
DQN解決cartpole原理
標籤(): 機器學習
文章目錄
當學習狀態空間很大,例如圍棋的學習中,由於狀態空間過大導致Q表遠遠超過記憶體,所以在複雜學習情況下Q表更新並不適用。
取而代之的是用神經網路當做Q表使用,第一種神經網路是輸入狀態和動作,輸出動作的評價值,第二種神經網路是輸入狀態輸出所有動作和該動作的評價值,再從中選取評價高的動作進行決策。
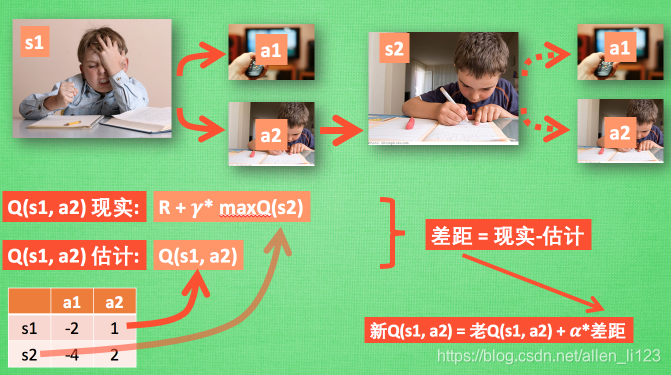
演算法更新:
為什麼需要DQN
一般的強化學習例如Q學習相當於不斷進行模擬獲取資料並從表中尋找最優解進行選取,但是現實情況中例如連續控制問題狀態空間是無限的,所以一般的Q學習並不能滿足問題的求解
一方面神經網路能擬合引數,能夠自主學習資料,但是極其依賴資料集
另一方面,強化學習不能擬合引數,能夠自主模擬,資料集由模擬所得
所以在沒有資料集的情況又需要資料集進行擬合的問題上應當選用深度強化學習
DQN與Q學習?
在引入DQN之前我們看一個DQN解決的一個連續控制的問題。(後附程式碼)
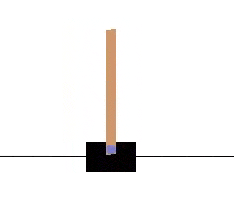
我們通過控制小車向左向右移動,使棒子始終保持豎立狀態
通過對gym環境的查詢,我們知道該遊戲有四個資訊,但是我們並不知道資訊所代表的含義
我們的輸入有兩種,向左或者向右
基於以上資訊建立一種輸入使棍子始終保持平衡
在此,我們使用深度強化學習中的DQN解決此問題
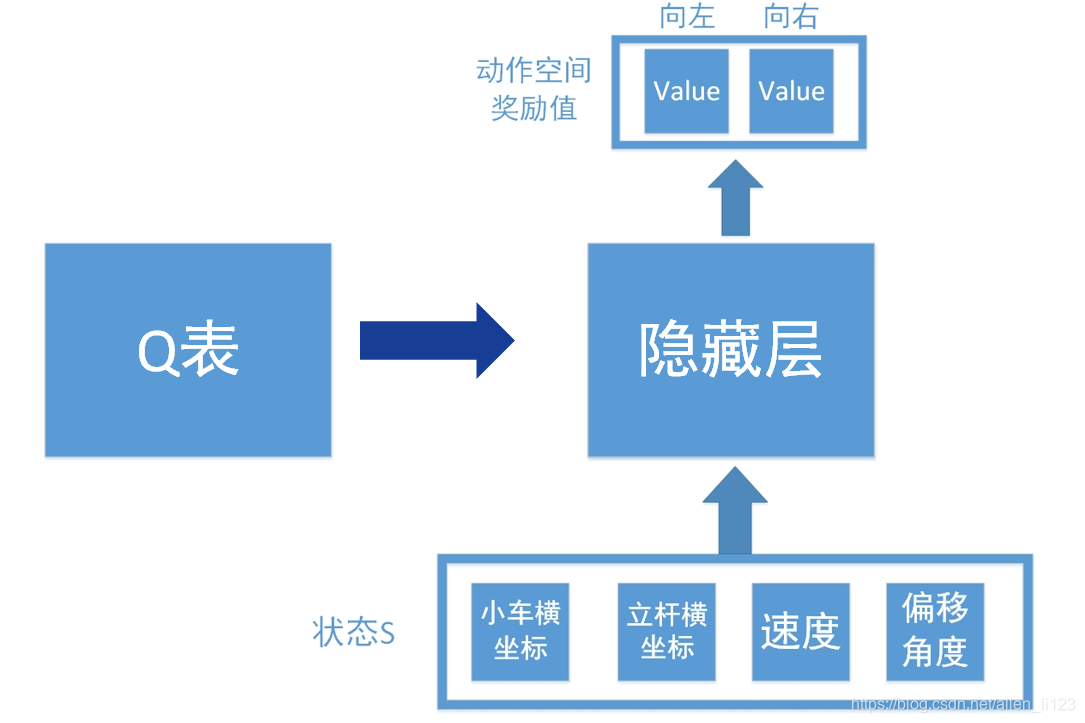
假設我們如果使用Q學習解決此類問題,則結構圖如下
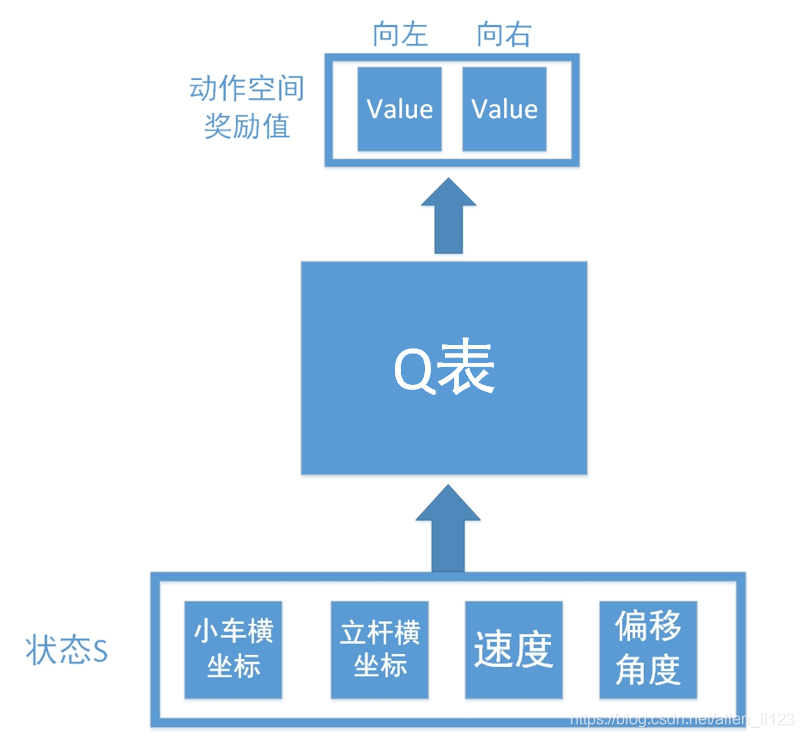
輸入為環境反饋的四個資訊,輸出為向左向右查詢得到的數值。但是正如之前說的,連續控制存在無限可能,如果不能擬合數據很難學出效果,所以我們加入了神經網路如下:
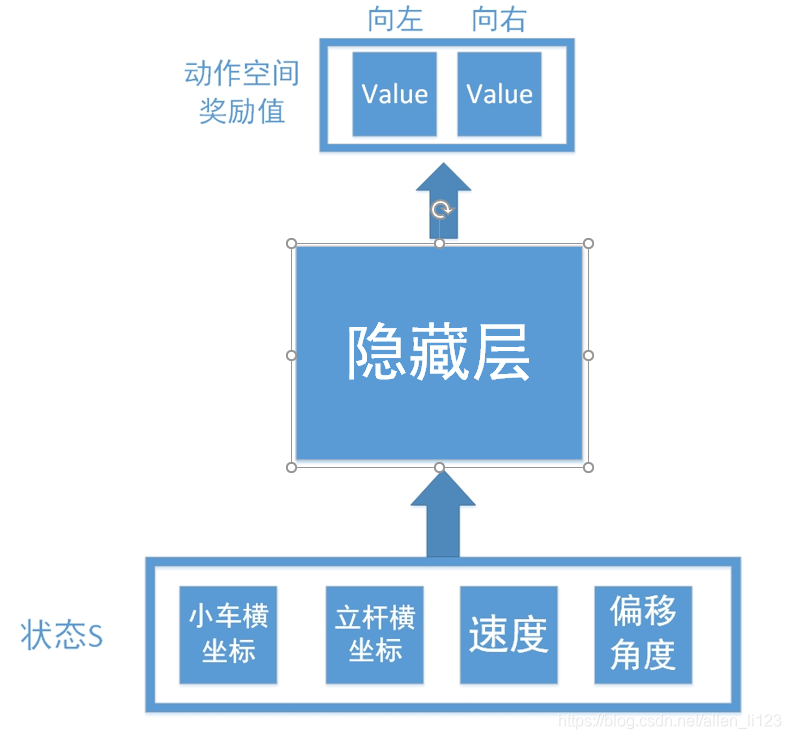
將Q表換為隱藏層,這樣就相當於一個輸入層為4個節點,輸出層為2個節點的神經網路。
將獲得的資料放入神經網路進行擬合而不是放入Q表儲存就是DQN與Q學習的不同之處
此外為了消除資料集之間的關聯性以及提高資料集的利用效率,需要將模擬資料放入Q表中,在每次擬合時隨機抽取一個batch進行擬合。
另外在改進的DQN中,Q表也是用神經網路進行儲存,在一定時間後,右側所訓練的神經網路完全賦值給與左側神經網路實現資料更新
DQN演算法更新

