
Spark Shuffle原理和Shuffle的問題解決和優化
摘要:
1 shuffle原理
1.1 mapreduce的shuffle原理
1.1.1 map task端操作
1.1.2 reduce task端操作
1.2 spark現在的SortShuffleManager
2 Shuffle操作問題解決
2.1 資料傾斜原理
2.2 資料傾斜問題發現與解決
2.3 資料傾斜解決方案
3 spark RDD中的shuffle運算元
3.1 去重
3.2 聚合
3.3 排序
3.4 重分割槽
3.5 集合操作和表操作
4 spark shuffle引數調優
內容:
1 shuffle原理
概述:Shuffle描述著資料從map task輸出到reduce task輸入的這段過程。在分散式情況下,reduce task需要跨節點去拉取其它節點上的map task結果。這一過程將會產生網路資源消耗和記憶體,磁碟IO的消耗。
1.1 mapreduce的shuffle原理
1.1.1 map task端操作
每個map task都有一個記憶體緩衝區(預設是100MB),儲存著map的輸出結果,當緩衝區快滿的時候需要將緩衝區的資料以一個臨時檔案的方式存放到磁碟,當整個map task結束後再對磁碟中這個map task產生的所有臨時檔案做合併,生成最終的正式輸出檔案,然後等待reduce task來拉資料。
Spill過程:這個從記憶體往磁碟寫資料的過程被稱為Spill,中文可譯為溢寫。整個緩衝區有個溢寫的比例spill.percent(預設是0.8),當達到閥值時map task 可以繼續往剩餘的memory寫,同時溢寫執行緒鎖定已用memory,先對key(序列化的位元組)做排序,如果client程式設定了Combiner,那麼在溢寫的過程中就會進行區域性聚合。
Merge過程:每次溢寫都會生成一個臨時檔案,在map task真正完成時會將這些檔案歸併成一個檔案,這個過程叫做Merge。
1.1.2 reduce task端操作
當某臺TaskTracker上的所有map task執行完成,對應節點的reduce task開始啟動,簡單地說,此階段就是不斷地拉取(Fetcher)每個map task所在節點的最終結果,然後不斷地做merge形成reduce task的輸入檔案。
Copy過程:Reduce程序啟動一些資料copy執行緒(Fetcher)通過HTTP協議拉取TaskTracker的map階段輸出檔案
Merge過程:Copy過來的資料會先放入記憶體緩衝區(基於JVM的heap size設定),如果記憶體緩衝區不足也會發生map task的spill(sort 預設,combine 可選),多個溢寫檔案時會發生map task的merge
下面總結下mapreduce的關鍵詞:
儲存相關的有:記憶體緩衝區,預設大小,溢寫閥值
主要過程:溢寫(spill),排序,合併(combine),歸併(Merge),Copy或Fetch
相關引數:記憶體緩衝區預設大小,JVM heap size,spill.percent
詳細
關於排序方法:
在Map階段,k-v溢寫時,採用的正是快排;而溢位檔案的合併使用的則是歸併;在Reduce階段,通過shuffle從Map獲取的檔案進行合併的時候採用的也是歸併;最後階段則使用了堆排作最後的合併過程。
1.2 spark現在的SortShuffleManager
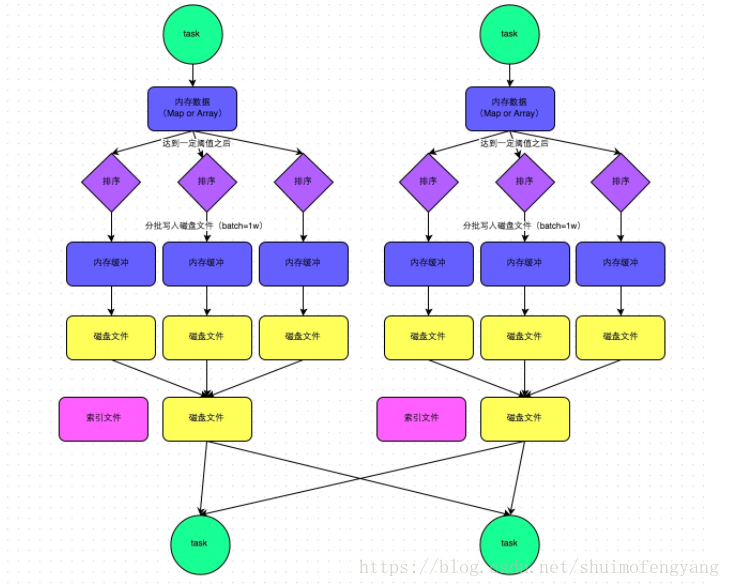
SortShuffleManager執行原理
SortShuffleManager的執行機制主要分成兩種,一種是普通執行機制,另一種是bypass執行機制。當shuffle read task的數量小於等於spark.shuffle.sort.bypassMergeThreshold引數的值時(預設為200),就會啟用bypass機制。
普通執行機制
下圖說明了普通的SortShuffleManager的原理。在該模式下,資料會先寫入一個記憶體資料結構中,此時根據不同的shuffle運算元,可能選用不同的資料結構。如果是reduceByKey這種聚合類的shuffle運算元,那麼會選用Map資料結構,一邊通過Map進行聚合,一邊寫入記憶體;如果是join這種普通的shuffle運算元,那麼會選用Array資料結構,直接寫入記憶體。接著,每寫一條資料進入記憶體資料結構之後,就會判斷一下,是否達到了某個臨界閾值。如果達到臨界閾值的話,那麼就會嘗試將記憶體資料結構中的資料溢寫到磁碟,然後清空記憶體資料結構。
在溢寫到磁碟檔案之前,會先根據key對記憶體資料結構中已有的資料進行排序。排序過後,會分批將資料寫入磁碟檔案。預設的batch數量是10000條,也就是說,排序好的資料,會以每批1萬條資料的形式分批寫入磁碟檔案。寫入磁碟檔案是通過Java的BufferedOutputStream實現的。BufferedOutputStream是Java的緩衝輸出流,首先會將資料緩衝在記憶體中,當記憶體緩衝滿溢之後再一次寫入磁碟檔案中,這樣可以減少磁碟IO次數,提升效能。
一個task將所有資料寫入記憶體資料結構的過程中,會發生多次磁碟溢寫操作,也就會產生多個臨時檔案。最後會將之前所有的臨時磁碟檔案都進行合併,這就是merge過程,此時會將之前所有臨時磁碟檔案中的資料讀取出來,然後依次寫入最終的磁碟檔案之中。此外,由於一個task就只對應一個磁碟檔案,也就意味著該task為下游stage的task準備的資料都在這一個檔案中,因此還會單獨寫一份索引檔案,其中標識了下游各個task的資料在檔案中的start offset與end offset。
SortShuffleManager由於有一個磁碟檔案merge的過程,因此大大減少了檔案數量。比如第一個stage有50個task,總共有10個Executor,每個Executor執行5個task,而第二個stage有100個task。由於每個task最終只有一個磁碟檔案,因此此時每個Executor上只有5個磁碟檔案,所有Executor只有50個磁碟檔案。
bypass執行機制
下圖說明了bypass SortShuffleManager的原理。bypass執行機制的觸發條件如下:
shuffle map task數量小於spark.shuffle.sort.bypassMergeThreshold引數的值(預設為200)。
不是排序類的shuffle運算元(比如reduceByKey)。
此時task會為每個下游task都建立一個臨時磁碟檔案,並將資料按key進行hash然後根據key的hash值,將key寫入對應的磁碟檔案之中。當然,寫入磁碟檔案時也是先寫入記憶體緩衝,緩衝寫滿之後再溢寫到磁碟檔案的。最後,同樣會將所有臨時磁碟檔案都合併成一個磁碟檔案,並建立一個單獨的索引檔案。
該過程的磁碟寫機制其實跟未經優化的HashShuffleManager是一模一樣的,因為都要建立數量驚人的磁碟檔案,只是在最後會做一個磁碟檔案的合併而已。因此少量的最終磁碟檔案,也讓該機制相對未經優化的HashShuffleManager來說,shuffle read的效能會更好。
而該機制與普通SortShuffleManager執行機制的不同在於:第一,磁碟寫機制不同;第二,不會進行排序。也就是說,啟用該機制的最大好處在於,shuffle write過程中,不需要進行資料的排序操作,也就節省掉了這部分的效能開銷。
2 Shuffle操作問題解決
2.1 資料傾斜原理
在進行shuffle的時候,必須將各個節點上相同的key拉取到某個節點上的一個task來進行處理,此時如果某個key對應的資料量特別大的話,就會發生資料傾斜
2.2 資料傾斜問題發現與定位
通過Spark Web UI來檢視當前執行的stage各個task分配的資料量,從而進一步確定是不是task分配的資料不均勻導致了資料傾斜。
知道資料傾斜發生在哪一個stage之後,接著我們就需要根據stage劃分原理,推算出來發生傾斜的那個stage對應程式碼中的哪一部分,這部分程式碼中肯定會有一個shuffle類運算元。通過countByKey檢視各個key的分佈。
2.3 資料傾斜解決方案
2.3.1 過濾少數導致傾斜的key
2.3.2 提高shuffle操作的並行度
2.3.3 區域性聚合和全域性聚合
方案實現思路:這個方案的核心實現思路就是進行兩階段聚合。第一次是區域性聚合,先給每個key都打上一個隨機數,比如10以內的隨機數,此時原先一樣的key就變成不一樣的了,比如(hello, 1) (hello, 1) (hello, 1) (hello, 1),就會變成(1_hello, 1) (1_hello, 1) (2_hello, 1) (2_hello, 1)。接著對打上隨機數後的資料,執行reduceByKey等聚合操作,進行區域性聚合,那麼區域性聚合結果,就會變成了(1_hello, 2) (2_hello, 2)。然後將各個key的字首給去掉,就會變成(hello,2)(hello,2),再次進行全域性聚合操作,就可以得到最終結果了,比如(hello, 4)。
程式碼:

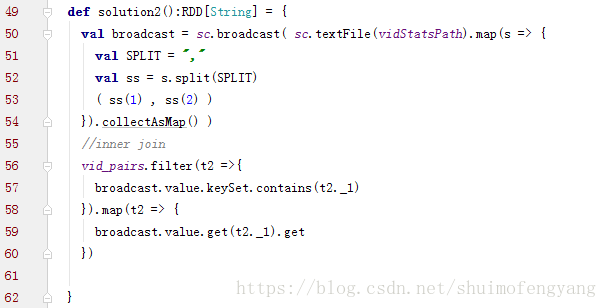
2.3.4 將reduce join轉為map join((小表幾百M或者一兩G))
方案實現思路:不使用join運算元進行連線操作,而使用Broadcast變數與map類運算元實現join操作,進而完全規避掉shuffle類的操作,徹底避免資料傾斜的發生和出現。將較小RDD中的資料直接通過collect運算元拉取到Driver端的記憶體中來,然後對其建立一個Broadcast變數;接著對另外一個RDD執行map類運算元,在運算元函式內,從Broadcast變數中獲取較小RDD的全量資料,與當前RDD的每一條資料按照連線key進行比對,如果連線key相同的話,那麼就將兩個RDD的資料用你需要的方式連線起來。
程式碼:
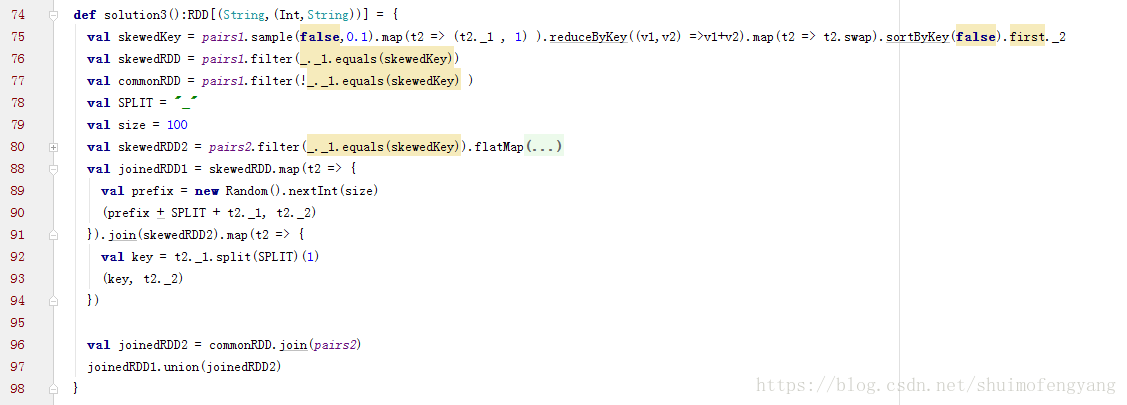
2.3.5 取樣傾斜key並分拆join操作(join的兩表都很大,但僅一個RDD的幾個key的資料量過大)
方案實現思路:
對包含少數幾個資料量過大的key的那個RDD,通過sample運算元取樣出一份樣本來,然後統計一下每個key的數量,計算出來資料量最大的是哪幾個key。
然後將這幾個key對應的資料從原來的RDD中拆分出來,形成一個單獨的RDD,並給每個key都打上n以內的隨機數作為字首,而不會導致傾斜的大部分key形成另外一個RDD。
接著將需要join的另一個RDD,也過濾出來那幾個傾斜key對應的資料並形成一個單獨的RDD,將每條資料膨脹成n條資料,這n條資料都按順序附加一個0~n的字首,不會導致傾斜的大部分key也形成另外一個RDD。
再將附加了隨機字首的獨立RDD與另一個膨脹n倍的獨立RDD進行join,此時就可以將原先相同的key打散成n份,分散到多個task中去進行join了。
而另外兩個普通的RDD就照常join即可。
程式碼
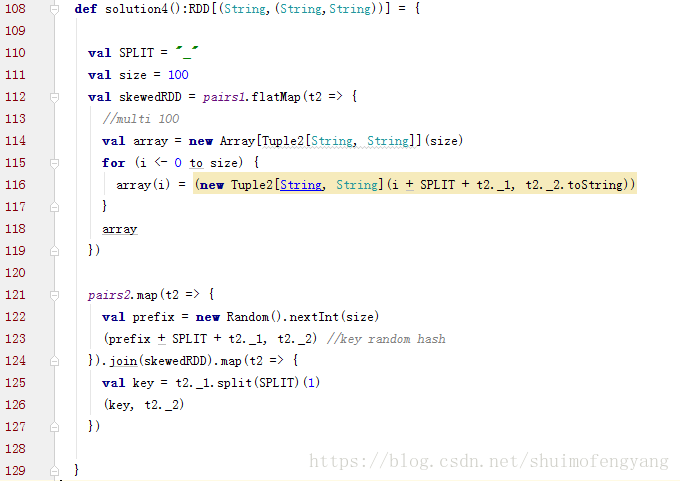
2.3.6 使用隨機字首和擴容RDD進行join(RDD中有大量的key導致資料傾斜)
方案實現思路:
將含有較多傾斜key的RDD擴大多倍,與相對分佈均勻的RDD配一個隨機數。
3.1 去重:
def distinct()
def distinct(numPartitions: Int)
3.2 聚合
def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)]
def reduceByKey(partitioner: Partitioner, func: (V, V) => V): RDD[(K, V)]
def groupBy[K](f: T => K, p: Partitioner):RDD[(K, Iterable[V])]
def groupByKey(partitioner: Partitioner):RDD[(K, Iterable[V])]
def aggregateByKey[U: ClassTag](zeroValue: U, partitioner: Partitioner): RDD[(K, U)]
def aggregateByKey[U: ClassTag](zeroValue: U, numPartitions: Int): RDD[(K, U)]
def combineByKey[C](createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C): RDD[(K, C)]
def combineByKey[C](createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C, numPartitions: Int): RDD[(K, C)]
def combineByKey[C](createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C, partitioner: Partitioner, mapSideCombine: Boolean = true, serializer: Serializer = null): RDD[(K, C)]
3.3 排序
def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length): RDD[(K, V)]
def sortBy[K](f: (T) => K, ascending: Boolean = true, numPartitions: Int = this.partitions.length)(implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T]
3.4 重分割槽
def coalesce(numPartitions: Int, shuffle: Boolean = false, partitionCoalescer: Option[PartitionCoalescer] = Option.empty)
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null)
3.5集合或者表操作
def intersection(other: RDD[T]): RDD[T]
def intersection(other: RDD[T], partitioner: Partitioner)(implicit ord: Ordering[T] = null): RDD[T]
def intersection(other: RDD[T], numPartitions: Int): RDD[T]
def subtract(other: RDD[T], numPartitions: Int): RDD[T]
def subtract(other: RDD[T], p: Partitioner)(implicit ord: Ordering[T] = null): RDD[T]
def subtractByKey[W: ClassTag](other: RDD[(K, W)]): RDD[(K, V)]
def subtractByKey[W: ClassTag](other: RDD[(K, W)], numPartitions: Int): RDD[(K, V)]
def subtractByKey[W: ClassTag](other: RDD[(K, W)], p: Partitioner): RDD[(K, V)]
def join[W](other: RDD[(K, W)], partitioner: Partitioner): RDD[(K, (V, W))]
def join[W](other: RDD[(K, W)]): RDD[(K, (V, W))]
def join[W](other: RDD[(K, W)], numPartitions: Int): RDD[(K, (V, W))]
def leftOuterJoin[W](other: RDD[(K, W)]): RDD[(K, (V, Option[W]))]


4 spark shuffle引數調優
spark.shuffle.file.buffer
預設值:32k
引數說明:該引數用於設定shuffle write task的BufferedOutputStream的buffer緩衝大小。將資料寫到磁碟檔案之前,會先寫入buffer緩衝中,待緩衝寫滿之後,才會溢寫到磁碟。
調優建議:如果作業可用的記憶體資源較為充足的話,可以適當增加這個引數的大小(比如64k),從而減少shuffle write過程中溢寫磁碟檔案的次數,也就可以減少磁碟IO次數,進而提升效能。在實踐中發現,合理調節該引數,效能會有1%~5%的提升。
spark.reducer.maxSizeInFlight
預設值:48m
引數說明:該引數用於設定shuffle read task的buffer緩衝大小,而這個buffer緩衝決定了每次能夠拉取多少資料。
調優建議:如果作業可用的記憶體資源較為充足的話,可以適當增加這個引數的大小(比如96m),從而減少拉取資料的次數,也就可以減少網路傳輸的次數,進而提升效能。在實踐中發現,合理調節該引數,效能會有1%~5%的提升。
spark.shuffle.io.maxRetries
預設值:3
引數說明:shuffle read task從shuffle write task所在節點拉取屬於自己的資料時,如果因為網路異常導致拉取失敗,是會自動進行重試的。該引數就代表了可以重試的最大次數。如果在指定次數之內拉取還是沒有成功,就可能會導致作業執行失敗。
調優建議:對於那些包含了特別耗時的shuffle操作的作業,建議增加重試最大次數(比如60次),以避免由於JVM的full gc或者網路不穩定等因素導致的資料拉取失敗。在實踐中發現,對於針對超大資料量(數十億~上百億)的shuffle過程,調節該引數可以大幅度提升穩定性。
spark.shuffle.io.retryWait
預設值:5s
引數說明:具體解釋同上,該引數代表了每次重試拉取資料的等待間隔,預設是5s。
調優建議:建議加大間隔時長(比如60s),以增加shuffle操作的穩定性。
spark.shuffle.memoryFraction
預設值:0.2
引數說明:該引數代表了Executor記憶體中,分配給shuffle read task進行聚合操作的記憶體比例,預設是20%。
調優建議:在資源引數調優中講解過這個引數。如果記憶體充足,而且很少使用持久化操作,建議調高這個比例,給shuffle read的聚合操作更多記憶體,以避免由於記憶體不足導致聚合過程中頻繁讀寫磁碟。在實踐中發現,合理調節該引數可以將效能提升10%左右。
spark.shuffle.manager
預設值:sort
引數說明:該引數用於設定ShuffleManager的型別。Spark 1.5以後,有三個可選項:hash、sort和tungsten-sort。HashShuffleManager是Spark 1.2以前的預設選項,但是Spark 1.2以及之後的版本預設都是SortShuffleManager了。tungsten-sort與sort類似,但是使用了tungsten計劃中的堆外記憶體管理機制,記憶體使用效率更高。
調優建議:由於SortShuffleManager預設會對資料進行排序,因此如果你的業務邏輯中需要該排序機制的話,則使用預設的SortShuffleManager就可以;而如果你的業務邏輯不需要對資料進行排序,那麼建議參考後面的幾個引數調優,通過bypass機制或優化的HashShuffleManager來避免排序操作,同時提供較好的磁碟讀寫效能。這裡要注意的是,tungsten-sort要慎用,因為之前發現了一些相應的bug。
spark.shuffle.sort.bypassMergeThreshold
預設值:200
引數說明:當ShuffleManager為SortShuffleManager時,如果shuffle read task的數量小於這個閾值(預設是200),則shuffle write過程中不會進行排序操作,而是直接按照未經優化的HashShuffleManager的方式去寫資料,但是最後會將每個task產生的所有臨時磁碟檔案都合併成一個檔案,並會建立單獨的索引檔案。
調優建議:當你使用SortShuffleManager時,如果的確不需要排序操作,那麼建議將這個引數調大一些,大於shuffle read task的數量。那麼此時就會自動啟用bypass機制,map-side就不會進行排序了,減少了排序的效能開銷。但是這種方式下,依然會產生大量的磁碟檔案,因此shuffle write效能有待提高。
spark.shuffle.consolidateFiles
預設值:false
引數說明:如果使用HashShuffleManager,該引數有效。如果設定為true,那麼就會開啟consolidate機制,會大幅度合併shuffle write的輸出檔案,對於shuffle read task數量特別多的情況下,這種方法可以極大地減少磁碟IO開銷,提升效能。
調優建議:如果的確不需要SortShuffleManager的排序機制,那麼除了使用bypass機制,還可以嘗試將spark.shffle.manager引數手動指定為hash,使用HashShuffleManager,同時開啟consolidate機制。在實踐中嘗試過,發現其效能比開啟了bypass機制的SortShuffleManager要高出10%~30%。
連結:https://zhuanlan.zhihu.com/p/22024169
https://www.cnblogs.com/arachis/p/Spark_Shuffle.html