了給一個新的觀察值分類,根據它的特徵,每一個決策樹都會給出一個分類。隨機森林演算法選出投票最多的分類作為分類結果。
怎樣生成決策樹:
如果訓練集中有N種類別,則有重複地隨機選取N個樣本。這些樣本將組成培養決策樹的訓練集。
如果有M個特徵變數,那麼選取數m <<M,從而在每個節點上隨機選取m個特徵變數來分割該節點。m在整個森林養成中保持不變。
每個決策樹都最大程度上進行分割,沒有剪枝。
比較決策樹和調節模型引數可以獲取更多該演算法細節。我建議讀者閱讀這些文章:
Introduction to Random forest – Simplified
Comparing a CART model to Random Forest (Part 1)
Comparing a Random Forest to a CART model (Part 2)
Tuning the parameters of your Random Forest model
Python 程式碼
#Import Library
fromsklearn.ensemble importRandomForestClassifier
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create Random Forest object
model=RandomForestClassifier()
# Train the model using the training sets and check score
model.fit(X,y)
#Predict Output
predicted=model.predict(x_test)
R 程式碼
library(randomForest)
x <-cbind(x_train,y_train)
# Fitting model
fit <-randomForest(Species~.,x,ntree=500)
summary(fit)
#Predict Output
predicted=predict(fit,x_test)
9.降維演算法(Dimensionality Reduction Algorithms)
在過去的4-5年裡,可獲取的資料幾乎以指數形式增長。公司/政府機構/研究組織不僅有了更多的資料來源,也獲得了更多維度的資料資訊。
例如:電子商務公司有了顧客更多的細節資訊,像個人資訊,網路瀏覽歷史,個人喜惡,購買記錄,反饋資訊等,他們關注你的私人特徵,比你天天去的超市裡的店員更瞭解你。
作為一名資料科學家,我們手上的資料有非常多的特徵。雖然這聽起來有利於建立更強大精準的模型,但它們有時候反倒也是建模中的一大難題。怎樣才能從1000或2000個變數裡找到最重要的變數呢?這種情況下降維演算法及其他演算法,如決策樹,隨機森林,PCA,因子分析,相關矩陣,和預設值比例等,就能幫我們解決難題。
進一步的瞭解可以閱讀Beginners Guide To Learn Dimension Reduction Techniques。
Python 程式碼
更多資訊在這裡
#Import Library
fromsklearn importdecomposition
#Assumed you have training and test data set as train and test
# Create PCA obeject pca= decomposition.PCA(n_components=k) #default value of k =min(n_sample, n_features)
# For Factor analysis
#fa= decomposition.FactorAnalysis()
# Reduced the dimension of training dataset using PCA
train_reduced =pca.fit_transform(train)
#Reduced the dimension of test dataset
test_reduced =pca.transform(test)
R 程式碼
library(stats)
pca <-princomp(train,cor =TRUE)
train_reduced <-predict(pca,train)
test_reduced <-predict(pca,test)
10.Gradient Boosing 和 AdaBoost
GBM和AdaBoost都是在有大量資料時提高預測準確度的boosting演算法。Boosting是一種整合學習方法。它通過有序結合多個較弱的分類器/估測器的估計結果來提高預測準確度。這些boosting演算法在Kaggle,AV Hackthon, CrowdAnalytix等資料科學競賽中有出色發揮。
更多閱讀: Know about Gradient and AdaBoost in detail
Python 程式碼
#Import Library
fromsklearn.ensemble importGradientBoostingClassifier
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create Gradient Boosting Classifier object
model=GradientBoostingClassifier(n_estimators=100,learning_rate=1.0,max_depth=1,random_state=0)
# Train the model using the training sets and check score
model.fit(X,y)
#Predict Output
predicted=model.predict(x_test)
R 程式碼
library(caret)
x <-cbind(x_train,y_train)
# Fitting model
fitControl <-trainControl(method =“repeatedcv”,number =4,repeats =4)
fit <-train(y ~.,data =x,method =“gbm”,trControl =fitControl,verbose =FALSE)
predicted=predict(fit,x_test,type=“prob”)[,2]
GradientBoostingClassifier 和隨機森林是兩種不同的boosting分類樹。人們經常提問這兩個演算法有什麼不同。