
資料科學家成長指南(中)
在《 資料科學家成長指南(上) 》中已經介紹了基礎原理、統計學、程式設計能力和機器學習的要點大綱,今天更新後續的第五、六、七條線路:自然語言處理、資料視覺化、大資料。
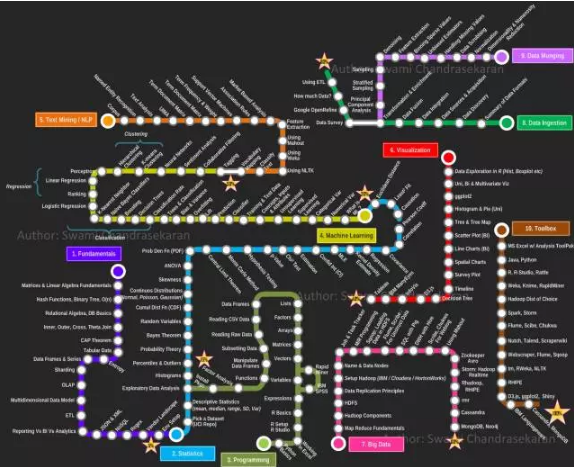
準備好在新的一年,學習成為未來五年最性感的職位麼。
——————
Text Mining / NLP
文字挖掘,自然語言處理。這是一個橫跨人類學、語言學的交叉領域。中文的自然語言處理更有難度,這是漢語語法特性決定的,英文是一詞單詞為最小元素,有空格區分,中文則是字,且是連續的。這就需要中文在分詞的基礎上再進行自然語言處理。中文分詞質量決定了後續好壞。
Corpus
語料庫
它指大規模的電子文字庫,它是自然語言的基礎。語料庫沒有固定的型別,文獻、小說、新聞都可以是語料,主要取決於目的。語料庫應該考慮多個文體間的平衡,即新聞應該包含各題材新聞。
語料庫是需要加工的,不是隨便網上下載個txt就是語料庫,它必須處理,包含語言學標註,詞性標註、命名實體、句法結構等。英文語料庫比較成熟,中文語料還在發展中。
NLTK-Data
自然語言工具包
NLTK創立於2001年,通過不斷髮展,已經成為最好的英語語言工具包之一。內含多個重要模組和豐富的語料庫,比如nltk.corpus 和 nltk.utilities。Python的NLTK和R的TM是主流的英文工具包,它們也能用於中文,必須先分詞。中文也有不少處理包:TextRank、Jieba、HanLP、FudanNLP、NLPIR等。
Named Entity Recognition
命名實體識別
它是確切的名詞短語,如組織、人、時間,地區等等。命名實體識別則是識別所有文字中的命名實體,是自然語言處理領域的重要基礎工具。
命名實體有兩個需要完成的步驟,一是確定命名實體的邊界,二是確定型別。漢字的實體識別比較困難,比如南京市長江大橋,會產生南京 | 市長 | 江大橋 、南京市 | 長江大橋 兩種結果,這就是分詞的任務。確定型別則是明確這個實體是地區、時間、或者其他。可以理解成文字版的資料型別。
命名實體主要有兩類方法,基於規則和詞典的方法,以及基於機器學習的方法。規則主要以詞典正確切分出實體,機器學習主要以隱馬爾可夫模型、最大熵模型和條件隨機域為主。
Text Analysis
文字分析
這是一個比較大的交叉領域。以語言學研究的角度看,文字分析包括語法分析和語義分析,後者現階段進展比較緩慢。語法分析以正確構建出動詞、名詞、介詞等組成的語法樹為主要目的。
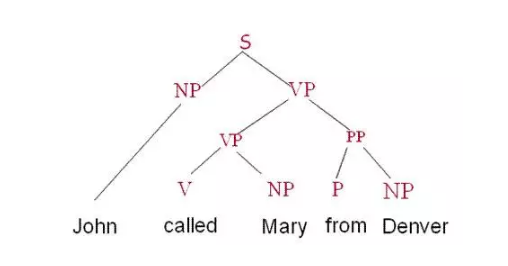
如果不深入研究領域、則有文字相似度、預測單詞、困惑值等分析,這是比較成熟的應用。
UIMA
UIMA 是一個用於分析非結構化內容(比如文字、視訊和音訊)的元件架構和軟體框架實現。這個框架的目的是為非結構化分析提供一個通用的平臺,從而提供能夠減少重複開發的可重用分析元件。
Term Document Matrix
詞-文件矩陣
它是一個二維矩陣,行是詞,列是文件,它記錄的是所以單詞在所有文件中出現頻率。所以它是一個高維且稀疏的矩陣。
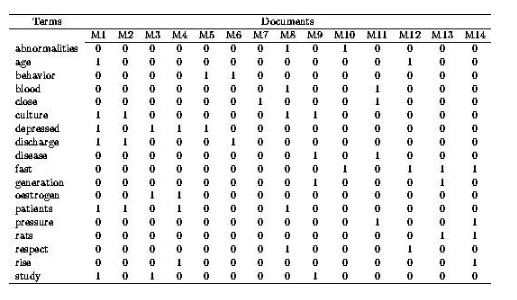
這個矩陣是TF-IDF(term frequency–inverse document frequency)演算法的基礎。TF指代的詞在文件中出現的頻率,描述的是詞語在該文件的重要數,IDF是逆向檔案頻率,描述的是單詞在所有文件中的重要數。我們認為,在所有文件中都出現的詞肯定是的、你好、是不是這類常用詞,重要性不高,而越稀少的詞越重要。故由總文件數除以包含該詞的文件數,然後取對數獲得。
詞-文件矩陣可以用矩陣的方法快速計算TF-IDF。
它的變種形式是Document Term Matrix,行列顛倒。
Term Frequency & Weight
詞頻和權重
詞頻即詞語在文件中出現的次數,這裡的文件可以認為是一篇新聞、一份文字,甚至是一段對話。詞頻表示了詞語的重要程度,一般這個詞出現的越多,我們可以認為它越重要,但也有可能遇到很多無用詞,比如的、地、得等。這些是停用詞,應該刪除。另外一部分是日常用語,你好,謝謝,對文字分析沒有幫助,為了區分出它們,我們再加入權重。
權重代表了詞語的重要程度,像你好、謝謝這種,我們認為它的權重是很低,幾乎沒有任何價值。權重既能人工打分,也能通過計算獲得。通常,專業類詞彙我們會給予更高的權重,常用詞則低權重。
通過詞頻和權重,我們能提取出代表這份文字的特徵詞,經典演算法為TF-IDF。
Support Vector Machines
支援向量機
它是一種二類分類模型,有別於感知機,它是求間隔最大的線性分類。當使用核函式時,它也可以作為非線性分類器。
它可以細分為線性可分支援向量機、線性支援向量機,非線性支援向量機。
非線性問題不太好求解,圖左就是將非線性的特徵空間對映到新空間,將其轉換成線性分類。說的通俗點,就是利用核函式將左圖特徵空間(歐式或離散集合)的超曲面轉換成右圖特徵空間(希爾伯特空間)中的的超平面。
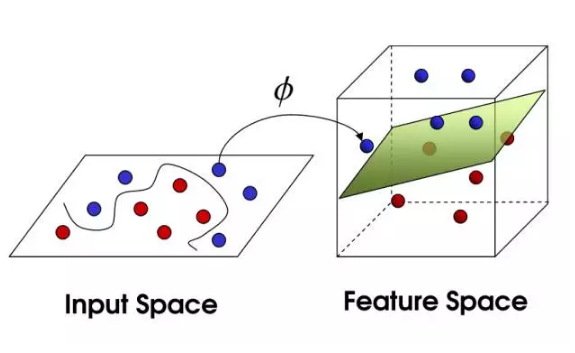
常用核函式有多項式核函式,高斯核函式,字串核函式。
字串核函式用於文字分類、資訊檢索等,SVM在高維的文字分類中表現較好,這也是出現在自然語言處理路徑上的原因。
Association Rules
關聯規則
它用來挖掘資料背後存在的資訊,最知名的例子就是啤酒與尿布了,雖然它是虛構的。但我們可以理解它蘊含的意思:買了尿布的人更有可能購買啤酒。
它是形如X→Y的蘊涵式,是一種單向的規則,即買了尿布的人更有可能購買啤酒,但是買了啤酒的人未必會買尿布。我們在規則中引入了支援度和置信度來解釋這種單向。支援度表明這條規則的在整體中發生的可能性大小,如果買尿布啤酒的人少,那麼支援度就小。置信度表示從X推導Y的可信度大小,即是否真的買了尿布的人會買啤酒。
關聯規則的核心就是找出頻繁專案集,Apriori演算法就是其中的典型。頻繁專案集是通過遍歷迭代求解的,時間複雜度很高,大型資料集的表現不好。
關聯規則和協同過濾一樣,都是相似性的求解,區分是協同過濾找的是相似的人,將人劃分群體做個性化推薦,而關聯規則沒有過濾的概念,是針對整體的,與個人偏好無關,計算出的結果是針對所有人。
Market Based Analysis
購物籃分析,實際是Market Basket Analysis,作者筆誤。
傳統零售業中,購物籃指的是消費者一次性購買的商品,收營條上的單子資料都會被記錄下來以供分析。更優秀的購物籃分析,還會用紅外射頻記錄商品的擺放,顧客在超市的移動,人流量等資料。
關聯規則是購物籃分析的主要應用,但還包括促銷打折對銷售量的影響、會員制度積分制度的分析、回頭客和新客的分析。
Feature Extraction
特徵提取
它是特徵工程的重要概念。資料和特徵決定了機器學習的上限,而模型和演算法只是逼近這個上限而已。而很多模型都會遇到維數災難,即維度太多,這對效能瓶頸造成了考驗。常見文字、影象、聲音這些領域。
為了解決這一問題,我們需要進行特徵提取,將原始特徵轉換成最有重要性的特徵。像指紋識別、筆跡識別,這些都是有實體有跡可循的,而表情識別等則是比較抽象的概念。這也是特徵提取的挑戰。
不同模式下的特徵提取方法不一樣,文字的特徵提取有TF-IDF、資訊增益等,線性特徵提取包括PCA、LDA,非線性特徵提取包括核Kernel。
Using Mahout
使用Mahout
Mahout是Hadoop中的機器學習分散式框架,中文名驅象人。
Mahout包含了三個主題:推薦系統、聚類和分類。分別對應不同的場景。
Mahout在Hadoop平臺上,藉助MR計算框架,可以簡便化的處理不少資料探勘任務。實際Mahout已經不再維護新的MR,還是投向了Spark,與Mlib互為補充。
Using Weka
Weka是一款免費的,基於JAVA環境下開源的機器學習以及資料探勘軟體。
Using NLTK
使用自然語言工具包
Classify Text
文字分類
將文字集進行分類,與其他分類演算法沒有本質區別。假如現在要將商品的評論進行正負情感分類,首先分詞後要將文字特徵化,因為文字必然是高維,我們不可能選擇所有的詞語作為特徵,而是應該以最能代表該文字的詞作為特徵,例如只在正情感中出現的詞:特別棒,很好,完美。計算出卡方檢驗值或資訊增益值,用排名靠前的單詞作為特徵。
所以評論的文字特徵就是[word11,word12,……],[word21,word22,……],轉換成高維的稀疏矩陣,之後則是選取最適合的演算法了。
垃圾郵件、反黃鑑別、文章分類等都屬於這個應用。
Vocabulary Mapping
詞彙對映
NLP有一個重要的概念,本體和實體,本體是一個類,實體是一個例項。比如手機就是本體、iPhone和小米是實體,它們共同構成了知識庫。很多文字是一詞多意或者多詞一意,比如蘋果既可以是手機也可以是水果,iPhone則同時有水果機、蘋果機、iPhone34567的諸多叫法。計算機是無法理解這麼複雜的含義。詞彙對映就是將幾個概念相近的詞彙統一成一個,讓計算機和人的認知沒有區別。
——————
Visualization資料視覺化
這是難度較低的環節,統計學或者大資料,都是不斷髮展演變,是屬於終身學習的知識,而視覺化只要瞭解掌握,可以受用很多年。這裡並不包括視覺化的程式設計環節。
Uni, Bi & Multivariate Viz
單/雙/多 變數
在資料視覺化中,我們通過不同的變數/維度組合,可以作出不同的視覺化成果。單變數、雙變數和多變數有不同作圖方式。
ggplot2
R語言的一個經典視覺化包
ggoplot2的核心邏輯是按圖層作圖,每一個語句都代表了一個圖層。以此將各繪圖元素分離。
ggplot(...) +
geom(...) +
stat(...) +
annotate(...) +
scale(...)
上圖就是典型的ggplot2函式風格。plot是整體圖表,geom是繪圖函式,stat是統計函式,annotate是註釋函式,scale是標尺函式。ggplot的繪圖風格是灰底白格。
ggplot2的缺點是繪圖比較緩慢,畢竟是以圖層的方式,但是瑕不掩瑜,它依舊是很多人使用R的理由。
Histogram & Pie(Uni)
直方圖和餅圖(單變數)
直方圖已經介紹過了,這裡就放張圖。
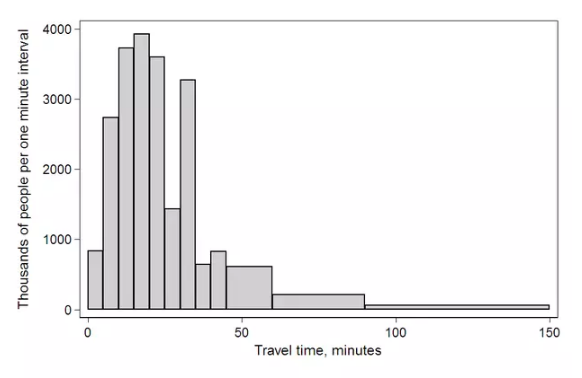
餅圖不是常用的圖形,若變數之間的差別不大,如35%和40%,在餅圖的面積比例靠肉眼是分辨不出來。
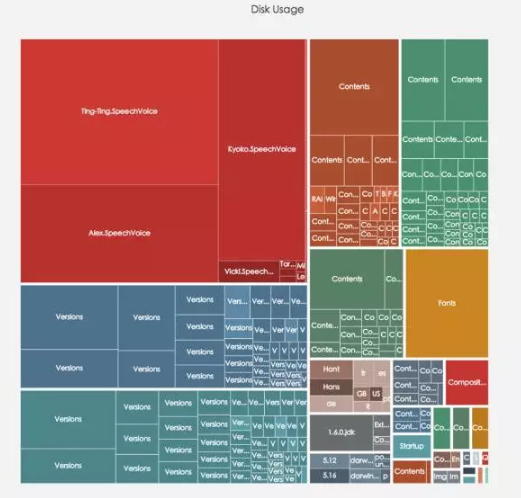
Tree & Tree Map
樹圖和矩形樹圖
樹圖代表的是一種結構。層次聚類的例項圖就屬於樹圖。
當維度的變數多大,又需要對比時,可以使用矩形樹圖。通過面積表示變數的大小,顏色表示類目。
Scatter Plot (Bi)
散點圖(雙變數)
散點圖在資料探索中經常用到,用以分析兩個變數之間的關係,也可以用於迴歸、分類的探索。
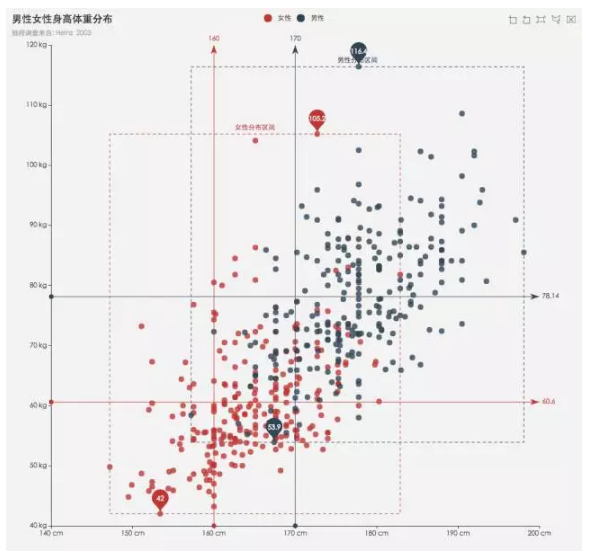
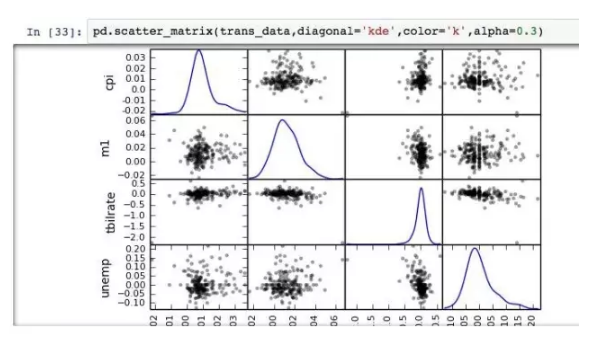
利用散點圖矩陣,則能將雙變數拓展為多變數。
Line Charts (Bi)
折線圖(雙變數)
它常用於描繪趨勢和變化,和時間維度是好基友,如影隨形。
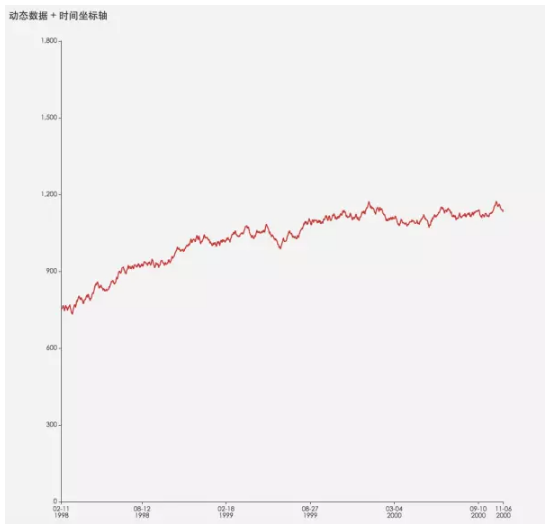
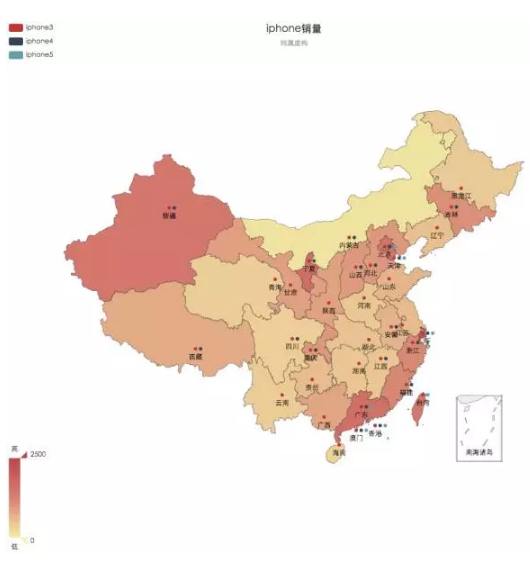
Spatial Charts
空間圖,應該就是地圖的意思
一切涉及到空間屬性的資料都能使用地理圖。地理圖需要表示座標的資料,可以是經緯度、也可以是地理實體,比如上海市北京市。經緯度的資料,常常和POI掛鉤。
Survey Plot
不知道具體的含義,粗略翻譯圖形探索
plot是R中最常用的函式,通過plot(x,y),我們可以設定不同的引數,決定使用那種圖形。
Timeline
時間軸
當資料涉及到時間,或者存在先後順序,我們可以使用時間軸。不少視覺化框架,也支援以時間播放的形式描述資料的變化。

Decision Tree
決策樹
這裡的決策樹不是演算法,而是基於解釋性好的一個應用。
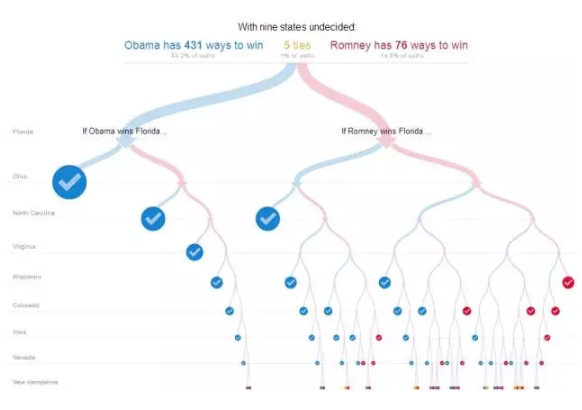
當資料遇到是否,或者選擇的邏輯判斷時,決策樹不失為一種視覺化思路。
D3.js
知名的資料視覺化前端框架
d3可以製作複雜的圖形,像直方圖散點圖這類,用其他框架完成比較好,學習成本比前者低。
d3是基於svg的,當資料量變大運算複雜後,d3效能會變差。而canvas的效能會好不少,國內的echarts基於後者。有中文文件,屬於比較友好的框架。
R語言中有一個叫d3NetWork的包,Python則有d3py的包,當然直接搭建環境也行。
IBM ManyEyes
Many Eyes是IBM公司的一款線上視覺化處理工具。該工具可以對數字,文字等進行視覺化處理。應該是免費的。圖網上隨便找的。
Tableau
國外知名的商用BI,分為Desktop和Server,前者是資料分析單機版,後者支援私有化部署。加起來得幾千美金,挺貴的。圖網上隨便找的。
——————
Big Data 大資料
越來越火爆的技術概念,Hadoop還沒有興起幾年,第二代Spark已經後來居上。 因為作者寫的比較早,現在的新技術沒有過多涉及。部分工具我不熟悉,就略過了。
Map Reduce Fundamentals
MapReduce框架
它是Hadoop核心概念。它通過將計算任務分割成多個處理單元分散到各個伺服器進行。
MapReduce有一個很棒的解釋,如果你要計算一副牌的數量,傳統的處理方法是找一個人數。而MapReduce則是找來一群人,每個人數其中的一部分,最終將結果彙總。分配給每個人數的過程是Map,處理彙總結果的過程是Reduce。
Hadoop Components
Hadoop元件
Hadoo號稱生態,它就是由無陣列建拼接起來的。
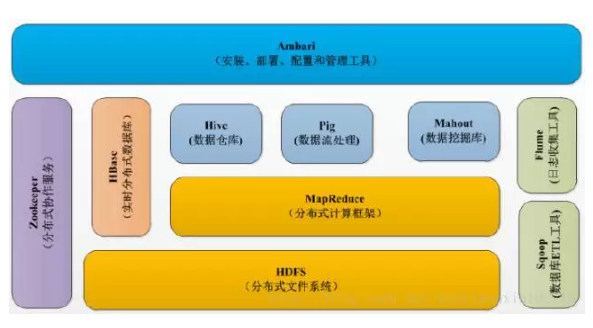
各類元件包括HDFS、MapReduce、Hive、HBase、Zookeeper、Sqoop、Pig、Mahout、Flume等。最核心的就是HDFS和MapReduce了。
HDFS
Hadoop的分散式檔案系統
HDFS的設計思路是一次讀取,多次訪問,屬於流式資料訪問。HDFS的資料塊預設64MB(Hadoop 2.X 變成了128MB),並且以64MB為單位分割,塊的大小遵循摩爾定理。它和MR息息相關,通常來說,Map Task的數量就是塊的數量。64MB的檔案為1個Map,65MB(64MB+1MB)為2個Map。
Data Replication Principles
資料複製原理
資料複製屬於分散式計算的範疇,它並不僅僅侷限於資料庫。
Hadoop和單個數據庫系統的差別在於原子性和一致性。在原子性方面,要求分散式系統的所有操作在所有相關副本上要麼提交, 要麼回滾, 即除了保證原有的區域性事務的原子性,還需要控制全域性事務的原子性; 在一致性方面,多副本之間需要保證單一副本一致性。
Hadoop資料塊將會被複制到多型伺服器上以確保資料不會丟失。
Setup Hadoop (IBM/Cloudera/HortonWorks)
安裝Hadoop
包括社群版、商業發行版、以及各種雲。
Name & Data Nodes
名稱和資料節點
HDFS通訊分為兩部分,Client和NameNode & DataNode。
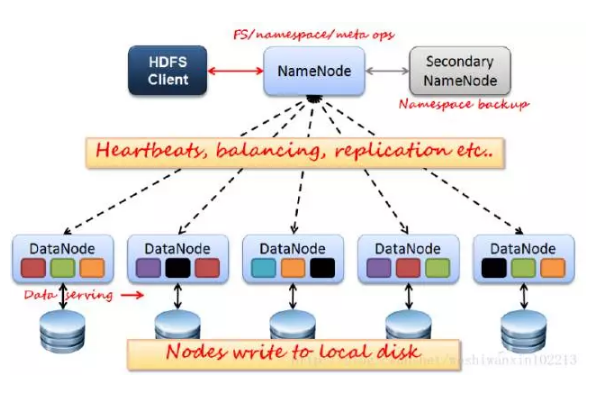
NameNode:管理HDFS的名稱空間和資料塊對映資訊,處理client。NameNode有一個助手叫Secondary NameNode,負責映象備份和日誌合併,負擔工作負載、提高容錯性,誤刪資料的話這裡也能恢復,當然更建議加trash。
DataNode:真正的資料節點,儲存實際的資料。會和NameNode之間維持心跳。
Job & Task Tracker
任務跟蹤
JobTracker負責管理所有作業,講作業分隔成一系列任務,然而講任務指派給TaskTracker。你可以把它想象成經理。
TaskTracker負責執行Map任務和Reduce任務,當接收到JobTracker任務後幹活、執行、之後彙報任務狀態。你可以把它想象成員工。一臺伺服器就是一個員工。
M/R Programming
Map/Reduce程式設計
MR的程式設計依賴JobTracker和TaskTracker。TaskTracker管理著Map和Reduce兩個類。我們可以把它想象成兩個函式。
MapTask引擎會將資料輸入給程式設計師編寫好的Map( )函式,之後輸出資料寫入記憶體/磁碟,ReduceTask引擎將Map( )函式的輸出資料合併排序後作為自己的輸入資料,傳遞給reduce( ),轉換成新的輸出。然後獲得結果。
網路上很多案例都通過統計詞頻解釋MR程式設計:

原始資料集分割後,Map函式對資料集的元素進行操作,生成鍵-值對形式中間結果,這裡就是{“word”,counts},Reduce函式對鍵-值對形式進行計算,得到最終的結果。
Hadoop的核心思想是MapReduce,MapReduce的核心思想是shuffle。shuffle在中間起了什麼作用呢?shuffle的意思是洗牌,在MR框架中,它代表的是把一組無規則的資料儘量轉換成一組具有一定規則的資料。
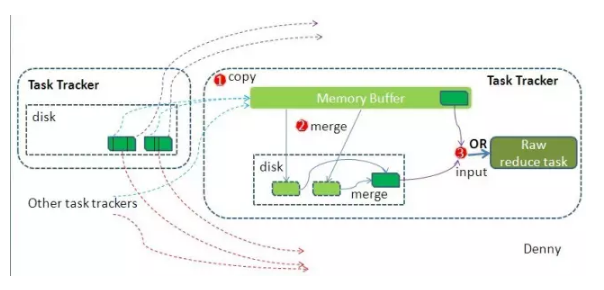
前面說過,map函式會將結果寫入到記憶體,如果叢集的任務有很多,損耗會非常厲害,shuffle就是減少這種損耗的。圖例中我們看到,map輸出了結果,此時放在快取中,如果快取不夠,會寫入到磁碟成為溢寫檔案,為了效能考慮,系統會把多個key合併在一起,類似merge/group,圖例的合併就是{"Bear",[1,1]},{"Car",[1,1,1]},然後求和,等Map任務執行完成,Reduce任務就直接讀取檔案了。
另外,它也是造成資料傾斜的原因,就是某一個key的數量特別多,導致任務計算耗時過長。
Sqoop: Loading Data in HDFS
Sqoop是一個工具,用來將傳統資料庫中的資料匯入到Hadoop中。雖然Hadoop支援各種各樣的資料,但它依舊需要和外部資料進行互動。
Sqoop支援關係型資料庫,MySQL和PostgreSQL經過了優化。如果要連其他資料庫例如NoSQL,需要另外下載聯結器。匯入時需要注意資料一致性。
Sqoop也支援匯出,但是SQL有多種資料型別,例如String對應的CHAR(64)和VARCHAR(200)等,必須確定這個型別可不可以使用。
Flue, Scribe: For Unstruct Data
2種日誌相關的系統,為了處理非結構化資料。
SQL with Pig
利用Pig語言來進行SQL操作。
Pig是一種探索大規模資料集的指令碼語言,Pig是接近指令碼方式去描述MapReduce。它和Hive的區別是,Pig用指令碼語言解釋MR,Hive用SQL解釋MR。
它支援我們對加載出來的資料進行排序、過濾、求和、分組(group by)、關聯(Joining)。並且支援自定義函式(UDF),它比Hive最大的優勢在於靈活和速度。當查詢邏輯非常複雜的時候,Hive的速度會很慢,甚至無法寫出來,那麼Pig就有用武之地了。
DWH with Hive
利用Hive來實現資料倉庫
Hive提供了一種查詢語言,因為傳統資料庫的SQL使用者遷移到Hadoop,讓他們學習底層的MR API是不可能的,所以Hive出現了,幫助SQL使用者們完成查詢任務。
Hive很適合做資料倉庫,它的特性適用於靜態,SQL中的Insert、Update、Del等記錄操作不適用於Hive。
它還有一個缺點,Hive查詢有延時,因為它得啟動MR,這個時間消耗不少。傳統SQL資料庫簡單查詢幾秒內就能完成,Hive可能會花費一分鐘。只有資料集足夠大,那麼啟動耗費的時間就忽略不計。
故Hive適用的場景是每天凌晨跑當天資料等等。它是類SQL語言,資料分析師能直接用,產品經理能直接用,拎出一個大學生培訓幾天也能用。效率快。
可以將Hive作通用查詢,而用Pig定製UDF,做各種複雜分析。Hive和MySQL語法最接近。
Scribe, Chukwa For Weblog
Scribe是Facebook開源的日誌收集系統,在Facebook內部已經得到的應用。
Chukwa是一個開源的用於監控大型分散式系統的資料收集系統。
Using Mahout
已經介紹過了
Zookeeper Avro
Zookeeper,是Hadoop的一個重要元件,它被設計用來做協調服務的。主要是用來解決分散式應用中經常遇到的一些資料管理問題,如:統一命名服務、狀態同步服務、叢集管理、分散式應用配置項的管理等。
Avro是Hadoop中的一個子專案,它是一個基於二進位制資料傳輸高效能的中介軟體。除外還有Kryo、protobuf等。
Storm: Hadoop Realtime
Storm是最新的一個開源框架
目的是大資料流的實時處理。它的特點是流,Hadoop的資料查詢,優化的再好,也要基於HDFS進行MR查詢,有沒有更快的方法呢?是有的。就是在資料產生時就去監控日誌,然後馬上進行計算。比如頁面訪問,有人點選一下,我計算就+1,再有人點,+1。那麼這個頁面的UV我也就能實時知道了。
Hadoop擅長批處理,而Storm則是流式處理,吞吐肯定是Hadoop優,而時延肯定是Storm好。
Rhadoop, RHipe
將R和hadoop結合起來2種架構。
RHadoop包含三個包(rmr,rhdfs,rhbase),分別對應MapReduce,HDFS,HBase三個部分。
Spark還有個叫SparkR的。
rmr
RHadoop的一個包,和hadoop的MapReduce相關。
另外Hadoop的刪除命令也叫rmr,不知道作者是不是指代的這個……
Classandra
一種流行的NoSql資料庫
我們常常說Cassandra是一個面向列(Column-Oriented)的資料庫,其實這不完全對——資料是以鬆散結構的多維雜湊表儲存在資料庫中;所謂鬆散結構,是指每行資料可以有不同的列結構,而在關係型資料中,同一張表的所有行必須有相同的列。在Cassandra中可以使用一個唯一識別號訪問行,所以我們可以更好理解為,Cassandra是一個帶索引的,面向行的儲存。
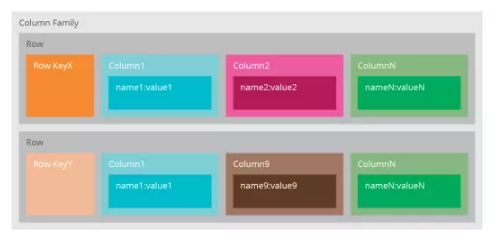
Cassandra只需要你定義一個邏輯上的容器(Keyspaces)裝載列族(Column Families)。
Cassandra適合快速開發、靈活部署及拓展、支援高IO。它和HBase互為競爭對手,Cassandra+Spark vs HBase+Hadoop,Cassandra強調AP ,Hbase強調CP。
MongoDB, Neo4j
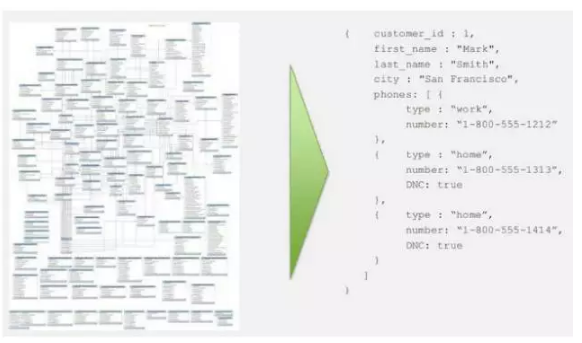
MongoDB是文件型NoSQL資料庫。
MongoDB如果不涉及Join,會非常靈活和優勢。舉一個我們最常見的電子商務網站作例子,不同的產品類目,產品規範、說明和介紹都不一樣,電子產品尿布零食手機卡等等,在關係型資料庫中設計表結構是災難,但是在MongoDB中就能自定義拓展。
再放一張和關係型資料庫對比的哲學圖吧:
Neo4j是最流行的圖形資料庫。
圖形資料庫如其名字,允許資料以節點的形式,應用圖形理論儲存實體之間的關係資訊。
最常見的場景是社交關係鏈、凡是業務邏輯和關係帶點邊的都能用圖形資料庫。
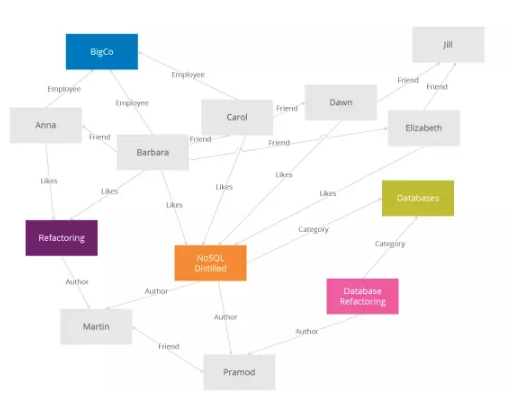
跟關係資料庫相比,圖形資料庫最主要的優點是解決了圖計算(業務邏輯)在關係資料庫上大量的join操作,比如讓你查詢:你媽媽的姐姐的舅舅的女兒的妹妹是誰?這得寫幾個Join啊。但凡關係,join操作的代價是巨大的,而GraphDB能很快地給出結果。
——————
個人水平一般,內容解讀不算好,可能部分內容有錯誤,歡迎指正。
本文寫的是文字挖掘、資料視覺化和大資料。後續還只有一篇了。