
《演算法筆記》總結一
目錄
1. 定義變數時儘可能賦初值,避免在程式時出現未知訪問錯誤!!!(不能想當然的賴編譯器的預設初始化)
3.2 getchar( )/getc(stdin)、putchar( )/putc(ch,stdout)
3.3 gets、gets_s、puts、fgets
####進位制轉換方法對於一個P進位制的數,如果要轉換為Q進位制,需要分為兩步:
第二章
1. 定義變數時儘可能賦初值,避免在程式時出現未知訪問錯誤!!!(不能想當然的賴編譯器的預設初始化)
擴充套件知識點 記憶體管理 地址對映~(早期看《c程式設計語言》也講到相關知識點,但是編寫時沒注意到痛點,謹記今後不再犯)
定義變數時,C和C++有著顯著的區別。這兩種語言都要求變數使用前必須定義,但是C(和很多其他的傳統過程語言)強制在作用域的開始處就定義所有的變數(c99之前),以便在編譯器建立一個塊時,能給所有這些變數分配空間。
下圖是C語言的記憶體佈局結構,Memory layout of c program中有著詳細的介紹。(https://www.geeksforgeeks.org/memory-layout-of-c-program/
1.1C程式的記憶體佈局。
1.文字段 (Text segment)
2.初始化資料段(Initialized data segment)
3.未初始化資料段( Uninitialized data segment)
4.堆疊( Stack)
5.堆(Heap)
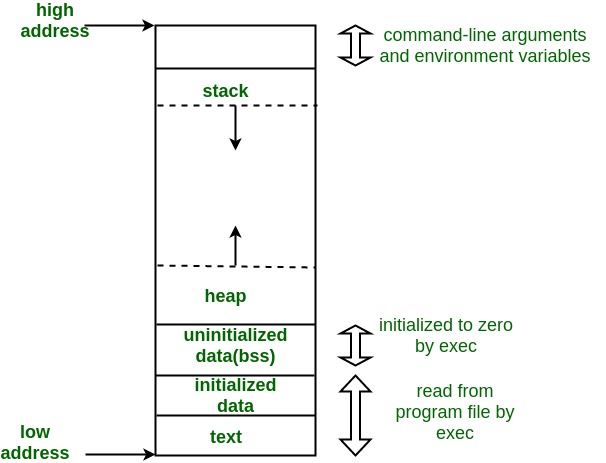
1.文字段:
文字段,也稱為程式碼段或簡稱為文字段,是目標檔案或記憶體中包含可執行指令的程式的一部分。作為儲存區域,文字段可以放置在堆或堆疊下方,以防止堆和堆疊溢位覆蓋它。通常,文字段是可共享的,因此對於頻繁執行的程式(例如文字編輯器,C編譯器,shell等),只需要一個副本就可以儲存在記憶體中。此外,文字段通常是隻讀的,以防止程式意外修改其指令。假如同時有多個編譯任務在執行,這些編譯任務會共享編譯器的程式碼區,但同時各個編譯任務又有自己獨立的區域。
2.初始化資料段:
初始化資料段,通常簡稱為資料段。資料段是程式的虛擬地址空間的一部分,其包含由程式設計師初始化的全域性變數和靜態變數。
請注意,資料段不是隻讀的,因為變數的值可以在執行時更改。
該段可以進一步分為初始化只讀區域和初始化讀寫區域。
例如,在C中由char s [] =“hello world”定義的全域性字串和在main(即全域性)之外的int debug = 1之類的C語句將儲存在初始化的讀寫區域中。並且像const char * string =“hello world”這樣的全域性C語句使得字串文字“hello world”儲存在初始化的只讀區域中,字元指標變數字串儲存在初始化的讀寫區域中。
例如:static int i = 10將儲存在資料段中,global int i = 10也將儲存在資料段中
3.未初始化的資料段:
未初始化的資料段,通常稱為“bss”段,以一個代表“由符號開始的塊”的古代彙編運算子命名。該段中的資料在程式啟動之前由核心初始化為算術0執行
未初始化的資料從資料段的末尾開始,包含初始化為零或在原始碼中沒有顯式初始化的所有全域性變數和靜態變數。
例如,變數宣告為static int i; 將包含在BSS部分中。
例如,一個宣告為int j的全域性變數; 將包含在BSS部分中。
4.堆疊:
堆疊區域傳統上與堆區域相鄰並向相反方向增長; 當堆疊指標遇到堆指標時,空閒記憶體耗盡。(使用現代大地址空間和虛擬記憶體技術,它們幾乎可以放置在任何地方,但它們通常仍會朝著相反的方向發展。)
堆疊區域包含程式堆疊,LIFO結構,通常位於儲存器的較高部分。在標準的PC x86計算機體系結構上,它向零地址發展; 在其他一些架構上,它朝著相反的方向發展。“堆疊指標”暫存器跟蹤堆疊的頂部; 每次將值“推”到堆疊上時都會調整它。為一個函式呼叫推送的值集稱為“堆疊幀”; 堆疊幀至少包含返回地址。
儲存自動變數的堆疊,以及每次呼叫函式時儲存的資訊。每次呼叫函式時,返回的地址和有關呼叫者環境的某些資訊(例如某些機器暫存器)都會儲存在堆疊中。然後,新呼叫的函式在堆疊上為其自動和臨時變數分配空間。這就是C中遞迴函式的工作方式。每次遞迴函式呼叫自身時,都會使用新的堆疊幀,因此一組變數不會干擾來自該函式的另一個例項的變數。
堆區域由malloc,calloc,realloc和free管理,它們可以使用brk和sbrk系統呼叫來調整其大小(請注意,不需要使用brk / sbrk和單個“堆區域”來實現malloc / calloc / realloc / free的契約;它們也可以使用mmap / munmap來實現,以保留/ 取消將虛擬記憶體的潛在非連續區域保留到程序的“ 虛擬地址空間”中。堆區域由程序中的所有執行緒,共享庫和動態載入的模組共享。(https://en.wikipedia.org/wiki/Data_segment)
5.堆:
堆是通常發生動態記憶體分配的段。
堆區域從BSS段的末尾開始,並從那裡增長到更大的地址。堆區域由malloc,realloc和free管理,可以使用brk和sbrk系統呼叫來調整其大小(注意使用brk / sbrk和單個“堆區域”不需要履行malloc / realloc / free的合同;它們也可以使用mmap實現,以將可能不連續的虛擬記憶體區域保留到程序的“虛擬地址空間”中。堆區域由程序中的所有共享庫和動態載入的模組共享。
1.2記憶體管理的目的及建議
(https://www.cnblogs.com/yif1991/p/5049638.html)
學習記憶體管理就是為了知道日後怎麼樣在合適的時候管理我們的記憶體。那麼問題來了?什麼時候用堆什麼時候用棧呢?一般遵循以下三個原則:
- 如果明確知道資料佔用多少記憶體,那麼資料量較小時用棧,較大時用堆;
- 如果不知道資料量大小(可能需要佔用較大記憶體),最好用堆(因為這樣保險些);
- 如果需要動態建立陣列,則用堆。
擴充套件
作業系統在管理記憶體時,最小單位不是位元組,而是記憶體頁(32位作業系統的記憶體頁一般是4K)。比如,初次申請1K記憶體,作業系統會分配1個記憶體頁,也就是4K記憶體。4K是一個折中的選擇,因為:記憶體頁越大,記憶體浪費越多,但作業系統記憶體排程效率高,不用頻繁分配和釋放記憶體;記憶體頁越小,記憶體浪費越少,但作業系統記憶體排程效率低,需要頻繁分配和釋放記憶體。嵌入式系統的記憶體記憶體資源很稀缺,其記憶體頁會更小,因此在嵌入式開發當中需要特別注意。
C語言 記憶體管理詳解(http://club.topsage.com/thread-443540-1-1.html)
1.3 note that
https://bbs.csdn.net/topics/392175315
其實電腦開機後實體記憶體的每個位元組中都有值且都是可讀寫的,從來不會因為所謂的new、delete或malloc、free而被建立、銷燬。區別僅在於作業系統記憶體管理模組在你讀寫時是否能發現並是否採取相應動作而已。作業系統管理記憶體的粒度不是位元組而是頁,一頁通常為4KB。
VMMap 是程序虛擬和實體記憶體分析實用工具。http://technet.microsoft.com/zh-cn/sysinternals/dd535533
不能指望是否報錯來判斷是否越界;要指望是否觸發資料斷點:
2. ASCII碼的程式設計應用
標準的ASCII碼的範圍是0~127
常用小技巧:0~9、A~Z、a~z的ASCII碼分別是48~57、65~90、97~122 小寫字母比大寫字母的ASCII碼大32
3.輸入輸出的運用技巧及坑點
3.1 scanf()
####函式原型:int scanf(const char * restrict format,...);
!!!!!!函式 scanf() 是從標準輸入流stdio (標準輸入裝置,一般指向鍵盤)中讀內容的通用子程式,可以說明的格式讀入多個字元,並儲存在對應地址的變數中。
(鍵盤的輸入緩衝區由鍵盤驅動或鍵盤控制器實現,是記憶體的一塊區域。按下回車後,資料從鍵盤的輸入緩衝區,進入流緩衝區(系統給它另外單獨開了一塊記憶體不過跟鍵盤那個不在同一個位置),進而形成輸入流,提取運算子">>"才能從中提取資料。
輸入流的本質是檔案,開啟流即開啟檔案,如標準輸入流是stdin對應的檔案描述符為0,這是在系統層面,語言層面的輸入流會對應到系統層面的輸入流。)!!!!!!!!
####擴充套件閱讀(對C語言輸入輸出流和緩衝區的深入理解):https://wenku.baidu.com/view/99e57b3c360cba1aa911da78.html
函式的第一個引數是格式字串,它指定了輸入的格式,並按照格式說明符解析輸入對應位置的資訊並存儲於可變引數列表中對應的指標所指位置。每一個指標要求非空,並且與字串中的格式符一一順次對應。
返回值 :scanf函式返回成功讀入的資料項數,讀入資料時遇到了“檔案結束”則返回EOF。
空白字元和非空白字元
空白符:空白字元會使scanf函式在讀操作中略去輸入中的一個或多個空白字元。
非空白字元:一個非空白字元會使scanf()函式在讀入時剔除掉與這個非空白字元相同的字元。
####注意問題:
1.可以在格式化字串中的"%"各格式化規定符之間加入一個整數,表示任何讀操作中的最大位數
2.scanf中要求給出變數地址,如給出變數名則會出錯!!!!!!!!!!!!(這一點千萬不能忘了,不然會鬱悶死)
如 scanf("%d",a);是非法的,應改為scanf("%d",&a);才是合法的。
3在輸入多個數值資料時,若格式控制串中沒有非格式字元作輸入資料之間的間隔,則可用空格,TAB或回車作間隔。
C編譯在碰到空格,TAB,回車或非法資料(如對“%d”輸入“12A”時,A即為非法資料)時即認為該資料結束。.
4.如何讓scanf()函式正確接受有空格的字串?
scanf("%[^\n]",str);
5.鍵盤緩衝區殘餘資訊問題
fflush(stdin) ;getch();getchar();
6.處理scanf()函式誤輸入造成程式死鎖或出錯
scanf()函式執行成功時的返回值是成功讀取的變數數,也就是說,你這個scanf()函式有幾個變數,如果scanf()函式全部正常讀取,它就返回幾。但這裡還要注意另一個問題,如果輸入了非法資料,鍵盤緩衝區就可能還個有殘餘資訊問題。
3.2 getchar( )/getc(stdin)、putchar( )/putc(ch,stdout)
getchar由巨集實現:#define getchar() getc(stdin)。getchar有一個int型的返回值。當程式呼叫getchar時.程式就等著使用者按鍵。使用者輸入的字元被存放在鍵盤緩衝區中。直到使用者按回車為止(回車字元也放在緩衝區中)。當用戶鍵入回車之後,getchar才開始從stdio流中每次讀入一個字元。getchar函式的返回值是使用者輸入的字元的ASCII碼,若檔案結尾(End-Of-File)則返回-1(EOF),且將使用者輸入的字元回顯到螢幕。如使用者在按回車之前輸入了不止一個字元,其他字元會保留在鍵盤快取區中,等待後續getchar呼叫讀取。也就是說,後續的getchar呼叫不會等待使用者按鍵,而直接讀取緩衝區中的字元,直到緩衝區中的字元讀完後,才等待使用者按鍵。
#include<stdio.h>
int main{
char c1,c2,c3;
c1=getchar();
getchar(); //第二個字元‘b’雖然被接受了,但是沒有將它儲存在某個變數中;
c2=getchar();
c3=getchar();
putchar(c1);//putchar()輸出單個字元
putchar(c1);
putchar(c2);
putchar(c3);
return 0;
}輸入資料:
abcd
輸出結果:
acd
如果輸入“ab”,然後在按<Enter>鍵,再輸入‘c’,再按<Enter>鍵,輸出結果會是
a
c
3.3 gets、gets_s、puts、fgets
| char *gets( char *str ); |
(C11 中移除) | |
| char *gets_s( char *str, rsize_t n ); |
(C11 起) (可選) |
1) 從 stdin 讀入 str 所指向的字元陣列,直到發現換行符或出現檔案尾。在讀入陣列的最後一個字元後立即寫入空字元。換行符被捨棄,但不會儲存於緩衝區中。
2) 從 stdin 讀取字元直到發現換行符或出現檔案尾。至多寫入 n-1 個字元到 str 所指向的陣列,並始終寫入空終止字元(除非 str 是空指標)。若發現換行符,則忽略它並且不將它計入寫入緩衝區的字元數。
在執行時檢測下列錯誤,並呼叫當前安裝的制約處理函式:
n為零n大於 RSIZE_MAXstr是空指標- 在儲存 n-1 個字元到緩衝區後沒有遇到換行符或檔案尾。
任何情況下,gets_s 首先結束讀取並忽略來自 stdin 的字元,直到換行符、檔案尾條件,或在呼叫制約處理前的讀取錯誤。
同所有邊界檢查函式, gets_s 僅若實現定義了 __STDC_LIB_EXT1__ ,且使用者在包含 <stdio.h> 前定義 __STDC_WANT_LIB_EXT1__ 為整數常量 1 才保證可用。
(注意:gets識別換行符\n作為輸入結束,因此scanf完一個整數後,如果要使用gets,需要先用getchar接收整數後的換行符),
####scanf結束後的Enter保留在了輸入緩衝區中!!!!
puts
| int puts( const char *str ); |
寫入每個來自空終止字串 str 的字元及附加換行符 '\n' 到輸出流 stdout ,如同以重複執行 putc 寫入。
不寫入來自 str 的空終止字元。
####注意:puts 函式後附一個換行字元到輸出,而 fputs 不這麼做。
不同的實現返回不同的非負數:一些返回最後寫入的字元,一些返回寫入的字元數(或若字串長於 INT_MAX 則返回它),一些簡單地返回非負常量。
在重定向 stdout 到檔案時,導致 puts 失敗的典型原因是用盡了檔案系統的空間
gets()被拋棄,那我們用什麼來代替它的功能呢?
C11標準新增了gets_s()函式可以代替gets()函式,但是,該函式是stdio.h輸入輸出函式系類中的可選擴充套件,因此,即使編譯器支援C11標準,也有可能不支援gets_s()函式。
其實我們可以用c語言中的fgets()函式來代替gets()
我們先看一下函式原型宣告:
char *fgets(char *buf, int bufsize, FILE *stream);
注意一下第二個引數bufsize,這個引數就限制了讀取的字元的個數,這就可以解決gets()函式的缺陷。
我們知道fgets() 函式主要用於讀取檔案,如果要讀取鍵盤,則stream引數應該為stdin,
需要注意的是,如果bufsize設定為n,那麼fgets()函式最多讀取n-1個字元,之所以用“最多”這個詞是因為,如果在之前遇到了換行符,fgets函式也會返回。
還有一點就是,fgets()函式會讀取換行符(這一點和gets函式不同),當讀取結束後,fgets函式會為buf在末尾新增一個空字元作為字串的結束。
3.4 sscanf與sprintf

3.4.1 sscanf使用
sscanf(str,“%d”,&n);把字元陣列str中的內容以“%d”的格式寫到n中(和scanf一樣從左到右)
fprintf(str,"%d",n);把n以“d%"的格式寫的字元陣列中(還是從右至左)(類似sscanf)

第三章 入門篇(1)——入門模擬
1.P89_PAT_B1036:
####注意迴圈中的變數的作用域,
如無關聯的變數,在對應塊中使用不同變數名,可以避免這類問題的發生
2.P91_codeup_1928:
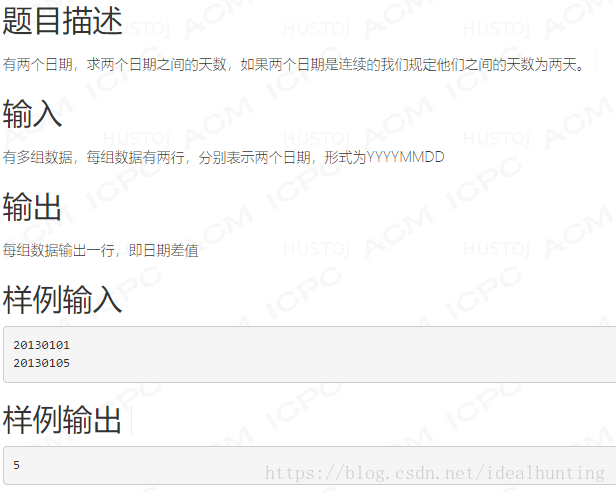
直接求解兩個日期的相差天數,實現較複雜,採取令日期相加,直到相等的方法入手
note1:bool isLeap(int year){//判斷是否是閏年
return(year%4==0&&year%100!=0)||(year%400==0);
###整型資料分割技巧:
while (num>0):
l.append(n%10)//拆分為n位對應的除數為10^n
n=n/10
l=list(reversed(l))#將順序倒過
####進位制轉換方法對於一個P進位制的數,如果要轉換為Q進位制,需要分為兩步:
1.將p進位制數x轉換為十進位制整數y.
對一個十進位制整數x轉換為十進位制數y。
對於一個十進位制的數y=d1d2...dn,它可以寫成這個形式:
y=d1*10^(n-1)+d2*10^(n-2)+...+dn-1*10+dn
同樣的,如果P進位制數x為a1a2...an,那麼它寫成下面這個形式之後使用十進位制的加法和乘法,就可以轉換為十進位制數y:
y=a1*P^(n-1)+a2*P^(n-2)+...+an-1*P+an
而這個公式可以用下面的迴圈實現:
int y=0,product=1; //product在迴圈中會不斷乘P,得到1、P、P^2、P^3...
while(x!=0){
y=y+(x%10)*product;//x%10是為了每次獲取x的個位數
x=x/10; //去掉x的個位
product=product*10;
}2.將十進位制數y轉換為Q進位制數z。
採用“除基取餘法”。所謂的“基”,是指將要轉換成的進位制Q,因此除基取餘的意思就是每次將待轉換數除以Q,然後將得到的餘數作為低位儲存,而商則繼續除以Q並進行上面的操作,最後當商為0時,將所有位從高到低輸出就可以得到z。舉一個例子,現在將十進位制數11轉換為二進位制數:
11除以2,得商為5,餘數為1;
5除以2,得商為2,餘數為1;
2除以2,得商為1,餘數為0;
1除以2,得商為0,餘數為1,演算法終止。
將餘數從後往前輸出,得1011即為11的二進位制數。
由此可以得到實現的程式碼(將十進位制數y轉換為Q進位制,結果放於陣列z):
int z[40],num=0; //陣列z存放Q進位制數y的每一位,num為位數
do{
z[num++]=y%Q; //除基取餘
y=y/Q;
}while(y!=0)以上內容來自相關blog、以及相關網站網站等整理形成 文中已給出連結,或許有些遺漏。但通過相關官方文件即可得到相關知識點內容,只是閱讀上的問題了,碰見語言相關問題 ,推進看官方文件學習http://www.cplusplus.com/reference/cmath/atan/