FastText詞向量表示
論文《Enriching Word Vectors with Subword Information》
介紹
FastText的作者也就是word2vec的作者,所以兩者是一脈相承的。
目前的詞向量模型都是把每一個單詞作為單獨的向量,並沒有考慮詞語的內部結構,那麼FastText相比於word2vec的創新就是考慮了詞語的形態構成,也就是加上了sub-word的資訊,這樣的好處在於對於詞彙量很大的語言,通常有很多未登入詞的這種,也可以通過sub-word去構成word進行詞向量表示。
模型
關於模型就不細講了,就是一個skipgram model with negative,和word2vec一樣的,公式如下:

C_t表示上下文範圍內的單詞,N_t,c表示負樣本,其中l表示:
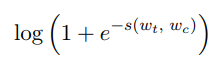
s表示score function,這裡用:
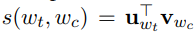
subword model
整篇文章最主要的創新點就在於這個subword model,對於每一個單詞w,拆分成字元n-gram進行表示,並且加入了尖括號<>在單詞外面,因為這樣可以區分字首和字尾,比如一個單詞where如果用3-gram來表示,那麼可以表示為:
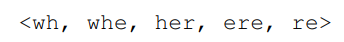
以及:
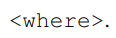
那麼在模型訓練的時候計算scoring function的時候,當前單詞的詞向量就用n-gram的向量的和:
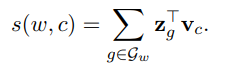
其中z_g表示n-gram的向量。
結果
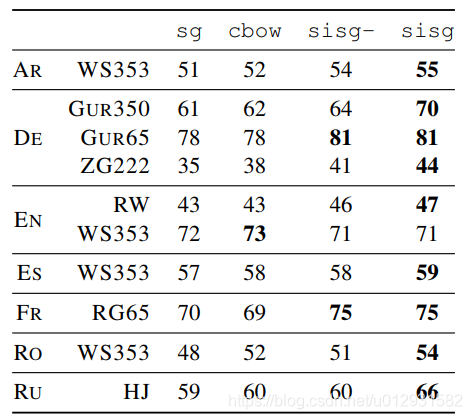
用人工標記的單詞相似度來衡量幾個模型的效果。作為baseline的模型是skipgrim和cbow,由於FastText相對於baseline的一大優勢在於可以輸出未登入詞的詞向量,所以增加了一個比對的模型,sisg-,這個模型也是FastText,只不過將所有未登入詞輸出變為NULL,這樣可以比對在失去對未登入詞的適應性這個優勢的時候,FastText效果如何,從下表可以看出,即使將未登入詞輸出都變為NULL,結果也依然不弱於兩個baseline,如果是正常的FastText,sisg優勢就更加明顯了。