
paddle詞向量的表示







Word2vec演算法

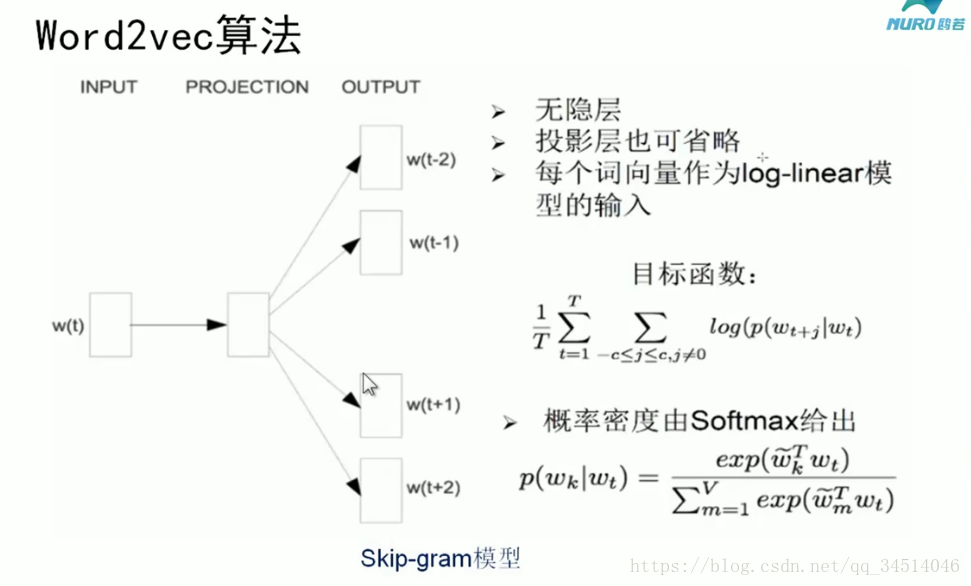
詞頻出現的越多,越接近根節點
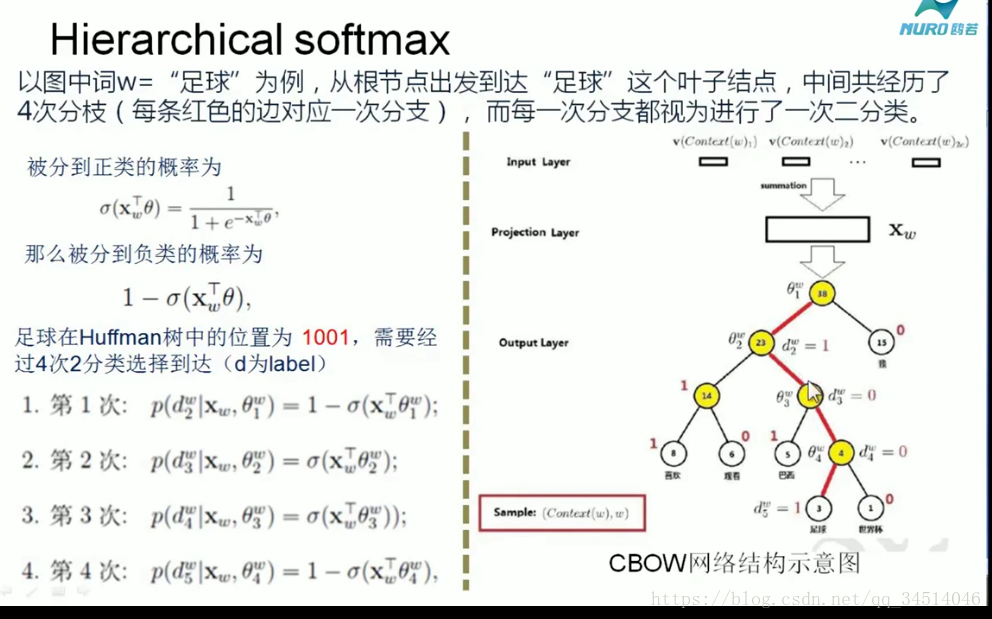
引數更新不僅要更新0,還要更新輸入X

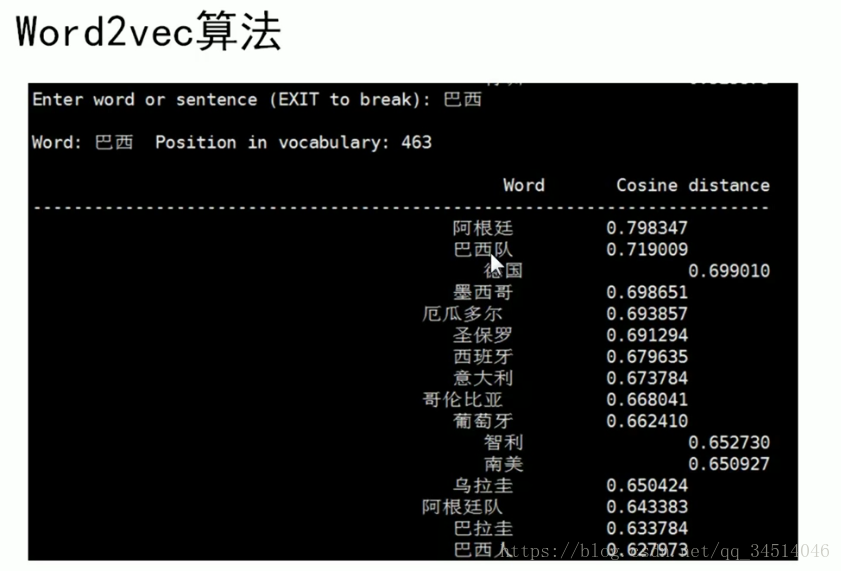
word2vec



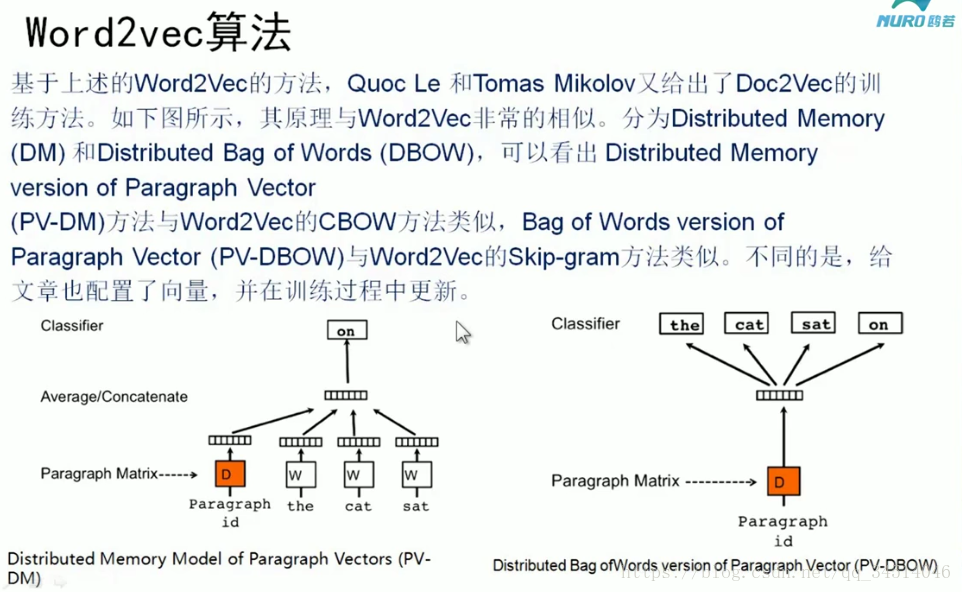
DOC2Vec
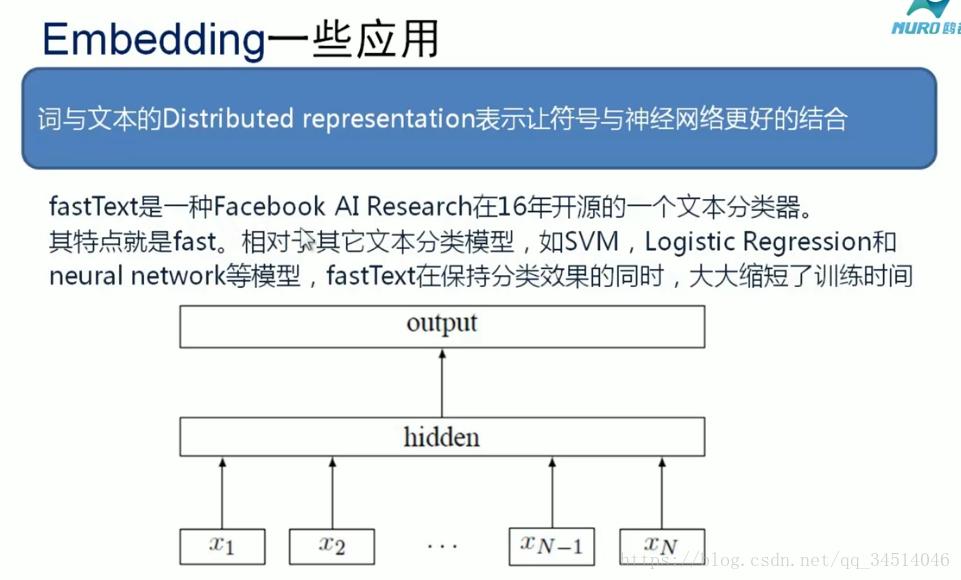
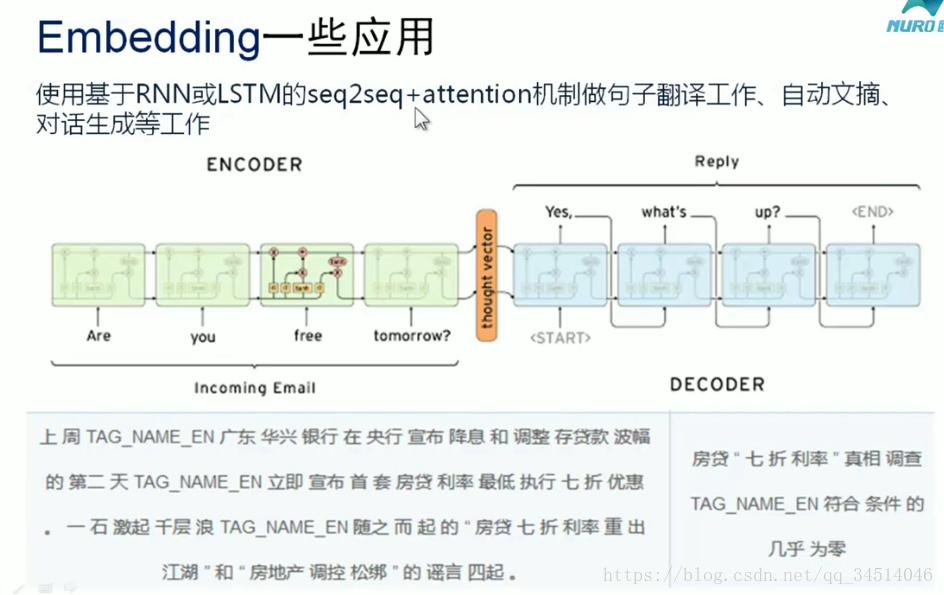
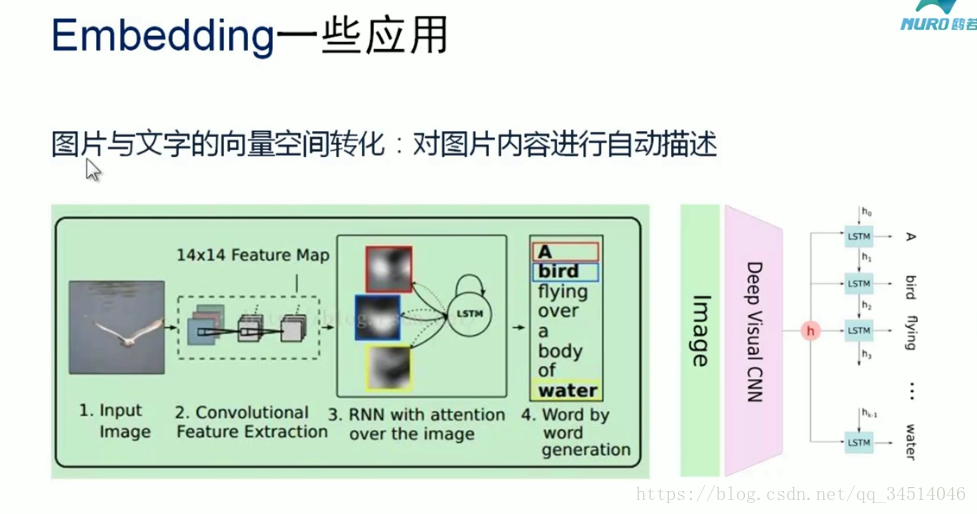
相關推薦
paddle詞向量的表示
Word2vec演算法 詞頻出現的越多,越接近根節點 引數更新不僅要更新0,還要更新輸入X word2vec DOC2Vec &n
word2vec 和 doc2vec 詞向量表示
ron 中心 con 線性 如果 存在 但是 標簽 word Word2Vec 詞向量的稠密表達形式(無標簽語料庫訓練) Word2vec中要到兩個重要的模型,CBOW連續詞袋模型和Skip-gram模型。兩個模型都包含三層:輸入層,投影層,輸出層。 1.Skip-Gr
FastText詞向量表示
論文《Enriching Word Vectors with Subword Information》 介紹 FastText的作者也就是word2vec的作者,所以兩者是一脈相承的。 目前的詞向量模型都是把每一個單詞作為單獨的向量,並沒有考慮詞語的內部結構,那麼F
[cs224n].2 詞向量表示word2vec
Part I:背景 Part II:訓練模式(CBOW,Skip Gram) Part III:優化方法(Negative Sampling,Hierarchical SoftMax) Part IV:詞向量衡量指標 Part I:背景 特徵表達是很基礎也很重要
CS224n | 詞向量表示word2vec
1 一是沒有相似性 二是太大 我們可以探索一種直接的方法 一個單詞編碼的含義是你可以直接閱讀的 我們要做的構建這樣的向量,然後做一種類似求解點積的操作。這樣我們就可以瞭解詞彙之間有多少相似性 分佈相似性是指 你可以得到大量表示某個詞彙含義的值,只需要通過
CS224n | 高階詞向量表示
試圖分析原理 如何更有效地捕捉word2vec的本質 關於詞向量表面的評估 最後,你們實際上會很清楚如何去評估詞向量 並且至少有兩種受驗方法來訓練他們 複習 函式是非凸的,所以初始值就很重要了 Skip -gram T對應需要遍歷語料庫的每個視窗
自然語言處理中傳統詞向量表示VS深度學習語言模型(三):word2vec詞向量
在前面的部落格中,我們已經梳理過語言表示和語言模型,之所以將這兩部分內容進行梳理,主要是因為分散式的詞向量語言表示方式和使用神經網路語言模型來得到詞向量這兩部分,構成了後來的word2vec的發展,可以說是word2vec的基礎。1.什麼是詞向量
詞向量表示:word2vec與詞嵌入
在NLP任務中,訓練資料一般是一句話(中文或英文),輸入序列資料的每一步是一個字母。我們需要對資料進行的預處理是:先對這些字母使用獨熱編碼再把它輸入到RNN中,如字母a表示為(1, 0, 0, 0, …,0),字母b表示為(0, 1, 0, 0, …, 0)。如果只考慮小寫字母
CS224n筆記2 詞的向量表示:word2vec
present 技術分享 思想 相對 自然語言 -h padding erro bat 如何表示一個詞語的意思 先來看看如何定義“意思”的意思,英文中meaning代表人或文字想要表達的idea。這是個遞歸的定義,估計查詢idea詞典會用meaning去解釋它。 中
[Algorithm & NLP] 文本深度表示模型——word2vec&doc2vec詞向量模型
www. 頻率 cbo homepage 算法 文章 有一個 tro 概率 閱讀目錄 1. 詞向量 2.Distributed representation詞向量表示 3.詞向量模型 4.word2vec算法思想 5.doc2vec算法思
文字深度表示模型——word2vec&doc2vec詞向量模型(轉)
深度學習掀開了機器學習的新篇章,目前深度學習應用於影象和語音已經產生了突破性的研究進展。深度學習一直被人們推崇為一種類似於人腦結構的人工智慧演算法,那為什麼深度學習在語義分析領域仍然沒有實質性的進展呢? 引用三年前一位網友的話來講: “Steve Renals算了一下icassp錄取文章題目中包含
[Algorithm & NLP] 文字深度表示模型——word2vec&doc2vec詞向量模型
深度學習掀開了機器學習的新篇章,目前深度學習應用於影象和語音已經產生了突破性的研究進展。深度學習一直被人們推崇為一種類似於人腦結構的人工智慧演算法,那為什麼深度學習在語義分析領域仍然沒有實質性的進展呢? 引用三年前一位網友的話來講: “Steve Renals算了一下icassp錄取文章題目中
TensorFlow-9-詞的向量表示
這一節是關於 word2vec 模型的,可以用來學習詞的向量表達,也叫‘word embeddings’。 今天要看的是如何在 TensorFlow 中訓練詞向量,主要看一下這個程式碼: tensorflow/examples/tutorials/w
詞向量原始碼解析:(1)詞向量(詞表示)簡單介紹
在未來的一段時間內,我會全面細緻的解析包括word2vec, GloVe, hyperwords, context2vec, ngram2vec等一系列詞向量(詞表示)工具包。用合理的向量去表示單詞是自然語言處理(NLP)領域中很經典很基本的一個任務。 一份高質量的詞向
Tensorflow教程-字詞的向量表示
Vector Representations of Words 在本教程我們來看一下tensorflow/g3doc/tutorials/word2vec/word2vec_basic.py檢視到一個最簡單的實現。這個基本的例子提供的程式碼可以完成下載一些資料,簡單訓練後展示結果。一旦你覺得已經完全掌握
文本分布式表示(二):用tensorflow和word2vec訓練詞向量
sig 財經 left 調用 采樣 cto imp gensim average 博客園的markdown用起來太心塞了,現在重新用其他編輯器把這篇博客整理了一下。 目前用word2vec算法訓練詞向量的工具主要有兩種:gensim 和 tensorflow。gensim
文字情感分析(二):基於word2vec和glove詞向量的文字表示
上一篇部落格用詞袋模型,包括詞頻矩陣、Tf-Idf矩陣、LSA和n-gram構造文字特徵,做了Kaggle上的電影評論情感分類題。 這篇部落格還是關於文字特徵工程的,用詞嵌入的方法來構造文字特徵,也就是用word2vec詞向量和glove詞向量進行文字表示,訓練隨機森林分類器。 一、訓練word2vec詞
詞向量-LRWE模型
詞向量我們嘗試基於CBOW模型,將知識庫中抽取的知識融合共同訓練,提出LRWE模型。模型的結構圖如下: 下面詳細介紹該模型的思想和求解方法。1. LWE模型 在Word2vec的CBOW模型中,通過上下文的詞預測目標詞,目標是讓目標詞在其給定上下文出現的概率最大,所以詞向量訓練的結果是與其上下文的
矩陣行列式的向量表示
pos sdn span class 向量 con div watermark -s 三角剖分推導中遇到的問題,結論例如以下 矩陣行列式的向量表示
95、自然語言處理svd詞向量
atp ear logs plt images svd分解 range src for import numpy as np import matplotlib.pyplot as plt la = np.linalg words = ["I","like","enjoy