
spark-shuffle分析
前言
shuffle是分散式計算系統中最重要的一部分,spark和mapreduce的shuffle的大體思路類似,在實現上有一些區分。Spark提供了外掛式的介面,使用者可以通過繼承ShuffleManager來自定義,並通過`spark.shuffle.manager`來宣告自定義的ShuffleManager。
shuffle-write
shuffle-write在shuffle中是最重要的,包括資料的儲存包括記憶體和磁碟兩部分,資料檔案包括資料實體檔案和索引檔案。整體思路為資料優先儲存在記憶體,如果資料量過大,那麼spill到磁碟。spill到磁碟採用了單檔案的方式,在一個檔案裡分為多個段,一個task的shuffle資料輸出到檔案的一個段,另外再寫一個index檔案,記錄段在檔案中的位置資訊,所以spark的shuffle過程中在map階段只會產出兩個檔案。參考圖1,大致描繪出了檔案的樣子,整個流程可以拆解成3個步驟來看,下面結合程式碼進行詳細分析。
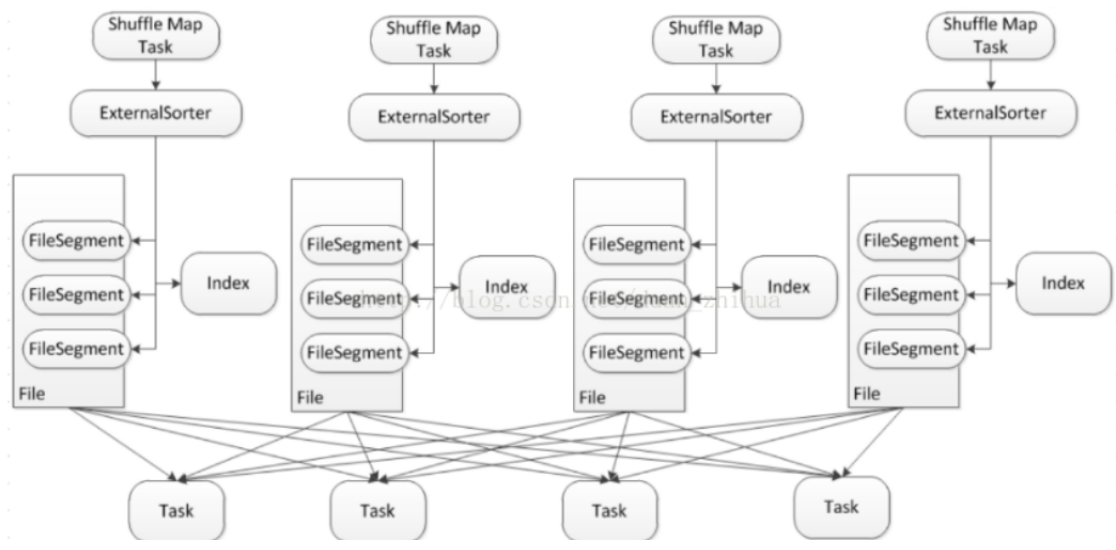
圖1
接收shuffle資料
首先shuffleWrite的入口是SortShuffleWriter,這是spark預設的ShuffleWriter例項。每個spark的task都會呼叫write()方法將shuffle資料傳入,其內部再通過委託的方式,代理給ExternalSorter進行真正的處理,這裡需要注意的是每次呼叫都會建立一個新的ExternalSort物件,也就是說ExternalSort這個類在task層面來說是無狀態的,所有的狀態都儲存在檔案中,再通過ExternalSort.insertAll()方法將資料記錄起來,這其中分為兩步,1.首先將資料快取在記憶體裡;2.檢查是否需要將記憶體中的資料spill到磁碟,這是通過繼承Spillable類,呼叫maybeSpill()方法,思路是比較記憶體中的資料大小和還能申請到的記憶體大小。。
如果檢查發現需要spill,那麼就呼叫spillMemoryIteratorToDisk()方法,生成一個UUID作為該spill資料的blockId,再通過DiskBlockObjectWriter類將資料寫到磁碟。這裡對DiskBlockObjectWriter類做下分析,因為這個類很重要,所有spill的資料都是通過這個類落盤的。首先DiskBlockObjectWriter通過實現一套事務的機制來保證寫資料沒有問題,原理如下,1.定義3個position,分別追蹤已經commit成功的資料position,已經度量過的資料position(這個重點是用於統計資訊)和正在寫的資料position。並通過FileChannel特性來進行position回滾,當寫資料出現問題,就truncate到上一次commit成功的position。在落盤之前,spark還會對資料進行排序(如果需要的話),最後通過遍歷所有的partition,將每個partition通過DiskBlockObjectWriter寫入磁碟,返回一個FileSegment,包含了資料在檔案中的position以及長度,partition和FileSegment是一一對應的。
如果不需要spill,那麼資料會被臨時快取在記憶體中,下面分析一下在記憶體中的資料結構, spark採用了兩個容器來分別對待是否需要在map端做合併的資料,如果需要在map端合併,那麼使用類`PartitionedAppendOnlyMap`,如果不需要在map端合併,那麼使用類`PartitionedPairBuffer`。PartitionedAppendOnlyMap和PartitionedPairBuffer底層都使用了hash表的概念,但是沒有用java或者scala的map庫,而是自己基於陣列實現了一個簡易的hash表,通過對key的hash(key由partition+資料的key組成)來決定在陣列中的位置,合併後的value儲存在key的後一位。這個兩個容器的區別在於,需要在map端shuffle合併的value會經常發生更新,而key是固定不變的,這也是為什麼沒有複用程式碼的原因,通用的工具在效率上肯定是沒有專用的高的。
到這裡,SortShuffleWriter.write()中ExternalSorter.insertAll()分析結束。
寫shuffle資料到磁碟
下一個重要的方法是SortShuffleWriter.write()中的ExternalSorter.writePartitionedFile(),如果之前有spill的檔案,那麼會進行合併,合併的物件是spill檔案以及在記憶體中的資料,如果之前沒有spill的檔案,那麼直接將記憶體中的資料寫到檔案,這樣保證了一個exectuor永遠只需要委會一份spill檔案。資料檔名格式為shuffleId+MapId+reduceId。注意,這裡除了合併資料之外,還會對需要aggregate的資料進行聚合,對需要排序的資料進行排序。合併過程是通過為每個partition生成一個迭代器,然後遍歷所有與迭代器,寫到新的spill檔案中。
寫index檔案到磁碟
最後一步就是寫index檔案,參考類`IndexShuffleBlockResolver`,將每個partition的資料長度依次寫到index臨時檔案中,然後進行校驗,檢查資料檔案和index檔案中的資料長度是否一致(這裡涉及到一個多執行緒的問題,由於一個executor只維護一份index檔案,所以可能有多個task操作同一個index檔案,這裡採用了synchronized,也就是獨佔鎖)。如果校驗成功,那麼說明index檔案已經被成功更新,那麼放棄此次更新,如果不成功,那麼說明這是第一次更新成功,把index的臨時檔名改為正式的index檔名。臨時檔名是在正式檔名加上.uuid字尾。
shuffle-read
說完了shuffle write過程,下面分析一下shuffle read過程。shuffle read從整體看可以分為2大部分,下面基於類`BlockStoreShuffleReader`詳細分析。
資料拉取
資料拉取分為兩個部分,一個是本地資料拉取,也就是shuffle spill的檔案正好和讀取的executor位於同一個節點,另一個是遠端資料拉取,基於netty獲取遠端資料。整個過程也是優先記憶體,然後spill到磁碟的方式。參考`ShuffleBlockFecherIterator`,大致思路是,在初始化的時候先嚐試拉一批資料,這樣在迭代器遍歷的時候(next操作)可以直接返回,如果資料遍歷完了,那麼再嘗試拉一批資料,這種思路可以看做是lazy load的方式。
資料處理
這步的資料輸入是上一步拉取到的資料,也就是說資料存在於記憶體和磁碟。然後和shuffle-write中的接收資料類似,spark通過實現一個容器`ExternalAppendOnlyMap`來快取拉取到的資料,過程中會對聚合等操作做處理,如果記憶體空間不足也會spill到磁碟。所以在大資料量的情況下這裡真的是瓶頸,需要兩個磁碟IO。資料處理完後再通過`ExternalAppendOnlyMap.ExternalIterator`對外提供整合記憶體和磁碟資料的迭代器,讓上層對資料的儲存介質不敏感。
配置
| key |
預設 |
解釋 |
| spark.reducer.maxSizeInFlight |
48m |
shuffle-read每次進行資料拉取的資料量上限,如果executor記憶體充足,可以調大 |
| spark.reducer.maxReqsInFlight |
Int.MaxValue |
迭代器中觸發next後最多可以請求的次數。一般不做限制 |
| spark.reducer.maxBlocksInFlightPerAddress |
Long.MaxValue |
shuffle-read每次請求一個地址時獲取最多的block數量。如果block資料很多,可能會導致提供block的exxcutor壓力過大 |
| spark.shuffle.file.buffer |
32k |
shuffle中所有涉及寫檔案時指定的outputStream中的buffer大小 |
總結
shuffle是分散式計算引擎的核心技術,也是最大的效能瓶頸。SortShuffle 相比HashShuffle極大的減少了中間檔案的產生,但還是避免不了資料大量的寫磁碟操作。瞭解了原理後,在用spark框架的時候需要儘量減少shuffle的資料量,優先做一些在map端的聚合。
參考資料
// spark 2.1.0程式碼
// 很詳細的基於程式碼的分析
https://blog.csdn.net/duan_zhihua/article/details/71190682