
FPGA在深度學習的未來
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow
也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
這是上學期我上的一門積體電路原理的課程調研報告, 寫的還算可以, 最後還被老師選中上去presentation(被選中的概率很大…).
摘要
近十年來,人工智慧又到了一個快速發展的階段。深度學習在其發展中起到了中流砥柱的作用,儘管擁有強大的模擬預測能力,深度學習還面臨著超大計算量的問題。在硬體層面上,GPU,ASIC,FPGA都是解決龐大計算量的方案。本文將闡釋深度學習和FPGA各自的結構特點以及為什麼用FPGA加速深度學習是有效的,並且將介紹一種遞迴神經網路(RNN)在FPGA平臺上的實現方案。
揭開深度學習的面紗
深度學習是機器學習的一個領域,都屬於人工智慧的範疇。深度學習主要研究的是人工神經網路的演算法、理論、應用。自從2006年Hinton等人提出來之後,深度學習高速發展,在自然語言處理、影象處理、語音處理等領域都取得了非凡的成就,受到了巨大的關注。在網際網路概念被人們普遍關注的時代,深度學習給人工智慧帶來的影響是巨大的,人們會為它隱含的巨大潛能以及廣泛的應用價值感到不可思議。
事實上,人工智慧是上世紀就提出來的概念。1957年,Rosenblatt提出了感知機模型(Perception),即兩層的線性網路;1986年,Rumelhart等人提出了後向傳播演算法(Back Propagation),用於三層的神經網路的訓練,使得訓練優化引數龐大的神經網路成為可能;1995年,Vapnik等人發明了支援向量機(Support Vector Machines),在分類問題中展現了其強大的能力。以上都是人工智慧歷史上比較有代表性的事件,然而受限於當時計算能力,AI總是在一段高光之後便要陷入灰暗時光——稱為:“AI寒冬”。
然而,隨著計算機硬體能力和儲存能力的提升,加上龐大的資料集,現在正是人AI發展的最好時機。自Hinton提出DBN(深度置信網路)以來,人工智慧就在不斷的高速發展。在影象處理領域,CNN(卷積神經網路)發揮了不可替代的作用,在語音識別領域,RNN(遞迴神經網路)也表現的可圈可點。而科技巨頭也在加緊自己的腳步,谷歌的領軍人物是Hinton,其重頭戲是Google brain,並且在去年還收購了利用AI在遊戲中擊敗人類的DeepMind;Facebook的領軍人物是Yann LeCun,另外還組建了Facebook的AI實驗室,Deepface在人臉識別的準確率更達到了驚人的97.35%;而國內的巨頭當屬百度,在挖來了斯坦福大學教授Andrew Ng(Coursera的聯合創始人)併成立了百度大腦專案之後,百度在語音識別領域的表現一直十分強勢。
一覽深度學習
簡單來說,深度學習與傳統的機器學習演算法的分類是一致的,主要分為監督學習(supervised learning)和非監督學習(unsupervised learning)。所謂監督學習,就是輸出是有標記的學習,讓模型通過訓練,迭代收斂到目標值;而非監督學習不需要人為輸入標籤,模型通過學習發現數據的結構特徵。比較常見的監督學習方法有邏輯迴歸、多層感知機、卷積神經網路登;而非監督學習主要有稀疏編碼器、受限玻爾茲曼機、深度置信網路等[1]。所有的這些都是通過神經網路來實現的,他們通常來說都是非常複雜的結構,需要學習的引數也非常多。但是神經網路也可以做簡單的事情,比如XNOR門,如圖.

在圖1(a)中,兩個輸入x_1和x_2都是分別由一個神經元表示,在輸入中還加入了一個作為偏置(bias)的神經元,通過訓練學習引數,最終整個模型的引數收斂,功能和圖1(b)真值表一模一樣。圖1(c)分類結果。
而通常來說,模型都是比較複雜的。比如ILSVRC2012年影象識別大賽中Krizhevsky等人構建出來的 Alex Net[2]。他們一共構建了11層的神經網路(5個卷積層,3個全連線層,3個池化層),一共有65萬個神經元,6千萬個引數,最終達到了15.2%的識別錯誤率,大大領先於第二名的26.2%。 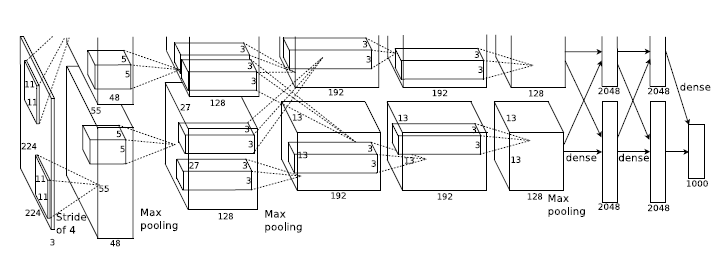
圖2. Alex Net神經網路
當前深度學習得以流行,是得益於大資料和計算效能的提升。但其仍然遭受計算能力和資料量的瓶頸。針對資料量的需求,專家們可以通過模型的調整、變更來緩解,但計算力的挑戰沒有捷徑。科大訊飛、百度、阿里、360在深度學習方面也面臨著計算力的困擾。科大訊飛的深度學習平臺屬於計算密集型的平臺,叢集幾百臺機器之間要實現高速互聯,是類似超算的結構,但它又不是一個非常典型的超算。科大訊飛最開始探索傳統的方式,用大量CPU來支援大規模資料預處理,執行GMM-HMM等經典模型的訓練,在千小時的資料量下,效果很不好。而360每天處理的資料有上億條,引數50萬以上,如果用CPU,每次模型訓練就要花幾天,這對於崇尚快速迭代的網際網路公司運營來說簡直是不可接受的。
為什麼選擇FPGA
FPGA(Field Programmable Gate Array)是在PAL、GAL、CPLD等可程式設計邏輯器件的基礎上進一步發展的產物。它是作為專用積體電路領域中的一種半定製電路而出現的,既解決了全定製電路的不足,又克服了原有可程式設計邏輯器件閘電路數有限的缺點[3]。FPGA的開發相對於傳統PC、微控制器的開發有很大不同。FPGA以並行運算為主,以硬體描述語言來實現;相比於PC或微控制器(無論是馮諾依曼結構還是哈佛結構)的順序操作有很大區別。FPGA開發需要從頂層設計、模組分層、邏輯實現、軟硬體除錯等多方面著手。FPGA可以通過燒寫位流檔案對其進行反覆程式設計,目前,絕大多數 FPGA 都採用基於 SRAM(Static Random Access Memory 靜態隨機儲存器)工藝的查詢表結構,通過燒寫位流檔案改變查詢表內容實現配置。
下面討論幾種可實現深度學習演算法的硬體[4]。
使用CPU。在2006年的時候,人們還是用序列處理器處理機器學習的問題,當時Mutch 和 Lowe開發了一個工具FHLib(feature hierarchy library)用來處理hierarchical 模型。對於CPU來說,它所要求的程式設計量是比較少的並且有可遷移性的好處,但是序列處理的特點變成了它在深度學習領域的缺點,而這個缺點是致命的。時至今日,據2006年已經過去了十年,過去的十年積體電路的發展還是遵循著摩爾定律,CPU的效能得到了極大的提升,然而,這並沒有讓CPU再次走入深度學習研究者的視野。儘管在小資料集上CPU能有一定的計算能力表現,多核使得它能夠並行處理,然而這對深度學習來說還是遠遠不夠的。
使用GPU。GPU走進了研究者的視線,相比於CPU,GPU的核心數大大提高了,這也讓它有更強大的並行處理能力,它還有更加強大的控制資料流和儲存資料的能力。在[5]中,Chikkerur進行了CPU和GPU在處理目標識別能力上的差別,最終GPU的處理速度是CPU的3-10倍。
使用ASIC。專用積體電路晶片(ASIC)由於其定製化的特點,是一種比GPU更高效的方法。但是其定製化也決定了它的可遷移性低,一旦專用於一個設計好的系統中,要遷移到其它的系統是不可能的。並且,其造價高昂,生產週期長,使得它在目前的研究中是不被考慮的。當然,其優越的效能還是能在一些領域勝任。[6]用的就是ASIC 的方案,在640×480pixel的影象中識別速率能達到 60幀/秒。
使用FPGA。FPGA在GPU和ASIC中取得了權衡,很好的兼顧了處理速度和控制能力。一方面,FPGA是可程式設計重構的硬體,因此相比GPU有更強大的可調控能力;另一方面,與日增長的門資源和記憶體頻寬使得它有更大的設計空間。更方便的是,FPGA還省去了ASIC方案中所需要的流片過程。FPGA的一個缺點是其要求使用者能使用硬體描述語言對其進行程式設計。但是,已經有科技公司和研究機構開發了更加容易使用的語言比如Impulse Accelerated Technologies Inc. 開發了C-to-FPGA編譯器使得FPGA更加貼合用戶的使用[7],耶魯的E-Lab 開發了Lua指令碼語言[8]。這些工具在一定程度上縮短了研究者的開發時限,使研究更加簡單易行。
在FPGA上執行LSTM神經網路
LSTM簡介
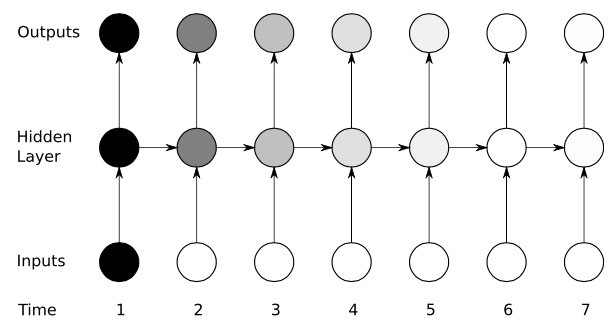
傳統的RNN由一個三層的網路:輸入層,隱藏層,輸出層;其中的資訊作用到下一時刻的輸入,這樣的結構簡單的模仿了人腦的記憶功能,圖3是其拓撲圖:
只有一個隱藏層方程:
其中 和 分別是輸入和隱藏層的權重, 是偏置。
tanh 是啟用函式:
LSTM [9]是RNN(遞迴神經網路)的一種,在處理時序資料得到了最廣泛的應用,它由門控制資訊一共有三個個門:輸入門,遺忘門,輸出門,另外還有隱藏層和記憶細胞。圖4是其拓撲圖:
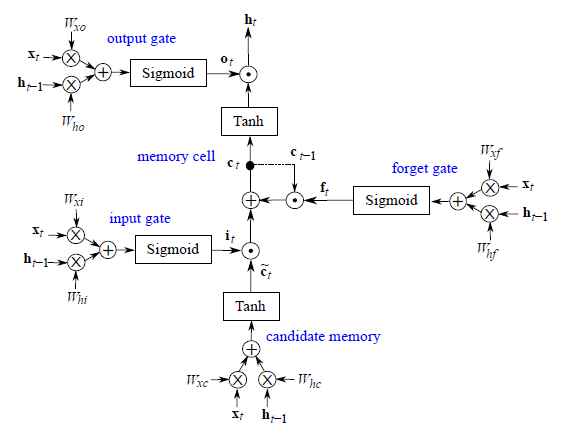
輸入門控制了某一時刻的輸入;遺忘門通過作用到上一時刻記憶細胞上,控制了上一時刻的資料流要流多少進入下一時刻;記憶細胞是由上一時刻的輸入和這一時刻的候選輸入共同決定的;輸出門作用到記憶細胞上,決定了這一時刻的隱藏層資訊,並且送到下一層神經網路上。全部方程如下:
其中 代表各自的權重, 代表各自的偏置, 是logistic sigmoid 函式:
設計FPGA模組
研究[10]使用的FPGA是Xilinx的Zedboard Zynq ZC7020板子。圖5是它的概覽 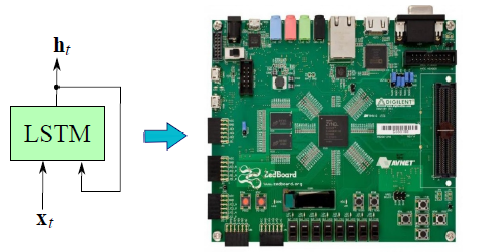
LSTM主要進行的是矩陣的乘法和非線性函式的計算(tanh,sigmoid),因此,選擇了Q8.8定點。
矩陣乘法由MAC單元進行(Multiply Accumulate),一共有兩個資料流:向量和權重矩陣流,如圖6(a)。在迭代完一次之後MAC就會重置以防止之前的資料混入下一時刻的資料。兩個MAC單元的資料相加之後進行非線性函式計算。同時用一個rescale模組將32位的資料轉變為16位的資料。
標量計算的模組,是為了計算和,最終傳入下一時刻的計算。如圖6(b).
整個模型一共用了三個圖6(a)和一個圖6(b)的模組,如圖6(c)。資料的流入流出用了DMA(Direct Memory Access)串列埠控制。由於DMA串列埠是獨立的,因此,還需要一個時鐘模組對其進行時序控制。時鐘模組主要是一個緩衝儲存器組成並暫存了一些資料直到資料都到達。當最後的一個埠資料流入時鐘模組才開始傳送資料,這保證了輸入跟權重矩陣是同個時刻相關的。

因此,LSTM模型的運算分為三個階段:
- 計算和
- 計算和
- 計算和
第一和第二階段兩個門模組(4個MAC單元)平行計算,得到了,, 和並且存入FIFO(First In First Out)中。最後一個階段取出FIFO中的向量計算和。之後,LSTM模組繼續等待進行下一層或者下一時刻的資料的計算。在最後的時刻LSTM計算到最後一層之後,模型輸出最終的目標值。
結果分析
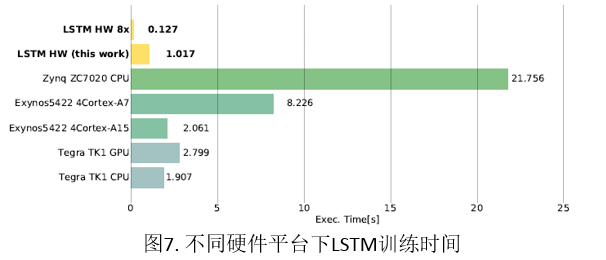
通過在不同平臺上訓練LSTM網路,我們得到了不同模型的對比。表1是平臺的引數,執行結果如圖7,可以發現:即使在142MHz的時鐘頻率下,FPGA平臺下的執行時間遠遠小於其他平臺,並行八個LSTM 記憶細胞的處理取得了比 Exynos5422 快16倍的結果。

未來展望
深度學習採用包含多個隱藏層的深層神經網路(DeepNeural Networks,DNN)模型。DNN內在的並行性,使得具備大規模並行體系結構的GPU和FPGA成為加速深度學習的主流硬體平臺,其突出優勢是能夠根據應用的特徵來定製計算和儲存結構,達到硬體結構與深度學習演算法的最優匹配,獲得更高的效能功耗比;並且,FPGA靈活的重構功能也方便了演算法的微調和優化,能夠大大縮短開發週期。毫無疑問,FPGA在深度學習的未來是十分值得期待的。
參考文獻:
[1]Y. Bengio, Learning Deep Architectures for AI, vol. 2, no. 1. 2009.[2]Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems (pp. 1097-1105).
[3] Wikipedia.(2015).Field-programmable gate array [Online]. Available:https://en.wikipedia.org/wiki/Field-programmable_gate_array
[4] G. Orchard, J. G. Martin, R. J. Vogelstein, and R. Etienne-Cummings, “Fast Neuromimetic Object Recognition using FPGA Outperforms GPU Implementations,” vol. 24, no. 8, pp. 1239–1252, 2015.
[5]S. Chikkerur. (2008). CUDA Implementation of a Biologically
Inspired Object Recognition System [Online]. Available:http://code.google.com/p/cbcl-model-cuda/[6] J. Kim, M. Kim, S. Lee, J. Oh, K. Kim, and H. Yoo, “A 201.4 GOPS
496 mW real-time multi-object recognition processor with bio-inspired neural perception engine,” IEEE J. Solid-State Circuits, vol. 45, no. 1,pp. 32–45, Jan. 2010.[7] Impulse Accelerated Technology Website. (2008). Impulse Accelerated Technology Inc., Bellevue, WA, USA [Online]. Available:http://www.impulseaccelerated.com
[8] R. Ierusalimschy, L. de Figueiredo, and W. Celes, Lua 5.1 Reference Manual. Rio de Janeiro, Brazil: Roberto Ierusalimschy, 2006.
[9] Hochreiter, Sepp and Schmidhuber, J¨urgen. Long short-term memory. Neural computation, 9(8):1735–1780, 1997.
[10] A. X. M. Chang, B. Martini, and E. Culurciello, “Recurrent Neural Networks Hardware Implementation on FPGA,” Iclr, p. 9, 2016.
給我老師的人工智慧教程打call!http://blog.csdn.net/jiangjunshow

這是上學期我上的一門積體電路原理的課程調研報告, 寫的還算可以, 最後還被老師選中上去presentation(被選中的概率很大…).
摘要
近十年來,人工智慧又到了一個快速發展的階段。深度學習在其發展中起到了中流砥柱的作用,儘管擁有強大的模擬預測能力,深度學習還面臨著超大計算量的問題。在硬體層面上,GPU,ASIC,FPGA都是解決龐大計算量的方案。本文將闡釋深度學習和FPGA各自的結構特點以及為什麼用FPGA加速深度學習是有效的,並且將介紹一種遞迴神經網路(RNN)在FPGA平臺上的實現方案。
揭開深度學習的面紗
深度學習是機器學習的一個領域,都屬於人工智慧的範疇。深度學習主要研究的是人工神經網路的演算法、理論、應用。自從2006年Hinton等人提出來之後,深度學習高速發展,在自然語言處理、影象處理、語音處理等領域都取得了非凡的成就,受到了巨大的關注。在網際網路概念被人們普遍關注的時代,深度學習給人工智慧帶來的影響是巨大的,人們會為它隱含的巨大潛能以及廣泛的應用價值感到不可思議。
事實上,人工智慧是上世紀就提出來的概念。1957年,Rosenblatt提出了感知機模型(Perception),即兩層的線性網路;1986年,Rumelhart等人提出了後向傳播演算法(Back Propagation),用於三層的神經網路的訓練,使得訓練優化引數龐大的神經網路成為可能;1995年,Vapnik等人發明了支援向量機(Support Vector Machines),在分類問題中展現了其強大的能力。以上都是人工智慧歷史上比較有代表性的事件,然而受限於當時計算能力,AI總是在一段高光之後便要陷入灰暗時光——稱為:“AI寒冬”。
然而,隨著計算機硬體能力和儲存能力的提升,加上龐大的資料集,現在正是人AI發展的最好時機。自Hinton提出DBN(深度置信網路)以來,人工智慧就在不斷的高速發展。在影象處理領域,CNN(卷積神經網路)發揮了不可替代的作用,在語音識別領域,RNN(遞迴神經網路)也表現的可圈可點。而科技巨頭也在加緊自己的腳步,谷歌的領軍人物是Hinton,其重頭戲是Google brain,並且在去年還收購了利用AI在遊戲中擊敗人類的DeepMind;Facebook的領軍人物是Yann LeCun,另外還組建了Facebook的AI實驗室,Deepface在人臉識別的準確率更達到了驚人的97.35%;而國內的巨頭當屬百度,在挖來了斯坦福大學教授Andrew Ng(Coursera的聯合創始人)併成立了百度大腦專案之後,百度在語音識別領域的表現一直十分強勢。
一覽深度學習
簡單來說,深度學習與傳統的機器學習演算法的分類是一致的,主要分為監督學習(supervised learning)和非監督學習(unsupervised learning)。所謂監督學習,就是輸出是有標記的學習,讓模型通過訓練,迭代收斂到目標值;而非監督學習不需要人為輸入標籤,模型通過學習發現數據的結構特徵。比較常見的監督學習方法有邏輯迴歸、多層感知機、卷積神經網路登;而非監督學習主要有稀疏編碼器、受限玻爾茲曼機、深度置信網路等[1]。所有的這些都是通過神經網路來實現的,他們通常來說都是非常複雜的結構,需要學習的引數也非常多。但是神經網路也可以做簡單的事情,比如XNOR門,如圖.
在圖1(a)中,兩個輸入x_1和x_2都是分別由一個神經元表示,在輸入中還加入了一個作為偏置(bias)的神經元,通過訓練學習引數,最終整個模型的引數收斂,功能和圖1(b)真值表一模一樣。圖1(c)分類結果。
而通常來說,模型都是比較複雜的。比如ILSVRC2012年影象識別大賽中Krizhevsky等人構建出來的 Alex Net[2]。他們一共構建了11層的神經網路(5個卷積層,3個全連線層,3個池化層),一共有65萬個神經元,6千萬個引數,最終達到了15.2%的識別錯誤率,大大領先於第二名的26.2%。
圖2. Alex Net神經網路
當前深度學習得以流行,是得益於大資料和計算效能的提升。但其仍然遭受計算能力和資料量的瓶頸。針對資料量的需求,專家們可以通過模型的調整、變更來緩解,但計算力的挑戰沒有捷徑。科大訊飛、百度、阿里、360在深度學習方面也面臨著計算力的困擾。科大訊飛的深度學習平臺屬於計算密集型的平臺,叢集幾百臺機器之間要實現高速互聯,是類似超算的結構,但它又不是一個非常典型的超算。科大訊飛最開始探索傳統的方式,用大量CPU來支援大規模資料預處理,執行GMM-HMM等經典模型的訓練,在千小時的資料量下,效果很不好。而360每天處理的資料有上億條,引數50萬以上,如果用CPU,每次模型訓練就要花幾天,這對於崇尚快速迭代的網際網路公司運營來說簡直是不可接受的。
為什麼選擇FPGA
FPGA(Field Programmable Gate Array)是在PAL、GAL、CPLD等可程式設計邏輯器件的基礎上進一步發展的產物。它是作為專用積體電路領域中的一種半定製電路而出現的,既解決了全定製電路的不足,又克服了原有可程式設計邏輯器件閘電路數有限的缺點[3]。FPGA的開發相對於傳統PC、微控制器的開發有很大不同。FPGA以並行運算為主,以硬體描述語言來實現;相比於PC或微控制器(無論是馮諾依曼結構還是哈佛結構)的順序操作有很大區別。FPGA開發需要從頂層設計、模組分層、邏輯實現、軟硬體除錯等多方面著手。FPGA可以通過燒寫位流檔案對其進行反覆程式設計,目前,絕大多數 FPGA 都採用基於 SRAM(Static Random Access Memory 靜態隨機儲存器)工藝的查詢表結構,通過燒寫位流檔案改變查詢表內容實現配置。
下面討論幾種可實現深度學習演算法的硬體[4]。
使用CPU。在2006年的時候,人們還是用序列處理器處理機器學習的問題,當時Mutch 和 Lowe開發了一個工具FHLib(feature hierarchy library)用來處理hierarchical 模型。對於CPU來說,它所要求的程式設計量是比較少的並且有可遷移性的好處,但是序列處理的特點變成了它在深度學習領域的缺點,而這個缺點是致命的。時至今日,據2006年已經過去了十年,過去的十年積體電路的發展還是遵循著摩爾定律,CPU的效能得到了極大的提升,然而,這並沒有讓CPU再次走入深度學習研究者的視野。儘管在小資料集上CPU能有一定的計算能力表現,多核使得它能夠並行處理,然而這對深度學習來說還是遠遠不夠的。
使用GPU。GPU走進了研究者的視線,相比於CPU,GPU的核心數大大提高了,這也讓它有更強大的並行處理能力,它還有更加強大的控制資料流和儲存資料的能力。在[5]中,Chikkerur進行了CPU和GPU在處理目標識別能力上的差別,最終GPU的處理速度是CPU的3-10倍。
使用ASIC。專用積體電路晶片(ASIC)由於其定製化的特點,是一種比GPU更高效的方法。但是其定製化也決定了它的可遷移性低,一旦專用於一個設計好的系統中,要遷移到其它的系統是不可能的。並且,其造價高昂,生產週期長,使得它在目前的研究中是不被考慮的。當然,其優越的效能還是能在一些領域勝任。[6]用的就是ASIC 的方案,在640×480pixel的影象中識別速率能達到 60幀/秒。
使用FPGA。FPGA在GPU和ASIC中取得了權衡,很好的兼顧了處理速度和控制能力。一方面,FPGA是可程式設計重構的硬體,因此相比GPU有更強大的可調控能力;另一方面,與日增長的門資源和記憶體頻寬使得它有更大的設計空間。更方便的是,FPGA還省去了ASIC方案中所需要的流片過程。FPGA的一個缺點是其要求使用者能使用硬體描述語言對其進行程式設計。但是,已經有科技公司和研究機構開發了更加容易使用的語言比如Impulse Accelerated Technologies Inc. 開發了C-to-FPGA編譯器使得FPGA更加貼合用戶的使用[7],耶魯的E-Lab 開發了Lua指令碼語言[8]。這些工具在一定程度上縮短了研究者的開發時限,使研究更加簡單易行。
在FPGA上執行LSTM神經網路
LSTM簡介
傳統的RNN由一個三層的網路:輸入層,隱藏層,輸出層;其中的資訊作用到下一時刻的輸入,這樣的結構簡單的模仿了人腦的記憶功能,圖3是其拓撲圖:
只有一個隱藏層方程:
其中 和 分別是輸入和隱藏層的權重, 是偏置。
tanh 是啟用函式:
LSTM [9]是RNN(遞迴神經網路)的一種,在處理時序資料得到了最廣泛的應用,它由門控制資訊一共有三個個門:輸入門,遺忘門,輸出門,另外還有隱藏層和記憶細胞。圖4是其拓撲圖:
輸入門控制了某一時刻的輸入;遺忘門通過作用到上一時刻記憶細胞上,控制了上一時刻的資料流要流多少進入下一時刻;記憶細胞是由上一時刻的輸入和這一時刻的候選輸入共同決定的;輸出門作用到記憶細胞上,決定了這一時刻的隱藏層資訊,並且送到下一層神經網路上。全部方程如下:
其中 代表各自的權重, 代表各自的偏置, 是logistic sigmoid 函式:
設計FPGA模組
研究[10]使用的FPGA是Xilinx的Zedboard Zynq ZC7020板子。圖5是它的概覽
LSTM主要進行的是矩陣的乘法和非線性函式的計算(tanh,sigmoid),因此,選擇了Q8.8定點。
矩陣乘法由MAC單元進行(Multiply Accumulate),一共有兩個資料流:向量和權重矩陣流,如圖6(a)。在迭代完一次之後MAC就會重置以防止之前的資料混入下一時刻的資料。兩個MAC單元的資料相加之後進行非線性函式計算。同時用一個rescale模組將32位的資料轉變為16位的資料。
標量計算的模組,是為了計算和,最終傳入下一時刻的計算。如圖6(b).
整個模型一共用了三個圖6(a)和一個圖6(b)的模組,如圖6(c)。資料的流入流出用了DMA(Direct Memory Access)串列埠控制。由於DMA串列埠是獨立的,因此,還需要一個時鐘模組對其進行時序控制。時鐘模組主要是一個緩衝儲存器組成並暫存了一些資料直到資料都到達。當最後的一個埠資料流入時鐘模組才開始傳送資料,這保證了輸入跟權重矩陣是同個時刻相關的。
因此,LSTM模型的運算分為三個階段:
- 計算和
- 計算和
- 計算和
第一和第二階段兩個門模組(4個MAC單元)平行計算,得到了,, 和並且存入FIFO(First In First Out)中。最後一個階段取出FIFO中的向量計算和。之後,LSTM模組繼續等待進行下一層或者下一時刻的資料的計算。在最後的時刻LSTM計算到最後一層之後,模型輸出最終的目標值。
結果分析
通過在不同平臺上訓練LSTM網路,我們得到了不同模型的對比。表1是平臺的引數,執行結果如圖7,可以發現:即使在142MHz的時鐘頻率下,FPGA平臺下的執行時間遠遠小於其他平臺,並行八個LSTM 記憶細胞的處理取得了比 Exynos5422 快16倍的結果。
未來展望
深度學習採用包含多個隱藏層的深層神經網路(DeepNeural Networks,DNN)模型。DNN內在的並行性,使得具備大規模並行體系結構的GPU和FPGA成為加速深度學習的主流硬體平臺,其突出優勢是能夠根據應用的特徵來定製計算和儲存結構,達到硬體結構與深度學習演算法的最優匹配,獲得更高的效能功耗比;並且,FPGA靈活的重構功能也方便了演算法的微調和優化,能夠大大縮短開發週期。毫無疑問,FPGA在深度學習的未來是十分值得期待的。
參考文獻:
[1]Y. Bengio, Learning Deep Architectures for AI, vol. 2, no. 1. 2009.[2]Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems (pp. 1097-1105).
[3] Wikipedia.(2015).Field-programmable gate array [Online]. Available:https://en.wikipedia.org/wiki/Field-programmable_gate_array
[4] G. Orchard, J. G. Martin, R. J. Vogelstein, and R. Etienne-Cummings, “Fast Neuromimetic Object Recognition using FPGA Outperforms GPU Implementations,” vol. 24, no. 8, pp. 1239–1252, 2015.
[5]S. Chikkerur. (2008). CUDA Implementation of a Biologically
Inspired Object Recognition System [Online]. Available:http://code.google.com/p/cbcl-model-cuda/[6] J. Kim, M. Kim, S. Lee, J. Oh, K. Kim, and H. Yoo, “A 201.4 GOPS
496 mW real-time multi-object recognition processor with bio-inspired neural perception engine,” IEEE J. Solid-State Circuits, vol. 45, no. 1,pp. 32–45, Jan. 2010.[7] Impulse Accelerated Technology Website. (2008). Impulse Accelerated Technology Inc., Bellevue, WA, USA [Online]. Available:http://www.impulseaccelerated.com
[8] R. Ierusalimschy, L. de Figueiredo, and W. Celes, Lua 5.1 Reference Manual. Rio de Janeiro, Brazil: Roberto Ierusalimschy, 2006.
[9] Hochreiter, Sepp and Schmidhuber, J¨urgen. Long short-term memory. Neural computation, 9(8):1735–1780, 1997.
[10] A. X. M. Chang, B. Martini, and E. Culurciello, “Recurrent Neural Networks Hardware Implementation on FPGA,” Iclr, p. 9, 2016.