
深度學習常見演算法介紹與比較
很多人都有誤解,以為深度學習比機器學習先進。其實深度學習是機器學習的一個分支。可以理解為具有多層結構的模型。具體的話,深度學習是機器學習中的具有深層結構的神經網路演算法,即機器學習>神經網路演算法>深度神經網路(深度學習)。 關於深度學習的理論推導,太大太複雜,一些常見的深度學習演算法本人也是模模糊糊的,看過好多次的,隔斷時間就會忘記,現在對其系統的整理一下(從歷史,致命問題出發,再看具體演算法的思想,框架,優缺點和改進的方向,又總結了CNN和RNN的比較)。
一、歷史:多層感知機到神經網路,再到深度學習
神經網路技術起源於上世紀五、六十年代,當時叫感知機(perceptron),擁有輸入層、輸出層和一個隱含層。輸入的特徵向量通過隱含層變換達到輸出層,在輸出層得到分類結果。(扯一個不相關的:由於計算技術的落後,當時感知器傳輸函式是用線拉動變阻器改變電阻的方法機械實現的,腦補一下科學家們扯著密密麻麻的導線的樣子…)
心理學家Rosenblatt提出的單層感知機有一個嚴重得不能再嚴重的問題,即它對稍複雜一些的函式都無能為力(比如最為典型的“異或”操作)。
這個缺點直到上世紀八十年代才被Rumelhart、Williams、Hinton、LeCun等人發明的多層感知機解決,多層感知機解決了之前無法模擬異或邏輯的缺陷,同時更多的層數也讓網路更能夠刻畫現實世界中的複雜情形。
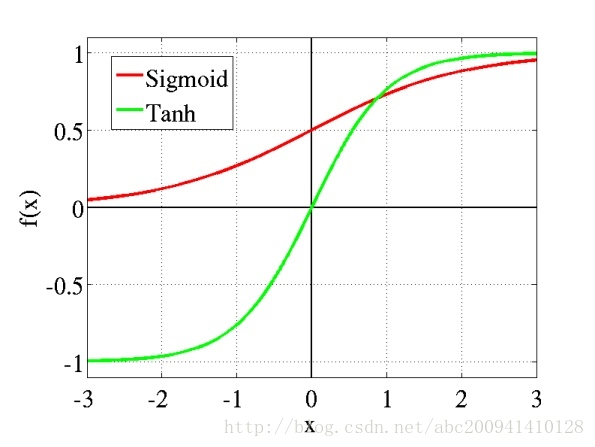
多層感知機可以擺脫早期離散傳輸函式的束縛,使用sigmoid或tanh等連續函式模擬神經元對激勵的響應,在訓練演算法上則使用Werbos發明的反向傳播BP演算法。這就是我們現在所說的【神經網路】,BP演算法也叫BP神經網路具體過程可參見我轉載的文章(
二、深度神經網路的致命問題
隨著神經網路層數的加深,有三個重大問題:一是非凸優化問題,即優化函式越來越容易陷入區域性最優解;二是(Gradient Vanish)梯度消失問題;三是過擬合問題。
2.1 非凸優化問題
線性迴歸,本質是一個多元一次函式的優化問題,設f(x,y)=x+y 多層神經網路,本質是一個多元K次函式優化問題,設f(x,y)=xy 線上性迴歸當中,從任意一個點出發搜尋,最終必然是下降到全域性最小值附近的。所以置0也無妨(這也是為什麼我們往往解線性迴歸方程時初值為0)。 而在多層神經網路中,從不同點出發,可能最終困在區域性最小值。區域性最小值是神經網路結構帶來的揮之不去的陰影,隨著隱層層數的增加,非凸的目標函式越來越複雜,區域性最小值點成倍增長,利用有限資料訓練的深層網路,效能還不如較淺層網路。。避免的方法一般是權值初始化。為了統一初始化方案,通常將輸入縮放到[−1,1],但是仍然無法保證能夠達到全域性最優,其實這也是科學家們一直在研究而未解決的問題。 所以,從本質上來看,深度結構帶來的非凸優化仍然不能解決(包括現在的各類深度學習演算法和其他非凸優化問題都是如此),這限制著深度結構的發展。
2.2 (Gradient Vanish)梯度消失問題
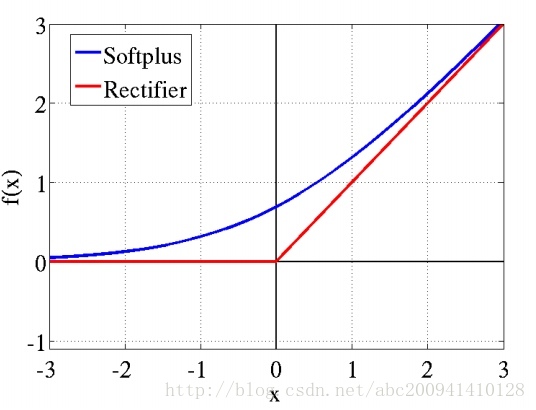
這個問題實際上是由啟用函式不當引起的,多層使用Sigmoid系函式,會使得誤差從輸出層開始呈指數衰減。在數學上,啟用函式的作用就是將輸入資料對映到0到1上(tanh是對映-1到+1上)。至於對映的原因,除了對資料進行正則化外,大概是控制資料,使其只在一定的範圍內。當然也有另外細節作用,例如Sigmoid(tanh)中,能在啟用的時候,更關注資料在零(或中心點)前後的細小變化,而忽略資料在極端時的變化,例如ReLU還有避免梯度消失的作用。通常,Sigmoid(tanh)多用於全連線層,而ReLU多用於卷積層。
2.3 過擬合問題
這就是神經網路的最後一個致命問題:過擬合,龐大的結構和引數使得,儘管訓練error降的很低,但是test error卻高的離譜。 過擬合還可以和Gradient Vanish、區域性最小值混合三打,具體玩法是這樣的: 由於Gradient Vanish,導致深度結構的較低層幾乎無法訓練,而較高層卻非常容易訓練。 較低層由於無法訓練,很容易把原始輸入資訊,沒有經過任何非線性變換,或者錯誤變換推到高層去,使得高層解離特徵壓力太大。 如果特徵無法解離,強制性的誤差監督訓練就會使得模型對輸入資料直接做擬合。 其結果就是,A Good Optimation But a Poor Generalization,這也是SVM、決策樹等淺層結構的毛病。 Bengio指出,這些利用區域性資料做優化的淺層結構基於先驗知識(Prior): Smoothness 即,給定樣本(xi,yi),儘可能從數值上做優化,使得訓練出來的模型,對於近似的x,輸出近似的y。 然而一旦輸入值做了泛型遷移,比如兩種不同的鳥,鳥的顏色有別,且在影象中的比例不一,那麼SVM、決策樹幾乎毫無用處。 因為,對輸入資料簡單地做數值化學習,而不是解離出特徵,對於高維資料(如影象、聲音、文字),是毫無意義的。 然後就是最後的事了,由於低層學不動,高層在亂學,所以很快就掉進了吸引盆中,完成神經網路三殺。
三、深度學習裡面的基本模型
深度學習裡面的基本模型大致分為了3類:多層感知機模型;深度神經網路模型和遞迴神經網路模型。其代表分別是DBN(Deep belief network) 深度信念網路、CNN(Convolution Neural Networks)卷積神經網路、RNN(Recurrent neural network) 遞迴神經網路。
3.1 DBN(Deep belief network) 深度信念網路
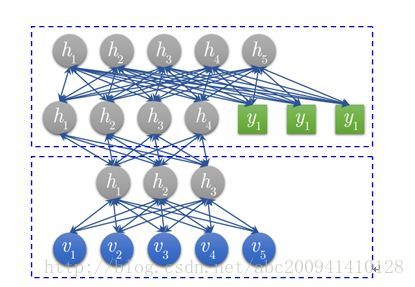
2006年,Geoffrey Hinton提出深度信念網路(DBN)及其高效的學習演算法,即Pre-training+Fine tuning,並發表於《Science》上,成為其後深度學習演算法的主要框架。DBN是一種生成模型,通過訓練其神經元間的權重,我們可以讓整個神經網路按照最大概率來生成訓練資料。所以,我們不僅可以使用DBN識別特徵、分類資料,還可以用它來生成資料。
3.1.1 網路結構
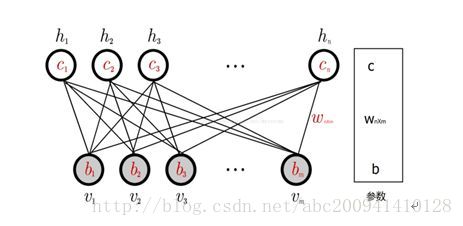
深度信念網路(DBN)由若干層受限玻爾茲曼機(RBM)堆疊而成,上一層RBM的隱層作為下一層RBM的可見層。
(1) RBM
3.1.2 訓練過程和優缺點
DBN的訓練包括Pre-training和Fine tuning兩步,其中Pre-training過程相當於逐層訓練每一個RBM,經過Pre-training的DBN已經可用於模擬訓練資料,而為了進一步提高網路的判別效能, Fine tuning過程利用標籤資料通過BP演算法對網路引數進行微調。 對DBN優缺點的總結主要集中在生成模型與判別模型的優缺點總結上。 1、優點:
- 生成模型學習聯合概率密度分佈,所以就可以從統計的角度表示資料的分佈情況,能夠反映同類資料本身的相似度;
- 生成模型可以還原出條件概率分佈,此時相當於判別模型,而判別模型無法得到聯合分佈,所以不能當成生成模型使用。
2、缺點: - 生成模型不關心不同類別之間的最優分類面到底在哪兒,所以用於分類問題時,分類精度可能沒有判別模型高; - 由於生成模型學習的是資料的聯合分佈,因此在某種程度上學習問題的複雜性更高。 - 要求輸入資料具有平移不變性。
3.1.3 改進模型
DBN的變體比較多,它的改進主要集中於其組成“零件”RBM的改進,有卷積DBN(CDBN)和條件RBM(Conditional RBM)等。 DBN並沒有考慮到影象的二維結構資訊,因為輸入是簡單的將一個影象矩陣轉換為一維向量。而CDBN利用鄰域畫素的空域關係,通過一個稱為卷積RBM(CRBM)的模型達到生成模型的變換不變性,而且可以容易得變換到高維影象。 DBN並沒有明確地處理對觀察變數的時間聯絡的學習上,Conditional RBM通過考慮前一時刻的可見層單元變數作為附加的條件輸入,以模擬序列資料,這種變體在語音訊號處理領域應用較多。
3.2 CNN(Convolution Neural Networks)卷積神經網路
卷積神經網路是人工神經網路的一種,已成為當前語音分析和影象識別領域的研究熱點。它的權值共享網路結構使之更類似於生物神經網路,降低了網路模型的複雜度,減少了權值的數量。該優點在網路的輸入是多維影象時表現的更為明顯,使影象可以直接作為網路的輸入,避免了傳統識別演算法中複雜的特徵提取和資料重建過程。 全連結DNN的結構裡下層神經元和所有上層神經元都能夠形成連線,帶來了引數數量的膨脹問題。例如,1000*1000的畫素影象,光這一層就有10^12個權重需要訓練。此時我們可以用卷積神經網路CNN,對於CNN來說,並不是所有上下層神經元都能直接相連,而是通過“卷積核”作為中介。同一個卷積核在所有影象內是共享的,影象通過卷積操作後仍然保留原先的位置關係。影象輸入層到隱含層的引數瞬間降低到了100*100*100=10^6個 卷積網路是為識別二維形狀而特殊設計的一個多層感知器,這種網路結構對平移、比例縮放、傾斜或者共他形式的變形具有高度不變性。
3.2.1 網路結構
卷積神經網路是一個多層的神經網路,其基本運算單元包括:卷積運算、池化運算、全連線運算和識別運算。
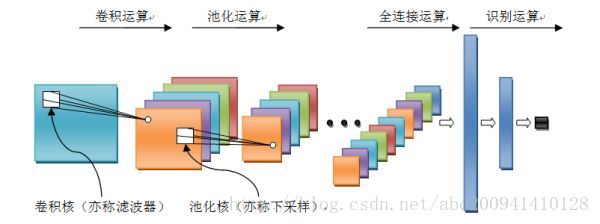
- 卷積運算:前一層的特徵圖與一個可學習的卷積核進行卷積運算,卷積的結果經過啟用函式後的輸出形成這一層的神經元,從而構成該層特徵圖,也稱特徵提取層,每個神經元的輸入與前一層的區域性感受野相連線,並提取該區域性的特徵,一旦該區域性特徵被提取,它與其它特徵之間的位置關係就被確定。l
- 池化運算:能很好的聚合特徵、降維來減少運算量。它把輸入訊號分割成不重疊的區域,對於每個區域通過池化(下采樣)運算來降低網路的空間解析度,比如最大值池化是選擇區域內的最大值,均值池化是計算區域內的平均值。通過該運算來消除訊號的偏移和扭曲。
- 全連線運算:輸入訊號經過多次卷積核池化運算後,輸出為多組訊號,經過全連線運算,將多組訊號依次組合為一組訊號。 識別運算:上述運算過程為特徵學習運算,需在上述運算基礎上根據業務需求(分類或迴歸問題)增加一層網路用於分類或迴歸計算。
3.2.2 訓練過程和優缺點
卷積網路在本質上是一種輸入到輸出的對映,它能夠學習大量的輸入與輸出之間的對映關係,而不需要任何輸入和輸出之間的精確的數學表示式,只要用已知的模式對卷積網路加以訓練,網路就具有輸入輸出對之間的對映能力。卷積網路執行的是有監督訓練,所以其樣本集是由形如:(輸入訊號,標籤值)的向量對構成的。
1、優點: - 權重共享策略減少了需要訓練的引數,相同的權重可以讓濾波器不受訊號位置的影響來檢測訊號的特性,使得訓練出來的模型的泛化能力更強; - 池化運算可以降低網路的空間解析度,從而消除訊號的微小偏移和扭曲,從而對輸入資料的平移不變性要求不高。
2、缺點: - 深度模型容易出現梯度消散問題。
3.2.3 改進模型
卷積神經網路因為其在各個領域中取得了好的效果,是近幾年來研究和應用最為廣泛的深度神經網路。比較有名的卷積神經網路模型主要包括1986年Lenet,2012年的Alexnet,2014年的GoogleNet,2014年的VGG,2015年的Deep Residual Learning。這些卷積神經網路的改進版本或者模型的深度,或者模型的組織結構有一定的差異,但是組成模型的機構構建是相同的,基本都包含了卷積運算、池化運算、全連線運算和識別運算。
3.3 RNN(Recurrent neural network) 遞迴神經網路
全連線的DNN除了以上問題以外還存在著另一個問題——無法對時間序列上的變化進行建模。然而,樣本出現的時間順序對於自然語言處理、語音識別、手寫體識別等應用非常重要。對了適應這種需求,就出現了題主所說的另一種神經網路結構——迴圈神經網路RNN(不知道為什麼很多叫迴圈的。計算機術語裡迴圈一般是同一層次的,Recurrent 其實是時間遞迴,所以本文叫他遞迴神經網路)。 在普通的全連線網路或CNN中,每層神經元的訊號只能向上一層傳播,樣本的處理在各個時刻獨立,因此又被成為前向神經網路(Feed-forward Neural Networks)。而在RNN中,神經元的輸出可以在下一個時間戳直接作用到自身。 即:(t+1)時刻網路的最終結果O(t+1)是該時刻輸入和所有歷史共同作用的結果。RNN可以看成一個在時間上傳遞的神經網路,它的深度是時間的長度!正如我們上面所說,“梯度消失”現象又要出現了,只不過這次發生在時間軸上 為了解決時間上的梯度消失,機器學習領域發展出了長短時記憶單元(LSTM),通過門的開關實現時間上記憶功能,並防止梯度消失。
3.3.1 網路結構
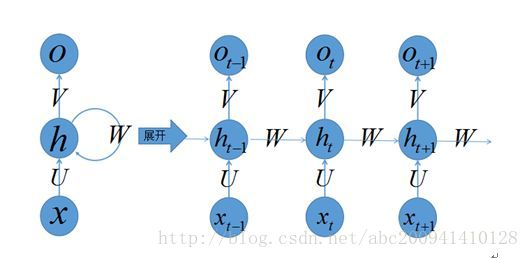
3.3.2 訓練過程和優缺點
遞迴神經網路中由於輸入時疊加了之前的訊號,所以反向傳導時不同於傳統的神經網路,因為對於時刻t的輸入層,其殘差不僅來自於輸出,還來自於之後的隱層。通過反向傳遞演算法,利用輸出層的誤差,求解各個權重的梯度,然後利用梯度下降法更新各個權重。 1、優點:
- 模型是時間維度上的深度模型,可以對序列內容建模。
2、缺點: - 需要訓練的引數較多,容易出現梯度消散或梯度爆炸問題; - 不具有特徵學習能力。
3.3.3 改進模型
遞迴神經網路模型可以用來處理序列資料,遞迴神經網路包含了大量引數,且難於訓練(時間維度的梯度消散或梯度爆炸),所以出現一系列對RNN優化,比如網路結構、求解演算法與並行化。 近年來bidirectional RNN (BRNN)與 LSTM在image captioning, language translation, and handwriting recognition這幾個方向上有了突破性進展 。
3.4 混合結構
除了以上三種網路,和我之前提到的深度殘差學習、LSTM外,深度學習還有許多其他的結構。舉個例子,RNN既然能繼承歷史資訊,是不是也能吸收點未來的資訊呢?因為在序列訊號分析中,如果我能預知未來,對識別一定也是有所幫助的。因此就有了雙向RNN、雙向LSTM,同時利用歷史和未來的資訊。雙向RNN、雙向LSTM,同時利用歷史和未來的資訊。 事實上,不論是那種網路,他們在實際應用中常常都混合著使用,比如CNN和RNN在上層輸出之前往往會接上全連線層,很難說某個網路到底屬於哪個類別。 不難想象隨著深度學習熱度的延續,更靈活的組合方式、更多的網路結構將被髮展出來。儘管看起來千變萬化,但研究者們的出發點肯定都是為了解決特定的問題。如果想進行這方面的研究,不妨仔細分析一下這些結構各自的特點以及它們達成目標的手段。
3.5 CNN和RNN的比較
RNN的重要特性是可以處理不定長的輸入,得到一定的輸出。當你的輸入可長可短, 比如訓練翻譯模型的時候, 你的句子長度都不固定,你是無法像一個訓練固定畫素的影象那樣用CNN搞定的。而利用RNN的迴圈特性可以輕鬆搞定。 在序列訊號的應用上,CNN是隻響應預先設定的訊號長度(輸入向量的長度),RNN的響應長度是學習出來的。
CNN對特徵的響應是線性的,RNN在這個遞進方向上是非線性響應的。這也帶來了很大的差別。
CNN 專門解決影象問題的,可用把它看作特徵提取層,放在輸入層上,最後用MLP 做分類。 RNN 專門解決時間序列問題的,用來提取時間序列資訊,放在特徵提取層(如CNN)之後。
RNN,遞迴型網路,用於序列資料,並且有了一定的記憶效應,輔之以lstm。 CNN應該側重空間對映,影象資料尤為貼合此場景。
CNN 卷積擅長從區域性特徵逼近整體特徵, RNN 擅長對付時間序列。
四、一些基本概念和知識
4.1 線性迴歸、線性神經網路、Logistic/Softmax迴歸
4.2 關於卷積、池化、啟用函式等
4.3 推薦一個比較好的入門資料
@[TOC](這裡寫自定義目錄標題)歡迎使用Markdown編輯器
你好! 這是你第一次使用 Markdown編輯器 所展示的歡迎頁。如果你想學習如何使用Markdown編仔細閱讀這篇文章,瞭解一下Markdown的基本語法知識。
新的改變
我們對Markdown編輯器進行了一些功能拓展與語法支援,除了標準的Markdown編輯器功能,我們增加了如下幾點新功能,幫助你用它寫部落格:
- 全新的介面設計 ,將會帶來全新的寫作體驗;
- 在創作中心設定你喜愛的程式碼高亮樣式,Markdown 將程式碼片顯示選擇的高亮樣式 進行展示;
- 增加了 圖片拖拽 功能,你可以將本地的圖片直接拖拽到編輯區域直接展示;
- 全新的 KaTeX數學公式 語法;
- 增加了支援甘特圖的mermaid語法1 功能;
- 增加了 多螢幕編輯 Markdown文章功能;
- 增加了 焦點寫作模式、預覽模式、簡潔寫作模式、左右區域同步滾輪設定 等功能,功能按鈕位於編輯區域與預覽區域中間;
- 增加了 檢查列表 功能。
功能快捷鍵
撤銷:Ctrl/Command + Z 重做:Ctrl/Command + Y 加粗:Ctrl/Command + B 斜體:Ctrl/Command + I 標題:Ctrl/Command + Shift + H 無序列表:Ctrl/Command + Shift + U 有序列表:Ctrl/Command + Shift + O 檢查列表:Ctrl/Command + Shift + C 插入程式碼:Ctrl/Command + Shift + K 插入連結:Ctrl/Command + Shift + L 插入圖片:Ctrl/Command + Shift + G
合理的建立標題,有助於目錄的生成
直接輸入1次#,並按下space後,將生成1級標題。
輸入2次#,並按下space後,將生成2級標題。
以此類推,我們支援6級標題。有助於使用TOC語法後生成一個完美的目錄。
如何改變文字的樣式
強調文字 強調文字
加粗文字 加粗文字
標記文字
刪除文字
引用文字
H2O is是液體。
210 運算結果是 1024.
插入連結與圖片
連結: link.
圖片: 
帶尺寸的圖片: ![]()
當然,我們為了讓使用者更加便捷,我們增加了圖片拖拽功能。
如何插入一段漂亮的程式碼片
去部落格設定頁面,選擇一款你喜歡的程式碼片高亮樣式,下面展示同樣高亮的 程式碼片.
// An highlighted block
var foo = 'bar';
生成一個適合你的列表
- 專案
- 專案
- 專案
- 專案
- 專案1
- 專案2
- 專案3
- 計劃任務
- 完成任務
建立一個表格
一個簡單的表格是這麼建立的:
| 專案 | Value |
|---|---|
| 電腦 | $1600 |
| 手機 | $12 |
| 導管 | $1 |
設定內容居中、居左、居右
使用:---------:居中
使用:----------居左
使用----------:居右
| 第一列 | 第二列 | 第三列 |
|---|---|---|
| 第一列文字居中 | 第二列文字居右 | 第三列文字居左 |
SmartyPants
SmartyPants將ASCII標點字元轉換為“智慧”印刷標點HTML實體。例如:
| TYPE | ASCII | HTML |
|---|---|---|
| Single backticks | 'Isn't this fun?' |
‘Isn’t this fun?’ |
| Quotes | "Isn't this fun?" |
“Isn’t this fun?” |
| Dashes | -- is en-dash, --- is em-dash |
– is en-dash, — is em-dash |
建立一個自定義列表
- Markdown
- Text-to-HTML conversion tool
- Authors
- John
- Luke
如何建立一個註腳
一個具有註腳的文字。2
註釋也是必不可少的
Markdown將文字轉換為 HTML。
KaTeX數學公式
您可以使用渲染LaTeX數學表示式 KaTeX:
Gamma公式展示 是通過尤拉積分
你可以找到更多關於的資訊 LaTeX 數學表示式here.
新的甘特圖功能,豐富你的文章
- 關於 甘特圖 語法,參考 這兒,
UML 圖表
可以使用UML圖表進行渲染。 Mermaid. 例如下面產生的一個序列圖::
這將產生一個流程圖。:
- 關於 Mermaid 語法,參考 這兒,
FLowchart流程圖
我們依舊會支援flowchart的流程圖:
- 關於 Flowchart流程圖 語法,參考 這兒.
匯出與匯入
匯出
如果你想嘗試使用此編輯器, 你可以在此篇文章任意編輯。當你完成了一篇文章的寫作, 在上方工具欄找到 文章匯出 ,生成一個.md檔案或者.html檔案進行本地儲存。
匯入
如果你想載入一篇你寫過的.md檔案或者.html檔案,在上方工具欄可以選擇匯入功能進行對應副檔名的檔案匯入, 繼續你的創作。