
機器學習第四篇
全文搜尋引擎允許人們在大量文件中搜索一系列單詞,並根據文件與這些單詞的相關程度對結果進行排序。
PageRank——標準演算法的一個變體
資訊檢索步驟:
1、找到一種蒐集文件的方法
爬蟲:接受一組等待建立索引的網頁,再根據這些網頁內部的連結進而找到其他的網頁,依此類推。程式碼通常會將網頁下載下來,對網頁進行解析,找出所有指向後續檢索網頁的連結
urllib
import urllib.request c=urllib.request.urlopen('https://www.zhihu.com/question/27621722') contents=c.read() print(contents)
2、建立索引(入表入庫)
SQLite——嵌入式資料庫
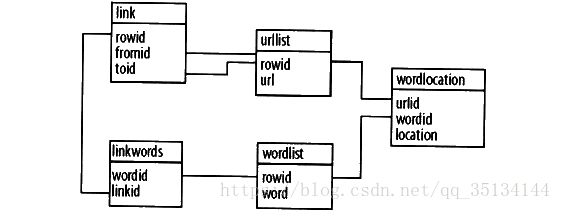
3、通過查詢返回一個經過排序的文件列表 排序方式
searchengine.py:
#包含兩個類:一個用於檢索網頁和建立資料庫(crawler);另一個則通過查詢資料庫進行全文搜尋(searcher)
import urllib.request import urllib.parse from bs4 import BeautifulSoup import sqlite3 import re ignorewords = set(['the', 'of', 'to', 'and', 'a', 'in', 'is', 'it'])
class crawler: # 初始化crawler類並傳入資料庫名稱 def __init__(self, dbname): self.con = sqlite3.connect(dbname) def __del__(self): self.con.close() def dbcommit(self): self.con.commit() # 輔助函式,用於獲取條目的id, # 並且如果條目不存在,就將其加入資料庫中 def getentryid(self, table, field, value, createnew=True): cur = self.con.execute( "select rowid from %s where %s='%s'" % (table, field, value)) res = cur.fetchone() if res == None: cur = self.con.execute( "insert into %s (%s) values ('%s') " % (table, field, value)) return cur.lastrowid else: return res[0] # 為每個網頁建立索引 def addtoindex(self, url, soup): if self.isindexed(url): return print('Indexing %s' % url) # 獲取每個單詞 text = self.gettextonly(soup) words = self.separatewords(text) # 得到URL的ID urlid = self.getentryid('urllist', 'url', url) # 將每個單詞與該URL關聯 for i in range(len(words)): word = words[i] if word in ignorewords: continue wordid = self.getentryid('wordlist', 'word', word) self.con.execute("insert into wordlocation(urlid,wordid,location)\ values (%d,%d,%d)" % (urlid, wordid, i)) # 從一個HTML網頁中提取文字 def gettextonly(self, soup): # print(soup.string) v = soup.string if v == None: c = soup.contents # print(soup.contents) resulttext = '' for t in c: subtext = self.gettextonly(t) resulttext += subtext + '\n' return resulttext else: return v.strip() # 根據任何非空白字元進行分調處理,將任何非字母非數字字元都看作分隔符 def separatewords(self, text): splitter = re.compile('\\W*') return [s.lower() for s in splitter.split(text) if s != ''] # 如果URL已經建立索引,則返回true def isindexed(self, url): u = self.con.execute \ ("select rowid from urllist where url='%s'" % url).fetchone() if u != None: # 檢查它是否已經被檢索過了 v = self.con.execute( 'select * from wordlocation where urlid=%d' % u[0]).fetchone() if v != None: return True return False # 新增一個關聯兩個網頁的連結 def addlinkref(self, urlFrom, urlTo, linkText): pass # 從一小組網頁開始進行廣度優先搜尋,直至某一給定深度 # 期間為網頁建立索引 def crawl(self, pages, depth=2): for i in range(depth): newpages = set() for page in pages: try: c = urllib.request.urlopen(page) except: print('Could not open %s' % page) continue soup = BeautifulSoup(c.read()) self.addtoindex(page, soup) links = soup('a') for link in links: if 'href' in dict(link.attrs): url = urllib.request.urljoin(page, link['href']) # ???? # print(url) if url.find("'") != -1: continue url = url.split('#')[0] if url[0:4] == 'http' and not self.isindexed(url): newpages.add(url) linkText = self.gettextonly(link) self.addlinkref(page, url, linkText) self.dbcommit() pages = newpages # 建立資料庫表 def createindextables(self): self.con.execute('create table urllist(url)') self.con.execute('create table wordlist(word)') self.con.execute('create table wordlocation(urlid,wordid,location)') self.con.execute('create table link(fromid integer,toid integer)') self.con.execute('create table linkwords(wordid,linkid)') self.con.execute('create index wordidx on wordlist(word)') self.con.execute('create index urlidx on urllist(url)') self.con.execute('create index wordurlidx on wordlocation(wordid)') self.con.execute('create index urltoidx on link(toid)') self.con.execute('create index urlfromidx on link(fromid)') self.dbcommit()
pages = ['http://blog.sina.com.cn/s/blog_864244030102x443.html']
cc = crawler('SSSe.db')
# cc.createindextables()
#cc.crawl(pages)
print([row for row in cc.con.execute('select * from wordlocation where wordid=3')])目前的程式碼一次只能處理一個單詞,而且只能以文件當初被載入的順序返回
searcher:
class searcher:
def __init__(self, dbname):
self.con = sqlite3.connect(dbname)
def __del__(self):
self.con.close()
def getmatchrows(self, q):
# 構造查詢的字串
fieldlist = 'w0.urlid' #***************************
tablelist = ''
clauselist = ''
wordids = []
# 根據空格拆分單詞
words = q.split(' ')
tablenumber = 0
for word in words:
# 獲取單詞的ID
wordrow = self.con.execute(
"select rowid from wordlist where word='%s'" % word).fetchone()
if wordrow != None:
wordid = wordrow[0]
wordids.append(wordid)
if tablenumber > 0:
tablelist += ','
clauselist += ' and '
clauselist += 'w%d.urlid=w%d.urlid and ' % (tablenumber - 1, tablenumber)
fieldlist += ',w%d.location' % tablenumber
tablelist += 'wordlocation w%d' % tablenumber
clauselist += 'w%d.wordid=%d' % (tablenumber, wordid)
tablenumber += 1
# 根據各個組分,建立查詢
fullquery = 'select %s from %s where %s' % (fieldlist, tablelist, clauselist)
cur = self.con.execute(fullquery)
rows = [row for row in cur]
print(rows)
print(wordids)
return rows, wordidse=searcher('SSSe.db')
print(e.getmatchrows('float style'))根據單詞位置的不同組合,每個URL ID會返回多次。
對搜尋結果進行排名:
基於內容的排名:利用某些可行的度量方式來對查詢結果進行判斷
def getscoredlist(self, rows, wordids):
totalscores = dict(([row[0], 0]) for row in rows)
# 此處是稍後放置評價函式的地方
weights = []
for (weight, scores) in weights:
for url in totalscores:
totalscores[url] += weight * scores[url]
return totalscores
def geturlname(self, id):
return self.con.execute(
'select url from urllist where rowid=%d' % id).fetchone()[0]
def query(self, q):
rows, wordids = self.getmatchrows(q)
scores = self.getscoredlist(rows,wordids)
rankedscores = sorted([(score, url) for (url, score) in scores.items()], reverse=1)
for (score, urlid) in rankedscores[0:10]:
print('%f\t%s' % (score, self.geturlname(urlid)))
#歸一化函式
def normalizescores(self,scores,smallsBetter=0):
vsmall=0.00001
if smallsBetter:
minscore=min(scores.values())
return dict([(u,float(minscore)/max(vsmall,l)) for (u,l)\
in scores.items()])
else:
maxscore=max(scores.values())
if maxscore==0:maxscore=vsmall
return dict([(u,float(c)/maxscore) for (u,c) in scores.items()])
單詞頻度:
def frequencyscore(self,rows):
counts=dict([(row[0],0) for row in rows])
for row in rows:
counts[row[0]]+=1
return self.normalizescores(counts)大多數搜尋引擎都不會將評價結果告訴終端使用者,但是對某些應用而言,這些評價值可能會非常有用,例如,也許我們希望在結果超出某個閾值的時候,直接向用戶返回排名最靠前的內容,或者希望根據返回結果的相關程度,按一定比例的字型大小加以顯示
文件位置:
def locationscore(self, rows):
locations = dict([(row[0], 1000000) for row in rows])
for row in rows:
loc = sum(row[1:])
if loc < locations[row[0]]: locations[row[0]] = loc
return self.normalizescores(locations, smallsBetter=1)
單詞距離:
def distancescore(self,rows):
#如果僅有一個單詞,則得分都一樣
if len(rows[0])<=2:
return dict([(row[0],1.0) for row in rows])
#初始化字典,並填入一個很大的數
mindistance=dict([(row[0],1000000) for row in rows])
for row in rows:
dist=sum([abs(row[i]-row[i-1]) for i in range(2,len(row))])
if dist<mindistance[row[0]]:
mindistance[row[0]]=dist
return self.normalizescores(mindistance,smallsBetter=1)
評價函式:
weights = [(1.0, self.frequencyscore(rows)),
(1.0, self.locationscore(rows)),
(1.0,self.distancescore(rows))]
外部回指連結排名:
def inboundlinkscore(self, rows):
uniqueurls = set([row[0] for row in rows])
inboundcount = dict([(u, self.con.execute( \
'select count(*) from link where toid=%d' % u).fetchone()[0]) \
for u in uniqueurls])
return self.normalizescores(inboundcount)PageRank:
該演算法為每個網頁都賦予了一個指示網頁重要程度的評價值。網頁的重要性是依據指向該網頁的所有其他網頁的重要性,以及這些網頁中所包含的連結數求得的
如果某個網頁擁有來自其他熱門網頁的外部回指連結越多,人們無意間到達該網頁的可能性就越大。若使用者始終不停的點選,那麼終將到達每一個網頁。但是大多數人在瀏覽一段時間之後都會停止點選,pagerank使用了一個值為0.85的阻尼因子,用以指示使用者持續點選每個網頁連結的概率為85%。
def calculatepagerank(self, iterations=20):
# 清除當前的PageRank表
self.con.execute('drop table if exists pagerank')
self.con.execute('create table pagerank(urlid primary key,score)')
# !!!!!!!!!!!!!!!初始化每個url,令其PageRank值為1!!!!!!!!!!!!get!
self.con.execute('insert into pagerank select rowid,1.0 from urllist')
self.dbcommit()
# 求每一個url 的PageRank值
for i in range(iterations):
print('Iteration %d ' % i)
for (urlid,) in self.con.execute('select rowid from urllist'):
pr = 0.15
# 迴圈遍歷指向當前網頁的所有其他網頁
for (linker,) in self.con.execute(
'select distinct fromid from link where toid=%d' % urlid):
# 得到連結源對應網頁的PageRank值
linkingpr = self.con.execute(
'select score from pagerank where urlid=%d' % linker).fetchone()[0]
# 根據連結源,求得總的連結數
linkingcount = self.con.execute(
'select count(*) from link where fromid=%d' % linker).fetchone()[0]
pr += 0.85 * (linkingpr / linkingcount)
self.con.execute(
'update pagerank set score=%f where urlid=%d' % (pr, urlid))
self.dbcommit()# 歸一化處理
def pagerankscore(self, rows):
pageranks = dict([(row[0], self.con.execute(
'select score from pagerank where urlid=%d' % row[0]).fetchone()[0]) for row in rows])
maxrank = max(pageranks.values())
normalizedscores = dict([u, float(1) / maxrank] for (u, l) in pageranks.items())
return normalizedscores對於返回更高層次和更大眾化的網頁而言,PageRank是一種有效的度量方法。
利用連結文字:
#連結文字
def linktextscore(self, rows, wordids):
linkscores = dict([(row[0], 0) for row in rows])
for wordid in wordids:
cur = self.con.execute(
'select link.fromid,link.toid from linkwords,link where wordid=%d and linkwords.linkid=link.rowid' % wordid)
for (fromid, toid) in cur:
if toid in linkscores:
pr = self.con.execute('select score from pagerank where urlid=%d' % fromid).fetchone()[0]
linkscores[toid] += pr
maxscore = max(linkscores.values())
normalizedscores = dict([(u, float(l) / maxscore) for (u, l) in linkscores.items()])
return normalizedscores神經網路:考查人們在搜尋時對搜尋結果的實際點選情況,逐步改善搜尋排名