
CS224n | 詞向量表示word2vec
1



一是沒有相似性 二是太大
我們可以探索一種直接的方法 一個單詞編碼的含義是你可以直接閱讀的
我們要做的構建這樣的向量,然後做一種類似求解點積的操作。這樣我們就可以瞭解詞彙之間有多少相似性

分佈相似性是指 你可以得到大量表示某個詞彙含義的值,只需要通過觀察其出現的上下文,並對這些上下文做一些處理得到。
比如圖中banking的含義,需要做的就是找到數千個包含banking的例句,然後觀察每一次它出現的場合。我們看到法規 歐洲 ……然後我們開始統計這些資訊,通過某種方式用這些上下文中的詞來表示banking的含義

distributional vs distributional representations(即用密集型向量表示詞彙的含義) distributional representations:通常是分散式相似性的概念是一個關於詞彙語義的理論, 我希望你們理解到 可以通過理解單詞出現的上下文來描繪詞彙的意思,所以這個分散式跟之前提到的分散式指的不是一回事
Problems with this discrete(離散) representation 分散式是跟獨熱詞彙向量不同,獨熱詞彙向量是一種儲存在某處的本地表示 這裡分佈 我們在一個大的向量空間中模糊化詞彙的含義
2 word2vec

wt是中心詞彙,w-t是除它外所有其他的上下文


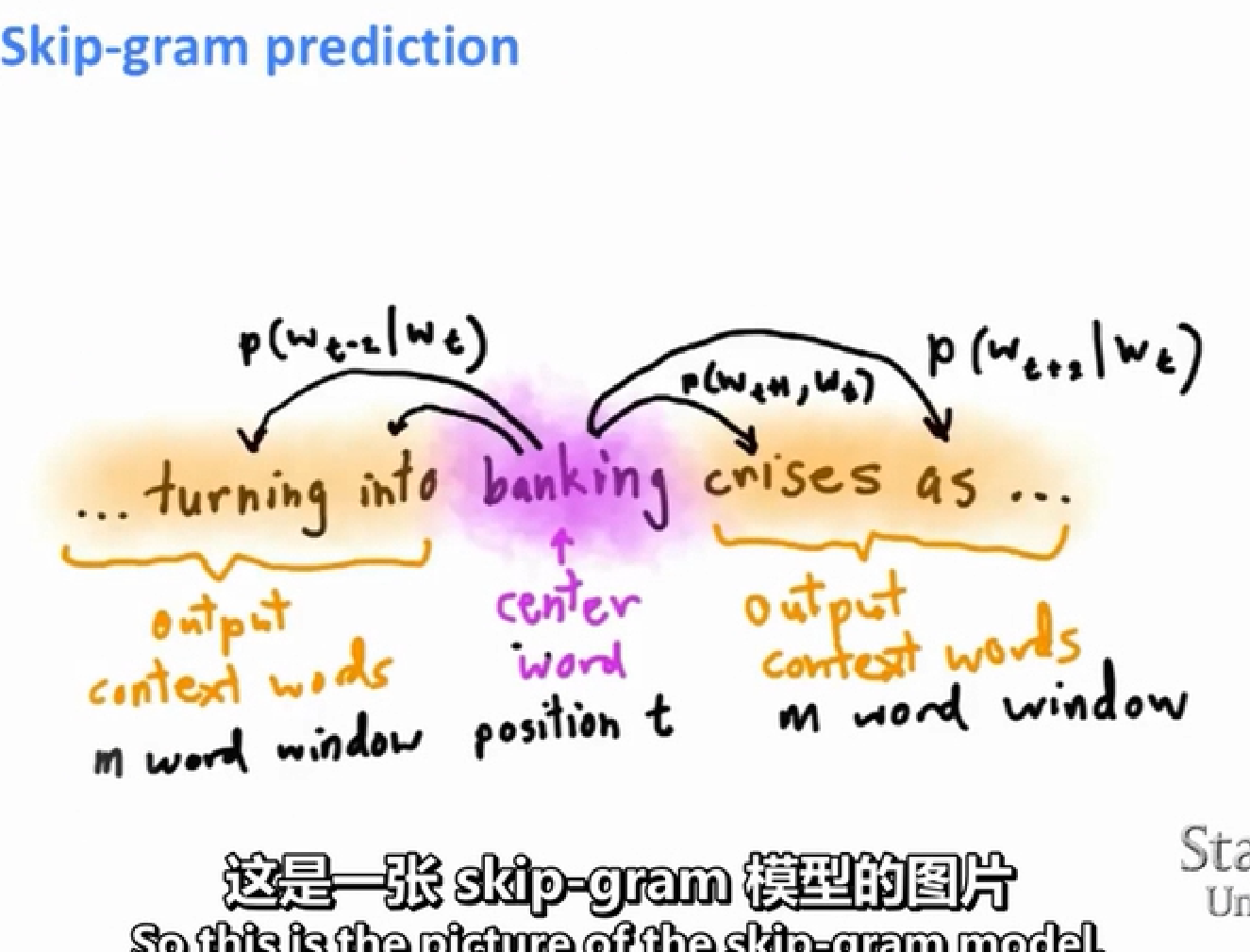





softmax是一種將數值轉換成概率的標準方法
當計算點積時,他們僅僅是數值 是實數,我們不能直接把它轉換為概率分佈
最簡單的做法就是把他們轉換為指數,因為只要你求一個數的指數,其結果一定落在一個正區間,那結果一定為正
這就為求解概率分佈提供了一個很好的接觸
如果你大量資料都為正,而你想將它們等比例轉換為概率分佈,那就很簡單了
你只需要對它們求和,然後用將各項依次除以總和,那麼馬上就得到它們的概率分佈了;接下來就是要對這個概率進行所謂的歸一化處理

所以每個單詞會有兩個向量
之所以叫softmax因為 如果你取指數時,就接近於一個最大值函式
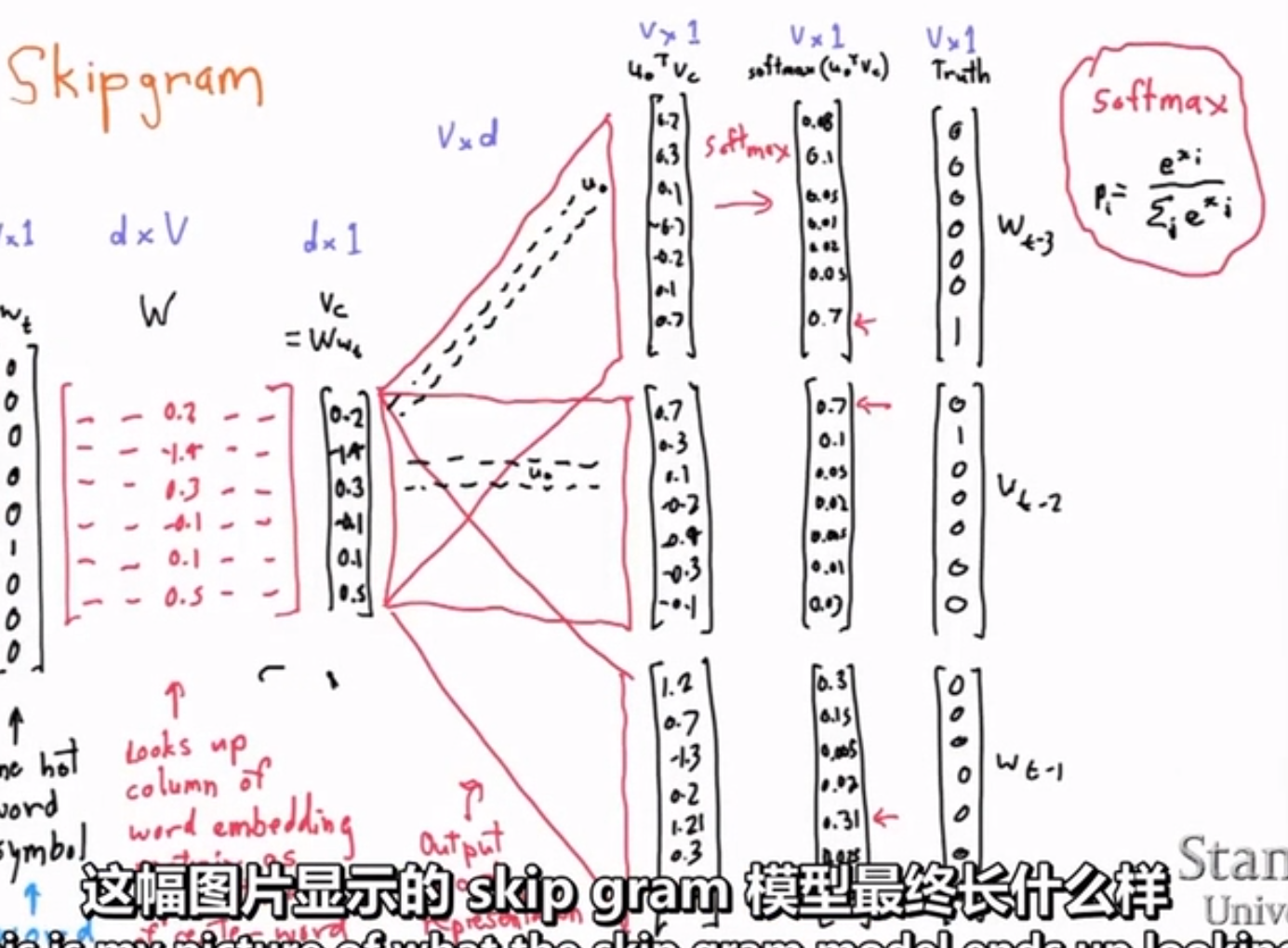
結果是構造了兩個矩陣,矩陣1獲得了中心詞的表示,矩陣2就是上下文的詞彙表示(求出了中心詞彙和上下文表示的點積)
