
FPGA實現深度學習的優勢及缺點
計算能力一般通過兩個引數表徵:
- Peak GOPs峰值效能
- Real GOPs實測效能(針對特定網路)
FPGA在推理過程,可以做到高的Real GOPs/Peak GOPs,而訓練過程,他的結構與演算法並不完全匹配。希望後面出的器件可以克服。
- FPGA的算力優勢
- 推理時的低延遲,特別時batch size為1時,這個在微軟Brainwave Project專案中中反覆提到。
GPU的優勢是塊處理,批量資料進,批量計算,這樣可以利用他的海量計算單元,以及外部儲存。但推理時batch size為1的運算,FPGA的流水線設計優勢明顯。
- 定製化計算引擎
陣列式、可重構的資料流引擎(權重、資料流入、計算合理配合),配合大量分散式RAM的設計,可以讓FPGA適配特定的神經網路,針對應用場景的Real GOPs/Peak GOPs比率高。
這個我想就是FPGA宣稱功耗比GPU做的更低的原因。
另外在優化做到極致情況下,某些神經網路中FPGA的Real Gops確實有可能超過GPU
- 持續演進的軟硬體融合
通過演算法優化壓縮網路、壓縮權重、配合適配的NPU結構,更小的計算量達到接近的精度。
- FPGA算力缺點
FPGA不適合做訓練,這個主要是訓練過程反向傳播的演算法特點導致,主要表現在3個方面:
- 不適合浮點運算,而訓練過程,基本上都是浮點運算。
我們以反向傳播過程的計算為例,流行的梯度優化演算法ADAM公式如下:

從上面公式可知,收斂過程,需要無數次的迭代計算,這一過程這些引數的改變數是極小的,而FPGA內部的運算單元主要是DSP(沒有浮點單元),適合定點計算,
而推理過程權重已經訓練完成,這時是針對每個引數做精度壓縮,不存在誤差逐級傳播,只要最後計算結果與原始精度相比下降程度在可接受範圍內就可以。
- 訓練過程需要計算種類多,FPGA實現某些運算代價大。
訓練過程中間節點的normalize,ADAM中的開根號運算等。
如果僅把正向傳播的乘加運算放在FPGA中,反向梯度計算放在CPU中,每次迭代時將導致大量的引數以及中間計算結果Activation在CPU和FPGA之間反覆傳遞,從而抵消硬體加速獲得的好處。
- 演算法的反向傳播過程的中間結果以及權重相對正向過程需要轉置。
正向傳播與反向傳播的計算對比如下:
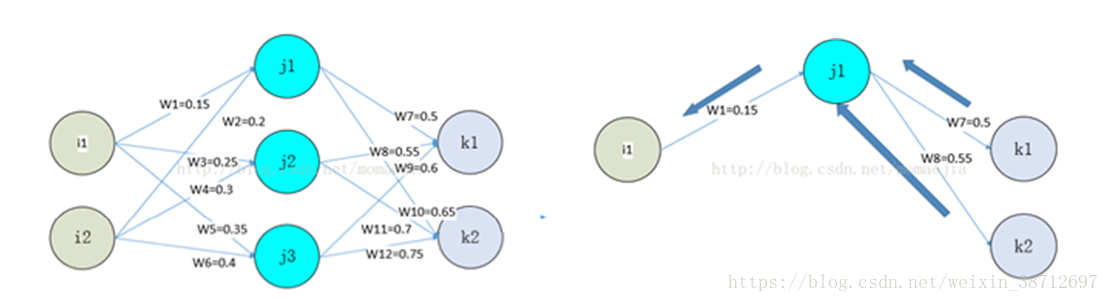
以最簡單的反向傳播計算公式來看:
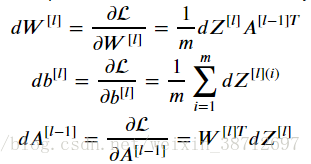
A對應途中j1,j2,j3的中間計算結果,在反向計算dW時,需要對正向計算的A做一次轉置,計算dA(l-1)時,需要對權重W做一次轉置。
多層神經網路時我們把權重快取和中間的activation快取看作一個二維陣列,正向時相當於按行讀取,反向時因為轉置,需要按列讀取。
對應的RAM操作:正向過程利用了FPGA分散式RAM優點,一次讀取出大量資料進行計算,而反向時的每次運算,由於轉置,引數和中間結果集中到某幾片RAM上。從而無法利用FPGA分散式RAM的高頻寬優點,而FPGA的主頻與CPU、GPU相比有差距,因此訓練上RAM反而成為劣勢,示意圖如下:

因此,反向傳播想做到高效能,要不需要在原生演算法上做改進,要不硬體上需要找到一種二維陣列的快速訪問方法。