
Faster R-CNN論文詳解
廢話不多說,上車吧,少年
&創新點
設計Region Proposal Networks【RPN】,利用CNN卷積操作後的特徵圖生成region proposals,代替了Selective Search、EdgeBoxes等方法,速度上提升明顯;
訓練Region Proposal Networks與檢測網路【Fast R-CNN】共享卷積層,大幅提高網路的檢測速度。
&問題是什麼
繼Fast R-CNN後,在CPU上實現的區域建議演算法Selective Search【2s/image】、EdgeBoxes【0.2s/image】等成了物體檢測速度提升上的最大瓶頸。
&如何解決問題
。測試過程
Faster R-CNN統一的網路結構如下圖所示,可以簡單看作RPN網路+Fast R-CNN網路。
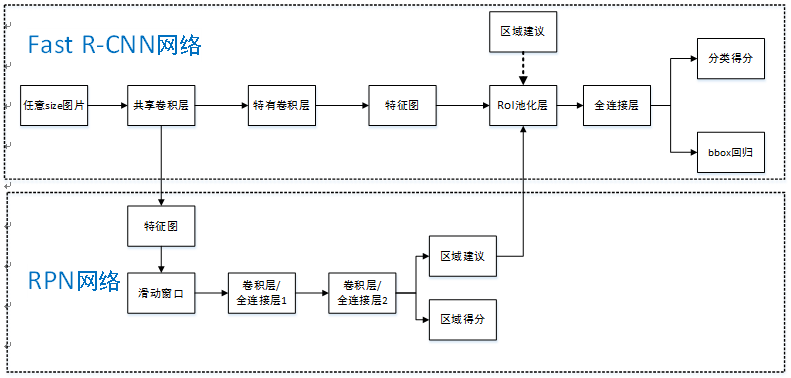
注意:上圖Fast R-CNN中含特有卷積層,博主認為不是所有卷積層都參與共享。
首先向CNN網路【ZF或VGG-16】輸入任意大小圖片;
經過CNN網路前向傳播至最後共享的卷積層,一方面得到供RPN網路輸入的特徵圖,另一方面繼續前向傳播至特有卷積層,產生更高維特徵圖;
供RPN網路輸入的特徵圖經過RPN網路得到區域建議和區域得分,並對區域得分採用非極大值抑制【閾值為0.7】,輸出其Top-N【文中為300
】得分的區域建議給RoI池化層;第2步得到的高維特徵圖和第3步輸出的區域建議同時輸入RoI池化層,提取對應區域建議的特徵;
第4步得到的區域建議特徵通過全連線層後,輸出該區域的分類得分以及迴歸後的bounding-box。
。解釋分析
RPN網路結構是什麼?實現什麼功能?具體如何實現?
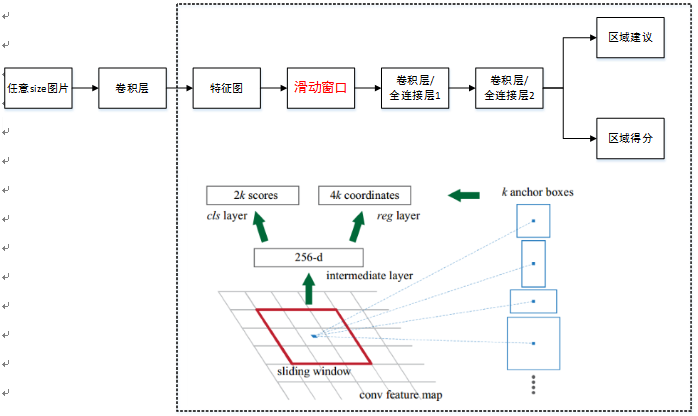
單個RPN網路結構如下圖:
注意:上圖中卷積層/全連線層表示卷積層或者全連線層,作者在論文中表示這兩層實際上是全連線層,但是網路在所有滑窗位置共享全連線層,可以很自然地用n×n卷積核【論文中設計為3×3】跟隨兩個並行的1×1卷積核實現,文中這麼解釋的,博主並不是很懂,尷尬。功能:實現attention
機制,如圖所示,RPN在CNN卷積層後增加滑動視窗操作以及兩個卷積層完成區域建議功能,第一個卷積層將特徵圖每個滑窗位置編碼成一個特徵向量,第二個卷積層對應每個滑窗位置輸出k個區域得分和k個迴歸後的區域建議,並對得分割槽域進行非極大值抑制後輸出得分Top-N【文中為300】區域,告訴檢測網路應該注意哪些區域,本質上實現了Selective Search、EdgeBoxes等方法的功能。具體實現:
①首先套用ImageNet上常用的影象分類網路,本文中試驗了兩種網路:ZF或VGG-16,利用這兩種網路的部分卷積層產生原始影象的特徵圖;② 對於①中特徵圖,用n×n【論文中設計為3×3,n=3看起來很小,但是要考慮到這是非常高層的feature map,其size本身也沒有多大,因此9個矩形中,每個矩形窗框都是可以感知到很大範圍的】的滑動視窗在特徵圖上滑動掃描【代替了從原始圖滑窗獲取特徵】,每個滑窗位置通過卷積層1對映到一個低維的特徵向量【ZF網路:256維;VGG-16網路:512維,低維是相對於特徵圖大小W×H,typically~60×40=2400】後採用ReLU,併為每個滑窗位置考慮k種【論文中k=9】可能的參考視窗【論文中稱為anchors,見下解釋】,這就意味著每個滑窗位置會同時預測最多9個區域建議【超出邊界的不考慮】,對於一個W×H的特徵圖,就會產生W×H×k個區域建議;
③步驟②中的低維特徵向量輸入兩個並行連線的卷積層2:reg視窗迴歸層【位置精修】和cls視窗分類層,分別用於迴歸區域建議產生bounding-box【超出影象邊界的裁剪到影象邊緣位置】和對區域建議是否為前景或背景打分,這裡由於每個滑窗位置產生k個區域建議,所以reg層有4k個輸出來編碼【平移縮放參數】k個區域建議的座標,cls層有2k個得分估計k個區域建議為前景或者背景的概率
Anchors是什麼?有什麼用?
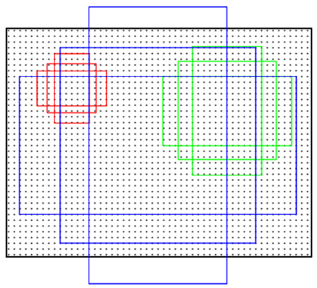
Anchors是一組大小固定的參考視窗:三種尺度{128^2,256^2,512^2}×三種長寬比{1:1,1:2,2:1},如下圖所示,表示RPN網路中對特徵圖滑窗時每個滑窗位置所對應的原圖區域中9種可能的大小,相當於模板,對任意影象任意滑窗位置都是這9中模板。繼而根據影象大小計算滑窗中心點對應原圖區域的中心點,通過中心點和size就可以得到滑窗位置和原圖位置的對映關係,由此原圖位置並根據與Ground Truth重複率貼上正負標籤,讓RPN學習該Anchors是否有物體即可。
作者在文中表示採用Anchors這種方法具有平移不變性,就是說在影象中平移了物體,視窗建議也會跟著平移。同時這種方式也減少了整個模型的size,輸出層512×(4+2)×9=2.8×10^4個引數【512是前一層特徵維度,(4+2)×9是9個Anchors的前景背景得分和平移縮放參數】,而MultiBox有1536×(4+1)×800=6.1×10^6個引數,而較小的引數可以在小資料集上減少過擬合風險。當然,在RPN網路中我們只需要找到大致的地方,無論是位置還是尺寸,後面的工作都可以完成,這樣的話採用小網路進行簡單的學習【估計和猜差不多,反正有50%概率】,還不如用深度網路【還可以實現卷積共享】,固定尺度變化,固定長寬比變化,固定取樣方式來大致判斷是否是物體以及所對應的位置並降低任務複雜度。
Anchors為什麼考慮以上三種尺度和長寬比?
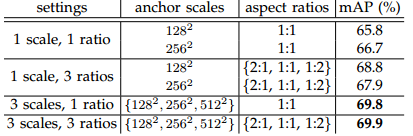
文中對Anchors的尺度以及長寬比選取進行了實驗,如下圖所示:
實驗實在VGG-16模型下,採用PASCAL VOC 2007訓練集和PASCAL VOC 2007測試集得到。相比於只採用單一尺度和長寬比,單尺度多長寬比和多尺度單長寬比都能提升mAP,表明多size的anchors可以提高mAP,作者在這裡選取了最高mAP的3種尺度和3種長寬比。如何處理多尺度多長寬比問題?即如何使24×24和1080×720的車輛同時在一個訓練好的網路中都能正確識別?
文中展示了兩種解決多尺度多長寬比問題:一種是使用影象金字塔,對伸縮到不同size的輸入影象進行特徵提取,雖然有效但是費時;
另一種是使用濾波器金字塔或者滑動視窗金字塔,對輸入影象採用不同size的濾波器分別進行卷積操作,這兩種方式都需要列舉影象或者濾波器size;
作者提出了一種叫Anchors金字塔的方法來解決多尺度多長寬比的問題,在RPN網路中對特徵圖滑窗時,對滑窗位置中心進行多尺度多長寬比的取樣,並對多尺度多長寬比的anchor boxes區域進行迴歸和分類,利用Anchors金字塔就僅僅依賴於單一尺度的影象和特徵圖和單一大小的卷積核,就可以解決多尺度多長寬比問題,這種對推薦區域取樣的模型不管是速度還是準確率都能取得很好的效能。同傳統滑窗方法提取區域建議方法相比,RPN網路有什麼優勢?
傳統方法是訓練一個能檢測物體的網路,然後對整張圖片進行滑窗判斷,由於無法判斷區域建議的尺度和長寬比,所以需要多次縮放,這樣找出一張圖片有物體的區域就會很慢;
雖然RPN網路也是用滑動視窗策略,但是滑動視窗實在卷積層特徵圖上進行的,維度較原始影象降低了很多倍【中間進行了多次max pooling 操作】,RPN採取了9種不同尺度不同長寬比的anchors,同時最後進行了bounding-box迴歸,即使是這9種anchors外的區域也能得到一個跟目標比較接近的區域建議。
。訓練過程
RPN網路預訓練
樣本 來源 正樣本 ILSVRC20XX 負樣本 ILSVRC20XX
樣本中只有類別標籤;
文中一帶而過RPN網路被ImageNet網路【ZF或VGG-16】進行了有監督預訓練,利用其訓練好的網路引數初始化;
用標準差0.01均值為0的高斯分佈對新增的層隨機初始化。Fast R-CNN網路預訓練
樣本 來源 正樣本 ILSVRC20XX 負樣本 ILSVRC20XX
樣本中只有類別標籤;
文中一帶而過Fast R-CNN網路被ImageNet網路【ZF或VGG-16】進行了有監督預訓練,利用其訓練好的網路引數初始化。RPN網路微調訓練
RPN網路樣本 來源 正樣本 與Ground Truth相交IoU最大的anchors【以防後一種方式下沒有正樣本】+與Ground Truth相交IoU>0.7的anchors 負樣本 與Ground Truth相交IoU<0.3的anchors
PASCAL VOC 資料集中既有物體類別標籤,也有物體位置標籤;
正樣本僅表示前景,負樣本僅表示背景;
迴歸操作僅針對正樣本進行;
訓練時棄用所有超出影象邊界的anchors,否則在訓練過程中會產生較大難以處理的修正誤差項,導致訓練過程無法收斂;
對去掉超出邊界後的anchors集採用非極大值抑制,最終一張圖有2000個anchors用於訓練【詳細見下】;
對於ZF網路微調所有層,對VGG-16網路僅微調conv3_1及conv3_1以上的層,以便節省記憶體。SGD mini-batch取樣方式:同Fast R-CNN網路,採取”image-centric”方式取樣,即採用層次取樣,先對影象取樣,再對anchors取樣,同一影象的anchors共享計算和記憶體。每個mini-batch包含從一張圖中隨機提取的256個anchors,正負樣本比例為1:1【當然可以對一張圖所有anchors進行優化,但由於負樣本過多最終模型會對正樣本預測準確率很低】來計算一個mini-batch的損失函式,如果一張圖中不夠128個正樣本,拿負樣本補湊齊。
訓練超引數選擇:在PASCAL VOC資料集上前60k次迭代學習率為0.001,後20k次迭代學習率為0.0001;動量設定為0.9,權重衰減設定為0.0005。
一張圖片多工目標函式【分類損失+迴歸損失】具體如下:
L({pi},{ti})=1Ncls∑iLcls(pi,p∗i)+λ1Nreg∑ip∗iLreg(ti,t∗i)
解釋說明:其中,i表示一個mini-batch中某個anchor的下標,
pi 表示anchor i預測為物體的概率;當anchor為正樣本時,p∗i=1 ,當anchor為負樣本時p∗i=0 ,由此可以看出迴歸損失項僅在anchor為正樣本情況下才被啟用;ti 表示正樣本anchor到預測區域的4個平移縮放參數【以anchor為基準的變換】;t∗i 表示正樣本anchor到Ground Truth的4個平移縮放參數【以anchor為基準的變換】;分類損失函式
Lcls 是一個二值【是物體或者不是物體】分類器,Lcls(pi,p∗i)=−log[p∗ipi+(1−p∗i)(1−pi)] ;歸回損失函式
Lreg(ti,t∗i)=R(ti−t∗i) 【兩種變換之差越小越好】,R函式定義如下:smoothL1(x)={0.5x2,|x|−0.5if |x|<1otherwise λ 引數用來權衡分類損失Lcls 和迴歸損失Lreg ,預設值λ=10 【文中實驗表明λ 從1變化到100對mAP影響不超過1%】;Ncls 和Nreg 分別用來標準化分類損失項Lcls 和迴歸損失項Lreg ,預設用mini-batch size=256設定Ncls ,用anchor位置數目~2400初始化相關推薦
Faster R-CNN論文詳解
廢話不多說,上車吧,少年 &創新點 設計Region Proposal Networks【RPN】,利用CNN卷積操作後的特徵圖生成region proposals,代替了Selective Search、EdgeBoxes等方法,速度上提
Faster R-CNN:詳解目標檢測的實現過程
最大的 中心 width 小數據 等等 eat tar 優先 博文 本文詳細解釋了 Faster R-CNN 的網絡架構和工作流,一步步帶領讀者理解目標檢測的工作原理,作者本人也提供了 Luminoth 實現,供大家參考。 Luminoth 實現:h
R-CNN論文詳解(學習筆記)
R-CNN:基於候選區域的目標檢測 Region proposals 基本概念(看論文前需要掌握的): 1.cnn(卷積神經網路):CNN從入門到精通(初學者) 2.Selective search:選擇性搜素 3.warp:圖形region變換 4.Supervised pre-t
R-CNN論文詳解
廢話不多說,上車吧,少年 &創新點 採用CNN網路提取影象特徵,從經驗驅動的人造特徵正規化HOG、SIFT到資料驅動的表示學習正規化,提高特徵對樣本的表示能力; 採用大樣本下有監督
Fast R-CNN論文詳解
廢話不多說,上車吧,少年 &創新點 規避R-CNN中冗餘的特徵提取操作,只對整張影象全區域進行一次特徵提取; 用RoI pooling層取代最後一層max pooling層,同時引入建議框資訊,提取相應建議框特徵; Fast R-CNN網路
Faster R-CNN網路的另一種優化思路:cascade R-CNN網路詳解
論文:Cascade R-CNN: Delving into High Quality Object Detection 論文地址:https://arxiv.org/pdf/1712.00726.pdf Github專案地址:https://github.com/zhaoweicai/
Faster R-CNN論文及原始碼解讀
R-CNN是目標檢測領域中十分經典的方法,相比於傳統的手工特徵,R-CNN將卷積神經網路引入,用於提取深度特徵,後接一個分類器判決搜尋區域是否包含目標及其置信度,取得了較為準確的檢測結果。Fast R-CNN和Faster R-CNN是R-CNN的升級版本,在準確率和實時性方面都得到了較大提升。在F
Faster R-CNN 論文學習
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks 演算法簡介 Abstract 1. Introduction 2. Relat
王權富貴論文篇:Faster R-CNN論文翻譯——中英文對照
文章作者:Tyan 感謝Tyan作者大大,相見恨晚,大家可以看原汁原味的Tyan部落格哦。 部落格:noahsnail.com | CSDN | 簡書 宣告:作者翻譯論文僅為學習,如有侵權請聯
R-CNN演算法詳解
這是一篇比較早的Object Detection演算法,發表在2014年的CVPR,也是R-CNN系列演算法的開山之作,網上可以搜到很多相關的部落格講解,本篇博文沒有按論文順序來講述,而是結合自己經驗來看這個演算法,希望給初學者一個直觀的感受,細節方面不需要太糾
Face Paper: R-FCN論文詳解
本篇部落格一方面介紹R-FCN演算法(NISP2016文章),該演算法改進了Faster RCNN,另一方面介紹其Caffe程式碼,這樣對演算法的認識會更加深入。要解決的問題:這篇論文提出一種基於region的object detection演算法:R-FCN(Region-
cascade R-CNN演算法詳解
cascade R-CNN演算法詳解 演算法背景 問題 解決方案 演算法介紹 演算法結構 邊界框迴歸 分類 檢測質量 級聯損失函式 實驗
Faster R-CNN論文翻譯——中文版
文章作者:Tyan 部落格:noahsnail.com | CSDN | 簡書 宣告:作者翻譯論文僅為學習,如有侵權請聯絡作者刪除博文,謝謝! Faster R-CNN: Towards Real-Time Object Detection w
faster R-CNN 論文閱讀
Faster R-CNN 論文閱讀 1. Introduction 目標檢測在region proposal 方法的推動下獲得了很大成功,SPP-Net和fast R-CNN使用共享卷積層加速了計算速度,目前在test階段的瓶頸在於region prop
深度學習 + 論文詳解: Fast R-CNN 原理與優勢
論文連結p.s. 鑑於斯坦福大學公開課裡面模糊的 R-CNN 描述,這邊決定精讀對應的論文並把心得和摘要記錄於此。前言在機器視覺領域的物體識別分支中,有兩個主要的兩大難題需要解決:目標圖片裡面含了幾種“物體”,幾個“物體”?該些物體分別坐落於圖片的哪個位置?而 R-CNN 的
例項分割模型Mask R-CNN詳解:從R-CNN,Fast R-CNN,Faster R-CNN再到Mask R-CNN
Mask R-CNN是ICCV 2017的best paper,彰顯了機器學習計算機視覺領域在2017年的最新成果。在機器學習2017年的最新發展中,單任務的網路結構已經逐漸不再引人矚目,取而代之
論文閱讀筆記(六)Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
采樣 分享 最終 產生 pre 運算 減少 att 我們 作者:Shaoqing Ren, Kaiming He, Ross Girshick, and Jian SunSPPnet、Fast R-CNN等目標檢測算法已經大幅降低了目標檢測網絡的運行時間。可是盡管如此,仍然
Faster R-CNN 英文論文翻譯筆記
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, Jian Sun reference link:ht
Faster R-CNN:利用區域提案網路實現實時目標檢測 論文翻譯
Faster R-CNN論文地址:Faster R-CNN Faster R-CNN專案地址:https://github.com/ShaoqingRen/faster_rcnn 摘要 目前最先進的目標檢測網路需要先用區域提案演算法推測目標位置,像SPPnet1和Fast R-CNN2
深度學習論文翻譯解析(四):Faster R-CNN: Down the rabbit hole of modern object detection
論文標題:Faster R-CNN: Down the rabbit hole of modern object detection 論文作者:Zhi Tian , Weilin Huang, Tong He , Pan He , and Yu Qiao 論文地址:https://tryolab