
基於FPGA的深度學習CNN加速器設計
https://yq.aliyun.com/articles/5752
因為CNN的特有計算模式,通用處理器對於CNN實現效率並不高,不能滿足效能要求。 因此,近來已經提出了基於FPGA,GPU甚至ASIC設計的各種加速器來提高CNN設計的效能。 在這些方法中,基於FPGA的加速器引起了研究人員越來越多的關注,因為它們具有效能好,能源效率高,開發週期快,重構能力強等優點。
在實驗中,研究人員發現在FPGA相同的邏輯資源利用率情況下,兩種不同解決方案可能會有多達90%的效能差異。所以找出最佳解決方案是很重要的,特別是當考慮到FPGA平臺的計算資源和儲存器頻寬的限制時。 實際上,如果加速器結構沒有精心設計,其計算吞吐量與提供FPGA平臺的記憶體頻寬不匹配。 這意味著由於邏輯資源或儲存器頻寬的利用不足將造成效能的降級。
不幸的是,FPGA技術和深度學習演算法的進步同時加劇了這個問題。 一方面,由最先進的FPGA平臺提供的日益增加的邏輯資源和儲存器頻寬擴大了設計空間。 此外,當應用各種FPGA優化技術(如迴圈平鋪和變換)時,設計空間進一步擴大。 另一方面,為了適應現代應用的需求,深度學習演算法的規模和複雜性也在不斷增加。所以,在設計空間中找出最優解是比較困難的。 因此,迫切需要有效的方法來探索基於FPGA的CNN設計空間。
然而現有的大部分工作主要關注計算引擎優化,它們有的忽略外部儲存器操作,有的將其加速器直接連線到外部儲存器。還有些研究工作通過精細的資料重用減少外部資料訪問來加速CNN應用。然而,這種方法並不一定會導致最佳的整體效能。此外,這種方法需要重新配置不同層次的FPGA計算。這在某些情況下是不可行的。
因此,為了有效地探索設計空間,有研究人員提出了一種分析設計方案。這種方案考慮到緩衝區管理和頻寬優化,以更好地利用FPGA資源並實現更高的效能。同時加速器能夠跨越不同的層執行加速作業,而無需重新程式設計FPGA。下面我們具體來看一下這種方案。
考慮到在應用中基本都是將訓練好的CNN模型部署到現有計算平臺上進行預測操作,所以,很多的FPGA加速方案中僅考慮優化前向操作。同時又有研究表明,卷積操作佔據了CNN模型將近90%的計算時間,所以,本方案也是僅考慮優化CNN模型前向計算中的卷積運算,優化的模型選擇為經典的AlexNet。同時為了更好的分析網路的效能,研究人員藉助Roofline Model進行優化方案的設計。通過這個 model,既可以評估一個設計的效率,還能很容易看出設計到底是 computation-limited 還是 memory bandwidth-limited,可以幫助確定進一步優化的思路。
首先,我們先來了解一下CNN中的卷積運算的規則,CNN中的卷積運算如圖1所示,程式碼1表示其虛擬碼。
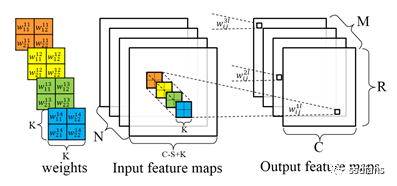
圖1

程式碼1
幾乎所有的基於FPGA的加速方案,都如圖2顯示的那樣,FPGA上的CNN加速器設計主要由處理元件(PE),片上緩衝器,外部儲存器和片上/片外互連幾個元件組成。其中PE是卷積的基本計算單元。用於處理的所有資料都儲存在外部儲存器中。由於片上資源限制,資料首先被快取在片上緩衝區中,然後再饋送給PE。雙緩衝區用於通過資料傳輸時間來覆蓋計算時間。片內互連專用於PE和片上緩衝儲存器之間的資料通訊。
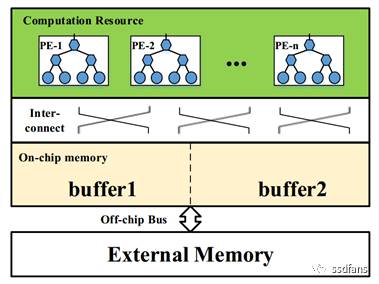
圖2
通過觀察圖2,我們可以發現有幾個設計問題妨礙了FPGA平臺上高效的CNN加速器設計。首先,為了適應晶片上的一小部分資料,迴圈平鋪是必須的。不正確的平鋪可能會降低資料重用的效率和資料處理的並行性。第二,應仔細考慮PE和緩衝庫的組織以及它們之間的互連,以便有效地處理片上資料。第三,PE的資料處理吞吐量應與FPGA平臺提供的片外頻寬匹配。
為了解決上述問題,下面逐條分解實現方案。
1)首先,方案採用迴圈平鋪(程式碼2)。注意,迴圈迭代器i和j由於CNN中卷積視窗大小K的相對小的尺寸(通常在3到11之間)而不是平鋪的。其他迴圈迭代器(row,col,to和ti)平鋪到圖形迴圈和點迴圈中(程式碼2中的trr,tcc和tii)。
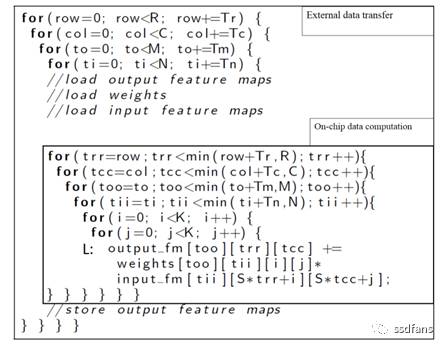
程式碼2
2)片上計算優化的實現
計算優化的目的是在充分利用FPGA硬體平臺提供的所有計算資源的同時,實現高效的迴圈展開/流水線化。
迴圈展開可用於增加FPGA裝置中大規模計算資源的利用率。在給定陣列上迴圈維度的不同迴圈迭代之間的資料共享關係可分為三類:不相干,獨立,有依賴關係。對應如圖3所示。如程式碼2所示,CNN程式碼中的資料共享關係如表1所示。
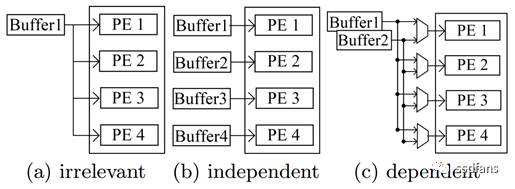
圖3
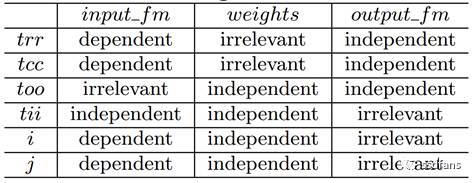
表1
因此在設計展開時,選擇對too和tii進行展開,以避免所有陣列的複雜連線拓撲。too和tii被置換到最內層迴圈,以簡化HLS程式碼生成。生成的硬體實現如圖4所示。
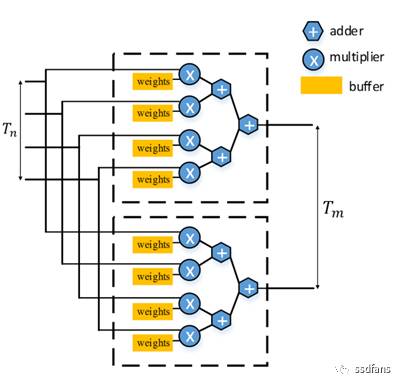
圖4
迴圈流水線化是高階合成中的關鍵優化技術,通過重複來自不同迴圈迭代的操作的執行來提高系統吞吐量。因此方案使用基於多面體的優化框架來執行自動迴圈變換以將並行迴圈水平置換到最內層,以避免迴圈依賴。
最終迴圈展開和迴圈流水線優化後的程式碼結構如程式碼3所示。

程式碼3
3)記憶體訪問優化的實現
程式碼4展示了一個CNN層的儲存器傳送操作。輸入/輸出特徵圖和權重在計算引擎啟動之前就已被載入,計算完成後,將生成的輸出特徵圖寫回主儲存器。

程式碼4
通過分析可知,通訊部分中的最內層迴圈(程式碼4中的ti)與陣列無關,因此在不同的迴圈迭代之間存在冗餘的儲存器操作。所以方案使用本地儲存提升來減少相關冗餘操作。程式碼4中,最內圈的維數ti與陣列輸出特徵圖無關。因此,可以將對陣列輸出特徵圖的訪問提升到外部迴圈。請注意,升級過程可以迭代執行,直到訪問周圍的最內層迴圈最終相關。通過本地儲存提升,陣列輸出特徵圖上的儲存訪問操作的行程計數從降到了 。
迴圈轉換資料重用。為了通過本地儲存提升最大化資料重用的機會,方案使用基於多面體的優化框架來識別所有合法的迴圈轉換。表2顯示了迴圈迭代和陣列之間的資料共享關係。每個合法迴圈排程中都會使用本地儲存提升功能,以減少總通訊量。

表2
通過上述操作,方案明顯提升了CTC Ratio。
4)設計空間探索
以CNN模型的第5層為例,圖5描繪了CNN模型的第5層在rooline模型座標系中的所有合理的解決方案。橫軸表示CCT Ratio,縱軸表示計算效能(GFLOPS)。任何點與原點(0,0)之間的線的斜率表示該實現的最小頻寬要求。
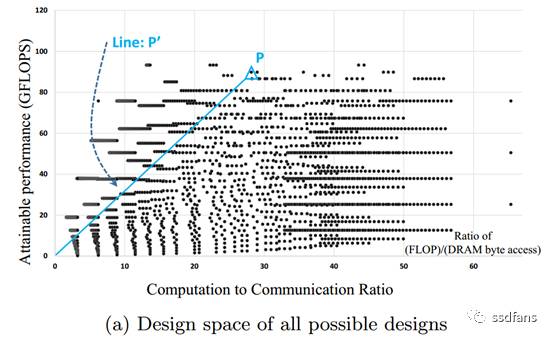
圖5
圖6中,頻寬Roof和計算Roof的線由平臺的規格定義。頻寬Roof線的左側的任何一點都需要比平臺提供的頻寬更高的頻寬。例如,儘管圖中A方案實現了最高的計算效能,但是目標平臺無法滿足該方案所需的儲存器頻寬。所以,綜合分析比較,最終選擇方案C作為第5層的設計方案,它的頻寬要求為2.2GB/s。
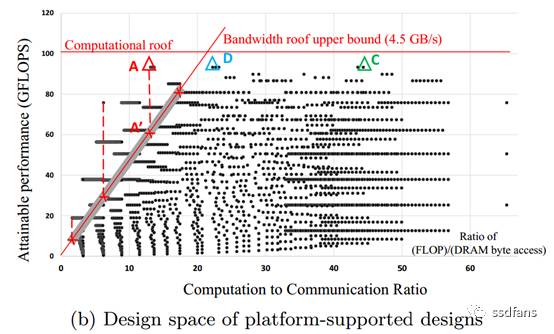
圖6
5)多層CNN加速器設計
在此之前,我們討論瞭如何找到每個卷積層的最優實現方案。但是,在CNN應用中,這些引數可能在不同的層之間需要變化。表3描述了該應用CNN模型中所有層的最優展開因子(Tm和Tn)。為了解決這個問題,本方案採用的方法是在不同卷積層之間設計具有均勻展開因子的硬體架構。具有統一展開因子的CNN加速器設計和實現簡單,但可能對某些層是次優的。表3顯示,使用統一展開因子<64,7>,與每個優化卷積層的總執行週期相比,退化在5%以內。因此,方案選擇了CNN加速器在卷積層上的統一展開因子。
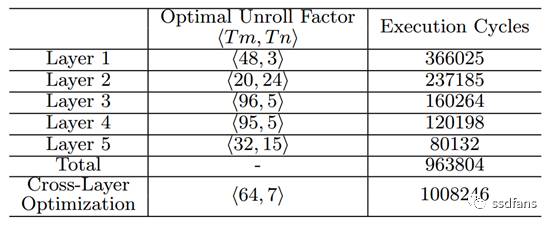
表3
解決完上述問題,圖7就是整個實現方案架構。實驗是在具有Xilinx FPGA晶片Virtex7 485t的VC707板上完成。其工作頻率為100 MHz。 為了比較效能,CPU軟體實現在具有15MB快取記憶體的Intel Xeon CPU E5-2430(@ 2.20GHz)上執行。
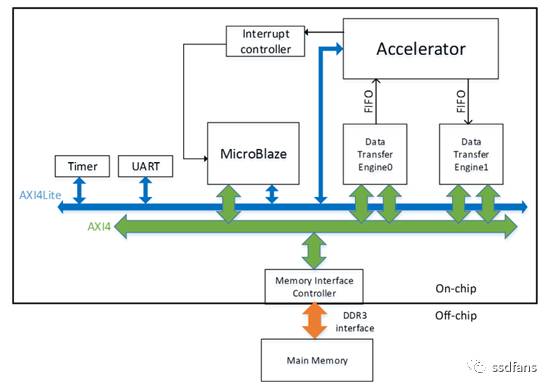
圖7
該實驗的資源利用情況如表4所示。
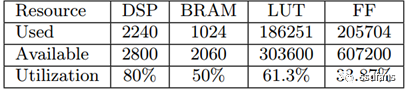
表4
加速器的效能比較如表5所示。
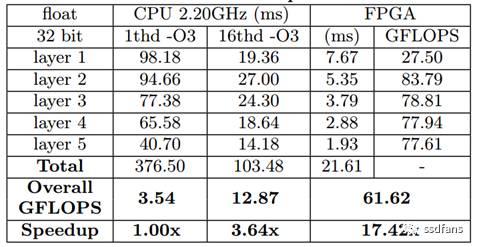
表5
表6顯示,CPU軟體實現和FPGA實現之間的消耗能量的比例至少為24.6x。 FPGA實現使用的能量遠遠低於其CPU實現。
表6
同時,如表7所示,如果使用定點計算引擎,該設計方案可以實現更好的效能和效能密度,因為定點處理元件使用的資源少得多。
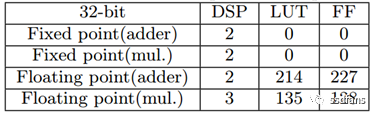
表7
參考文獻:
[1] Zhang C, Li P, Sun G, et al. Optimizing fpga-based accelerator design for deep convolutional neural networks[C] Proceedings of the 2015 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays. ACM, 2015: 161-170.