離散單輸出感知器訓練演算法
阿新 • • 發佈:2018-11-05
- 二值網路:自變數及其函式的值、向量分量的值只取0和1函式、向量。
- 權向量:W=(w1,w2,…,wn)
- 輸入向量:X=(x1,x2,…,xn)
- 訓練樣本集:{(X,Y)|Y為輸入向量X對應的輸出}
- 初始化權向量W;
- 重複下列過程,直到訓練完成:
2.1 對每個樣本(X,Y),重複如下過程:
2.1.1 輸入X;
2.1.2 計算o=F(XW);
2.1.3 如果輸出不正確,則
當o=0時,取 W=W+X,
當o=1時,取 W=W-X
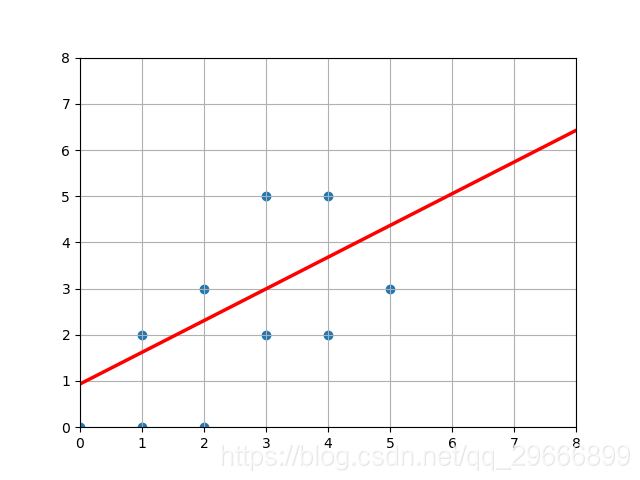
import random import numpy as np import math import matplotlib.pyplot as plt def func(x): """ 函式說明:x中對應位置元素大於0記為1,否則記為0 x:列表 返回值:o,0,1列表 """ o = [] for i in x: if i > 0: o.append(1) else: o.append(0) return o def main(): # 權值w W = np.random.normal(0, 1, (2, 1)) # 偏執值 b = np.random.uniform(0, 1) # 學習率 learn_rete = 0.2 # 輸入 X = np.array([[1, 0], [1, 2], [2, 0], [2, 3], [3, 2], [4, 2], [4, 5], [5, 3], [0, 0], [3, 5]]) # 理想輸出 Y = np.array([1, 0, 1, 0, 1, 1, 0, 1, 1, 0]) while True: # 記錄錯誤個數,當全部分類正確時,退出迴圈 count = 0 # 計算實際輸出 o = func(np.dot(X, W) + b) for i in range(10): if Y[i] - o[i] > 0: W += learn_rete * X[i].reshape(2, 1) b += learn_rete * Y[i] count += 1 elif Y[i] - o[i] < 0: W -= learn_rete * X[i].reshape(2, 1) b -= learn_rete * Y[i] count += 1 else: pass if count == 0: break plt.figure() # 畫出所有點 x_sca = X[:, 0] y_sca = X[:, 1] plt.scatter(x_sca, y_sca) # 斜率 r = -W[0][0] / W[1][0] # 偏執值 bias = -b / W[1][0] # 畫直線 x = np.linspace(0, 8, 24) y = r * x + bias plt.plot(x, y, 'r', linewidth=2.5, linestyle="-") # 座標值 plt.xlim(0, 8) plt.ylim(0, 8) # 顯示網格 plt.grid() plt.show() if __name__ == '__main__': main()