
異常檢測LOF
區域性異常因子演算法-Local Outlier Factor(LOF)
在資料探勘方面,經常需要在做特徵工程和模型訓練之前對資料進行清洗,剔除無效資料和異常資料。異常檢測也是資料探勘的一個方向,用於反作弊、偽基站、金融詐騙等領域。
異常檢測方法,針對不同的資料形式,有不同的實現方法。常用的有基於分佈的方法,在上、下α分位點之外的值認為是異常值(例如圖1),對於屬性值常用此類方法。基於距離的方法,適用於二維或高維座標體系內異常點的判別,例如二維平面座標或經緯度空間座標下異常點識別,可用此類方法。 
這次要介紹一下一種基於密度的異常檢測演算法,區域性異常因子LOF演算法(Local Outlier Factor)
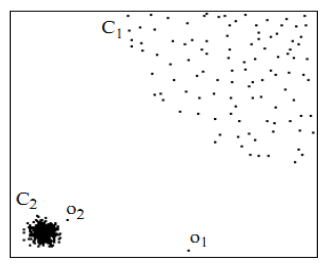
用視覺直觀的感受一下,如圖2,對於C1集合的點,整體間距,密度,分散情況較為均勻一致,可以認為是同一簇;對於C2集合的點,同樣可認為是一簇。o1、o2點相對孤立,可以認為是異常點或離散點。現在的問題是,如何實現演算法的通用性,可以滿足C1和C2這種密度分散情況迥異的集合的異常點識別。LOF可以實現我們的目標。
下面介紹LOF演算法的相關定義:
1) d(p,o):兩點p和o之間的距離。
2) k-distance:第k距離
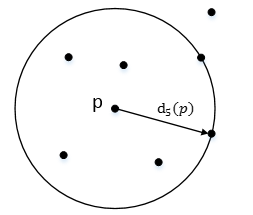
對於點p的第k距離dk(p)定義如下:
dk(p)=d(p,o),並且滿足:
a) 在集合中至少有不包括p在內的k個點o' ∈ C{x ≠ p}, 滿足d(p,o') ≤ d(p,o) 。
b) 在集合中最多有不包括p在內的k−1個點o' ∈ C{x ≠ p},滿足d(p,o') < d(p,o)。
如下圖,離p第5遠的點在以p為圓心,d5(p)為半徑的
點p的第k距離鄰域Nk(p),就是p的第k距離即以內的所有點,包括第k距離。
因此p的第k鄰域點的個數 |Nk(p)| ≥ k。
4) reach-distance:可達距離
點o到點p的第k可達距離定義為:reach−distancek(p,o) = max{dk(o), d(p,o)}
也就是,點o到點p的第k可達距離,至少是o的第k距離,或者為o、p間的真實距離。
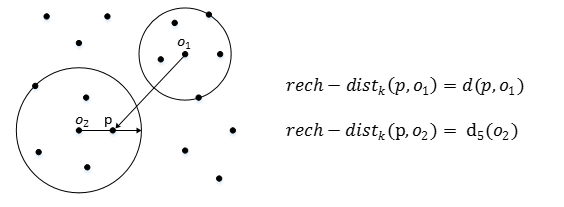
5) local reachability density:區域性可達密度
點p的區域性可達密度表示為: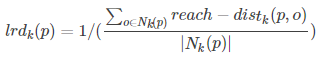 表示點p的第k鄰域內的點到p的平均可達距離的倒數。
表示點p的第k鄰域內的點到p的平均可達距離的倒數。
6) local outlier factor:區域性離群因子
點p的區域性離群因子表示為:
表示點p的鄰域點Nk(p)的區域性可達密度與點p的區域性可達密度之比的平均數。
local outlier factor越接近1,說明p的其鄰域點密度差不多,p可能和鄰域同屬一簇;
local outlier factor越小於1,說明p的密度高於其鄰域點密度,p為密集點;
local outlier factor越大於1,說明p的密度小於其鄰域點密度,p越可能是異常點。
因為LOF對密度的是通過點的第k鄰域來計算,而不是全域性計算,因此得名為“區域性”異常因子,這樣,對於圖1的兩種資料集C1和C2,LOF完全可以正確處理,而不會因為資料密度分散情況不同而錯誤的將正常點判定為異常點。
轉自:https://blog.csdn.net/wangyibo0201/article/details/51705966