
Python實現直方圖的繪製
Python實現直方圖的繪製:
說明:程式碼執行環境:Win10+Python3+jupyter notebook
直方圖簡介:
直方圖是一種常用的數量型資料的圖形描述方法。它的一個最重要應用是提供了資料的分佈形態的資訊。
直方圖主要的繪製方法:
方法1:通過pandas包中的呼叫Series物件或DataFrame物件的plot()、plot.hist()或hist()方法
方法2:通過matplotlib包中的Axes物件呼叫hist()方法建立直方圖:
首先匯出需要的各種包,並準備好資料:
%matplotlib notebook import pandas as pd import matplotlib.pyplot as plot import numpy as np tips = pd.read_csv('examples/tips.csv') tips['tip_pct']=tips['tip']/(tips['total_bill']-tips['tip']) # 向tips 中新增'tip_pct'列
加入'tip_pct'列後的tips表的結構如下圖所示:

開始繪製直方圖:
方法1具體示例:
Series.plot.hist()示例:
fig,axes = plt.subplots()
tips['tip_pct'].plot.hist(bins=50,ax=axes)
axes.set_title('Histogram of tip_pct') #設定直方圖的標題
axes.set_xlabel('tip_pct') # 設定直方圖橫座標軸的標籤
plt.savefig('p1.png') # 儲存圖片上述程式碼繪製的圖形為:
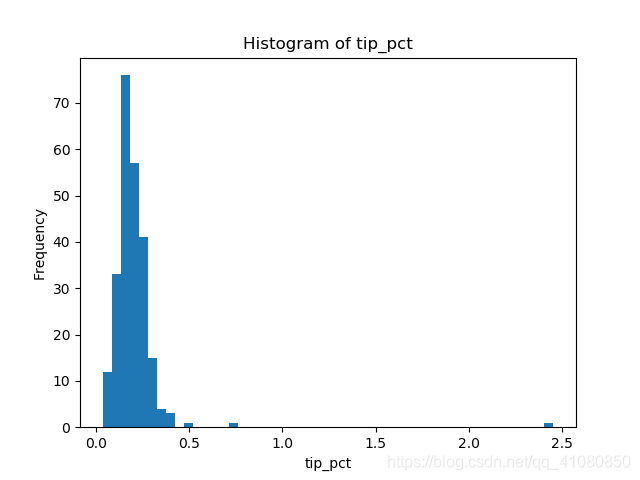
Series.plot.hist()的用法具體參考:
https://pandas.pydata.org/pandas-docs/stable/generated/pandas.Series.plot.hist.html
Series.plot(kind='hist')的用法與Series.plot.hist()類似,具體參考:
https://pandas.pydata.org/pandas-docs/stable/generated/pandas.Series.plot.html#pandas.Series.plot
DataFrame.plot.hist()示例:
fig,axes = plt.subplots(2,2) tips.plot.hist(bins=50,subplots=True,ax=axes,legend=False) axes[0,0].set_title('Histogram og total bill') axes[0,0].set_xlabel('total_bill') axes[0,1].set_title('Histogram of tip') axes[0,1].set_xlabel('tip') axes[1,0].set_title('Histogram of size') axes[1,0].set_xlabel('size') axes[1,1].set_title('Histogram of tip_pct') axes[1,1].set_xlabel('tip_pct') plt.subplots_adjust(wspace=0.5,hspace=0.5) # 調整axes中各個子圖之間的間距 plt.savefig('p2.png')
上述程式碼繪製的圖形為:

可以看到,上圖中四個子圖的橫座標範圍是完全相同的,DataFrame.plot.hist不會根據各個子圖中的資料自動調整橫座標軸上數值的範圍。與DataFrame.plot.hist()方法相比,DataFrame.hist()會根據不同資料自動調整橫座標軸上的的數值範圍,使用起來更加的方便。
DataFrame.plot.hist()的用法具體參考:
https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.plot.hist.html
DataFrame.plot(kind='hist')的用法與DataFrame.plot.hist()類似,具體參考:
ttps://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.plot.html
DataFrame.hist()示例:
fig,axes = plt.subplots(2,2)
tips.hist(column='total_bill',ax=axes[0,0],bins=50)
axes[0,0].set_title('Histogram of total_bill')
axes[0,0].set_xlabel('total_bill')
tips.hist(column='tip',ax=axes[0,1],bins=50)
axes[0,1].set_title('Histogram of tip')
axes[0,1].set_xlabel('tip')
tips.hist(column='size',ax=axes[1,0],bins=50)
axes[1,0].set_title('Histogram of size')
axes[1,0].set_xlabel('size')
tips.hist(column='tip_pct',ax=axes[1,1],bins=50)
axes[1,1].set_title('Histogram of tip_pct')
axes[1,1].set_xlabel('tip_pct')
plt.subplots_adjust(wspace=0.42,hspace=0.42)
plt.savefig('p3.png')
上述程式碼繪製的圖形為:

DataFrame.hist()的用法具體參考:
Series.hist()示例:
fig,axes = plt.subplots(1,2) # xrot表示x軸上資料標籤的偏轉角度
tips['tip_pct'].hist(by=tips['smoker'],ax=axes,bins=50,xrot=0.1)
axes[0].set_title('tip_pct of non-smoker ')
axes[0].set_xlabel('tip_pct')
axes[1].set_title('tip_pct of smoker ')
axes[1].set_xlabel('tip_pct')
plt.subplots_adjust(wspace=0.4,hspace=0.4)
plt.savefig('p4.png')上述程式碼繪製的圖形為:

Series.hist()的用法具體參考:
https://pandas.pydata.org/pandas-docs/stable/generated/pandas.Series.hist.html#pandas.Series.hist
方法2具體示例:
Axes.hist()的用法具體參考:
https://matplotlib.org/api/_as_gen/matplotlib.axes.Axes.hist.html#matplotlib.axes.Axes.hist
頻數分佈直方圖示例:
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(19680801) # 讓每次生成的隨機數相同
# 示例資料
mu = 100 # 資料均值
sigma = 15 # 資料標準差
x = mu + sigma * np.random.randn(437)
num_bins = 50
fig, ax = plt.subplots() # 等價於fig, ax = plt.subplots(1,1)
# 資料的頻數分佈直方圖
n, bins, patches = ax.hist(x, num_bins,density=False)
# n是一個數組或者由陣列組成的列表,表示落在每個分組中的資料的頻數
# bins是一個數組,表示每個分組的邊界,一共有50個組,所以bins的長度就是51
# patches是一個列表或者巢狀列表,長度是50,,列表裡的元素可以理解成直方圖中的小長方條
ax.set_xlabel('Smarts')
ax.set_ylabel('Frequency')
ax.set_title(r'Histogram of IQ: $\mu=100$, $\sigma=15$')
plt.savefig('p5.png')
上述程式碼繪製的圖形為:
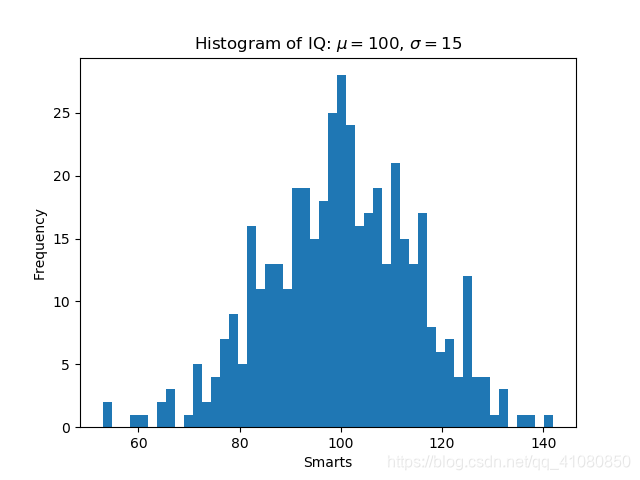
頻率分佈直方圖示例:
np.random.seed(19680801) # 讓每次生成的隨機數相同
# 示例資料
mu = 100 # 資料均值
sigma = 15 # 資料標準差
x = mu + sigma * np.random.randn(437)
num_bins = 50
fig, ax = plt.subplots() # 等價於fig, ax = plt.subplots(1,1)
# 資料的頻率分佈直方圖
n, bins, patches = ax.hist(x, num_bins,density=True)
# n是一個數組或者由陣列組成的列表,表示落在每個分組中的資料的頻數
# bins是一個數組,表示每個分組的邊界,一共有50個組,所以bins的長度就是51
# patches是一個列表或者巢狀列表,長度是50,,列表裡的元素可以理解成直方圖中的小長方條
ax.set_xlabel('Smarts')
ax.set_ylabel('Probability density') # 頻率分佈直方圖的縱軸表示的是頻率/組距
ax.set_title(r'Histogram of IQ: $\mu=100$, $\sigma=15$')
plt.savefig('p6.png')上述程式碼繪製的圖形為:

如何給直方圖中的長條新增資料標記?
np.random.seed(19680801) # 讓每次生成的隨機數相同
# 示例資料
mu = 100 # 資料均值
sigma = 15 # 資料標準差
x = mu + sigma * np.random.randn(437)
num_bins = 5 # 為了便於給直方圖中的長條新增資料標籤,將資料分成五組
fig, ax = plt.subplots() # 等價於fig, ax = plt.subplots(1,1)
# 資料的頻率分佈直方圖(帶資料標籤)
n, bins, patches = ax.hist(x, num_bins,density=True)
# n是一個數組或者由陣列組成的列表,表示落在每個分組中的資料的頻數
# bins是一個數組,表示每個分組的邊界,一共有50個組,所以bins的長度就是51
# patches是一個列表或者巢狀列表,長度是50,,列表裡的元素可以理解成直方圖中的小長方條
# 寫一個給直方圖中的長條新增資料標籤的函式
def data_marker(patches):
for patch in patches:
height = patch.get_height()
if height != 0:
ax.text(patch.get_x() + patch.get_width()/4, height + 0.0002,'{:.5f}'.format(height))
data_marker(patches) # 呼叫data_marker函式
ax.set_xlabel('Smarts')
ax.set_ylabel('Probability density') # 頻率分佈直方圖的縱軸表示的是頻率/組距
ax.set_title(r'Histogram of IQ: $\mu=100$, $\sigma=15$')
plt.savefig('p7.png') # 儲存生成的圖片上述程式碼繪製的圖形為:

參考資料:
《Python for Data Analysis》第二版
https://blog.csdn.net/a821235837/article/details/52839050
https://wenku.baidu.com/view/036fea38aef8941ea66e052f.html
https://blog.csdn.net/yywan1314520/article/details/50818471
matplotlib、pandas官方文件
PS:本文為博主原創文章,轉載請註明出處。