
深度學習論文翻譯解析(四):Faster R-CNN: Down the rabbit hole of modern object detection
論文標題:Faster R-CNN: Down the rabbit hole of modern object detection
論文作者:Zhi Tian , Weilin Huang, Tong He , Pan He , and Yu Qiao
論文地址:https://tryolabs.com/blog/2018/01/18/faster-r-cnn-down-the-rabbit-hole-of-modern-object-detection/
論文地址:
宣告:小編翻譯論文僅為學習,如有侵權請聯絡小編刪除博文,謝謝!
小編是一個機器學習初學者,打算認真研究論文,但是英文水平有限,所以論文翻譯中用到了Google,並自己逐句檢查過,但還是會有顯得晦澀的地方,如有語法/專業名詞翻譯錯誤,還請見諒,並歡迎及時指出。

在此之前,我們討論了目標檢測,關於它是什麼以及最近如何使用深度學習解決它。如果你還沒有閱讀之前的部落格,我們建議您先閱讀它,再來看這篇文章。
去年,我們打算去研究Fast R-CNN,閱讀原始論文和所有參考論文(等等),知道我們清楚地瞭解它是如何工作的以及如何去實現它。
我們最終在Luminoth中實施了Fast R-CNN,這是一個基於TensorFlow的計算機視覺工具包,可以輕鬆訓練,監控和使用這些型別的模型。到目前為止,Luminoth已經引起了我們極大的興趣,並且我們甚至在ODSC Eueope和ODSC West談到了它。
基於開發Luminoth的所有工作並基於我們所做的演示,我們認為最好有一篇博文,其中包含我們在研究中收集的所有細節和連結,作為未來的參考,任何人都對該主題感興趣。

背景
Faster R-CNN發表於NIPS 2015,其後出現了很多改進的版本,後面會進行介紹。正如我們在之前的部落格文章中提到的,Faster R-CNN是R-CNN論文的第三次迭代。其中Ross Girshick是作者兼合併者。
一切始於2014年的“ 用於精確物件檢測和語義分割的豐富特徵層次結構 ”(R-CNN),其使用稱為選擇性搜尋的演算法來提出可能的感興趣區域和用於分類和調整它們的標準卷積神經網路(CNN)。 。它迅速演變為2015年初發布的Fast R-CNN,其中一種名為Region of Interest Pooling的技術允許共享昂貴的計算並使模型更快。

網路結構
Faster R-CNN 的結構是複雜的,因為其有幾個移動部件. 這裡先對整體框架巨集觀介紹,然後再對每個部分的細節分析.
問題描述:
針對一張圖片,需要獲得的輸出有:
- 邊界框(bounding boxes) 列表;
- 每個邊界框的類別標籤;
- 每個邊界框和類別標籤的概率.
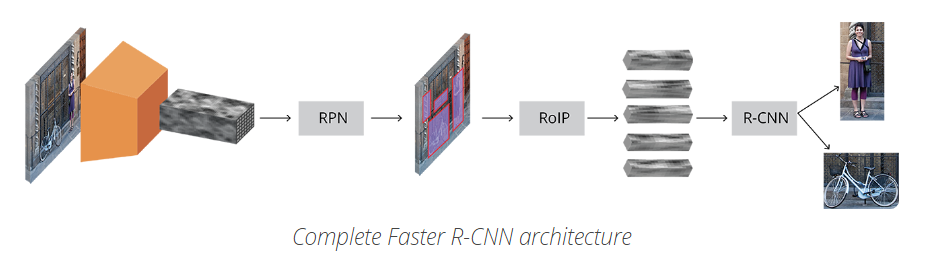

首先,輸入圖片表示為 Height×Width×DepthHeight×Width×Depth 的張量(多維陣列)形式,經過預訓練 CNN 模型的處理,得到卷積特徵圖(conv feature map). 即,將 CNN 作為特徵提取器,送入下一個部分。
這種技術在遷移學習(Transfer Learning)中比較普遍,尤其是,採用在大規模資料集訓練的網路權重,來對小規模資料集訓練分類器. 後面會詳細介紹。

然後,RPN(Region Propose Network) 對提取的卷積特徵圖進行處理. RPN 用於尋找可能包含 objects 的預定義數量的區域(regions,邊界框).
基於深度學習(DL)的目標檢測中,可能最難的問題就是生成長度不定(variable-length)的邊界框列表. 在構建深度神經網路時,最後的網路輸出一般是固定尺寸的張量輸出(採用RNN的除外). 例如,在圖片分類中,網路輸出是 (N,) 的張量,N是類別標籤數,張量的每個位置的標量值表示圖片是類別 labeli的概率值。

在 RPN 中,通過採用 anchors 來解決邊界框列表長度不定的問題,即,在原始影象中統一放置固定大小的參考邊界框. 不同於直接檢測 objects 的位置,這裡將問題轉化為兩部分:
對每一個 anchor 而言,
- anchor 是否包含相關的 object?
- 如何調整 anchor 以更好的擬合相關的 object。
這裡可能不容易理解,後面會深入介紹。

當獲得了可能的相關objects和其在原始影象中的對應位置之後,問題就更加直接了,採用CNN提取新的特徵和包含相關objects的邊界框,採用Rol Pooling處理,並提取相關object的特徵,得到了新的向量。
最後基於R-CNN模組,得到:
- 對邊界框內的內容進行分類(或者丟棄邊界框,採用background作為一個label)
- 調整邊界框座標,以更好地使用object
顯而易見,上面忽略了一些重要的細節資訊,但是,包括了Fast R_CNN的大致思想,接下來,我們會對網路結構和每個部分的訓練及loss進行詳細說明。

基礎網路
正如上面所說,Fast R-CNN 第一步是採用基於分類任務(如:使用ImageNet)的CNN模型作為特徵提取器,聽起來比較簡單,但是重要的是理解其如何工作和為什麼會有效,並可視化中間層,檢視其輸出形式。
網路結構很難說那種是最好的,Fast R-CNN最早是採用在ImageNet訓練的ZF和VGG,其後出現了很多其他權重不同的網路,如MobileNet是一種小型效率高的網路結構,僅有3.3M引數;而ResNet-152的引數量達到了60M,新網路結構,如DenseNet在提高了結果的同時,降低了引數數量。

VGG
在討論網路結構孰優孰劣之前,這裡以VGG16為例。


VGG16是ImageNet ILSVRC 2014競賽的模型,其是基於Karen Simonyan 和Andrew Zisserman發表在論文 Very Deep Convolutional Networks for Large-Scale Image Recognition 上。今天來看,VGG16網路結構是不算深的,但在當時,其將網路層比常用的網路結構擴充套件了兩倍,開始了 “deeper→more capacity→better”的網路結構設計方向(在訓練允許的情況)。
VGG16 圖片分類時,輸入為 224×224×3的張量(即,一張 224×224 畫素的 RGB 圖片)。 網路結構最後採用 FC 層(而不是 Conv 層)得到固定長度的向量,以進行圖片分類. 對最後一個卷積層的輸出拉伸為 rank 1 的張量,然後送入 FC 層。

由於 Faster R-CNN 是採用 VGG16 的中間卷積層的輸出,因此,不用關心輸入的尺寸. 而且,該模組僅利用了卷積層. 進一步去分析模組所使用的哪一層卷積層. Faster R-CNN 論文中沒有指定所使用的卷積層,但在官方實現中是採用的卷積層 conv5/conv5_1 的輸出。
每個卷積層利用前面網路資訊來生成抽象描述. 第一層一般學習邊緣edges資訊,第二層學習邊緣edges中的圖案patterns,以學習更復雜的形狀等資訊. 最終,可以得到卷積特徵圖,其空間維度(解析度)比原圖小了很多,但更深. 特徵圖的 width 和 height 由於卷積層間的池化層而降低,而 depth 由於卷積層學習的 filters 數量而增加。


在其depth上,卷積特徵圖對圖片的所有資訊進行了編碼,同時保持相對於原始圖片所編碼“things”的位置. 例如,如果在圖片的左上角存在一個紅色正方形,而且卷積層有啟用響應,那麼該紅色正方形的資訊被卷積層編碼後,仍在卷積特徵圖的左上角。

VGG vs ResNet
現在ResNet結構逐漸取代VGG作為基礎網路,用於提取特徵。Faster R-CNN的共同作者也是ResNet網路結構論文 Deep Residual Learning for Image Recognition 的共同作者。
ResNet相對於VGG的明顯優勢是,網路更大,因此具有更強的學習能力,這對於分類任務是重要的,在目標檢測中也應該是如此。
另外,ResNet採用殘差連線(residual connection) 和 BN (batch normalization) 使得深度模型的訓練比較容易. 這對於 VGG 首次提出的時候沒有出現。

Anchors
在獲得了處理後的圖片後,需要尋找 proposals,如用於分類的 RoIs(regions of interest). anchors 是用來解決長度不定問題的。目標是,尋找圖片中的邊界框bounding boxes,邊界框是具有不同尺寸sizes和長寬比aspect ratios 的矩形。假設,已經知道圖片中有兩個 objects,首先想到的是,訓練一個網路,輸出 8 個值:兩對元組Xmin,Ymin,Xmax,Ymax,分別定義了每個 object 的邊界框. 這種方法存在一些基本問題. 例如,當圖片的尺寸和長寬比不一致時,良好訓練模型來預測,會非常複雜. 另一個問題是無效預測:預測Xmin和Xmax時,需要保證Xmin<Xmax。

事實上,有一種更加簡單的方法來預測objects,即,學習相對於參考boxes的偏移量,假設參考box:Xcenter,Ycenter,Width,Height,待預測量
 ,一般都是很小的值,以調整參考box更好擬合所需要的。
,一般都是很小的值,以調整參考box更好擬合所需要的。

Anchors是固定尺寸的邊界框,是通過利用不同的尺寸和比例在圖片上放置得到的boxes,並作為第一次預測object位置的參考boxes。
因為是對提取的 卷積特徵圖進行處理,因此在
卷積特徵圖進行處理,因此在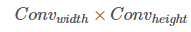 的每個點建立anchors,需要理解的是雖然anchors是基於卷積特徵圖定義的,但是最終的anchos是相對於原始圖片的。
的每個點建立anchors,需要理解的是雖然anchors是基於卷積特徵圖定義的,但是最終的anchos是相對於原始圖片的。
由於只有卷積層和池化層,特徵圖的維度是原始圖片的尺寸程比例關係的,即數學的表述,如果圖片尺寸W*H,特徵圖的尺寸是w/r * h/r,其中r是下采樣率(subsampling ratio)。如果在卷積特徵圖空間位置定義anchor,則最終的圖片會是由r畫素劃分的anchors集,在VGG中 r =16.


為了選擇anchors集,一般是先定義定義不同尺寸(如,64px,128px,256px等)和boxes長寬比(如,0.5,1,1.5等),並使用所有可能的尺寸和比例組合。



Region Proposal Network
正如我們之前提到的,RPN獲得所有參考框(錨點)並輸出一組物件的好建議,它通過為每個錨點提供兩個不同的輸出來實現這一點。
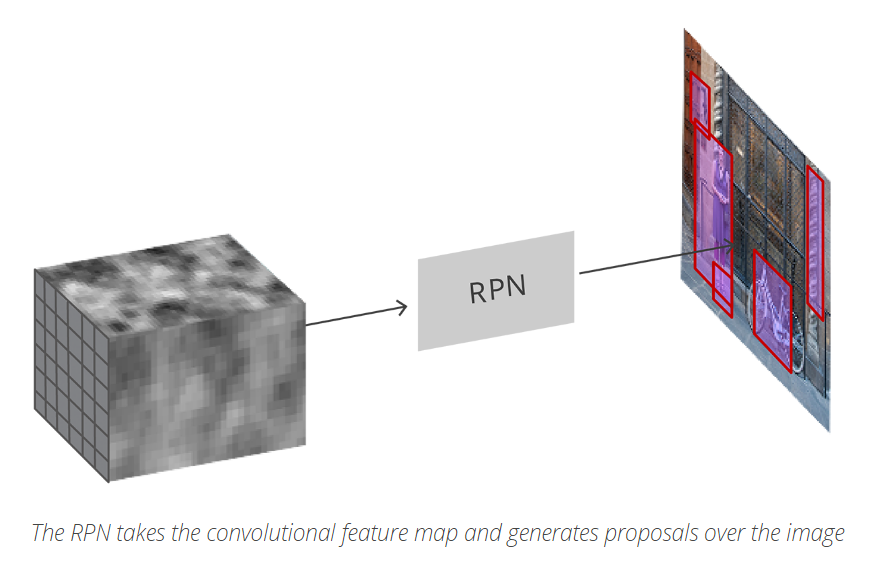

第一個是錨是物體的概率。如果你願意,一個“客觀得分”。注意RPN並不關心它是什麼類的物件,只是它實際上看起來像一個物件(而不是背景)。我們將使用這個客觀得分來過濾掉第二階段的糟糕預測,第二個輸出是調整錨的邊界盒迴歸,用於調整錨點以更好地擬合它預測的物件。
RPN以完全卷積的方式高效地實現,使用基礎網路返回的卷積特徵對映作為輸入。首先,我們使用一個包含512個通道和3x3核大小的卷積層,然後使用1x11x1核,我們有兩個平行的卷積層,通道的數量取決於每個點的錨點數量。
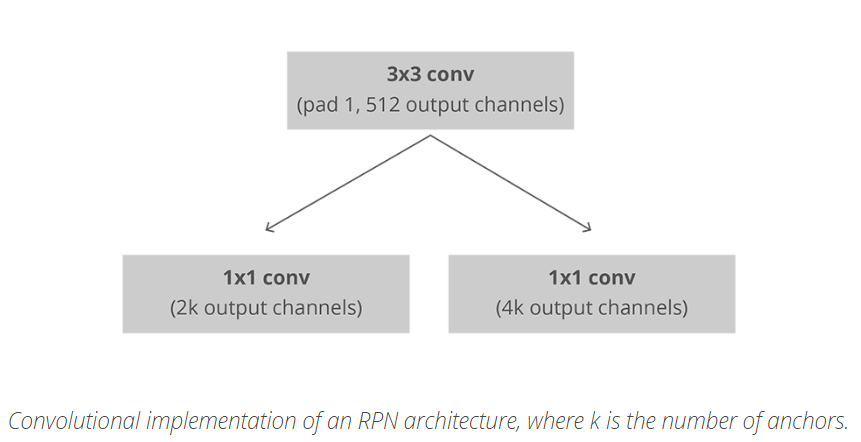

對於分類層,每個anchor輸出兩個預測值:anchor是背景(background,非object)的score和anchor是前景(foreground ,object)的score。
對於迴歸層,也可以叫邊界框調整層,每個anchor輸出4個預測值: 即用於 anchors 來得到最終的 proposals.
即用於 anchors 來得到最終的 proposals.
根據最終的 proposal 座標和其對應的 objectness score,即可得到良好的 objects proposals。

訓練,目標和損失函式
RPN 有兩種型別的預測值輸出:二值分類和邊界框迴歸調整。
訓練時,對所有的 anchors 分類為兩種類別. 與 ground-truth object 邊界框的 Intersection over Union(IoU) 大於 0.5 的 anchors 作為 foreground;小於 0.1 的作為 background。
然後,隨機取樣 anchors 來生成batchsize=256 的 mini-batch,儘可能的保持 foreground 和 background anchors 的比例平衡。

RPN 對 mini-batch 內的所有 anchors 採用 binary cross entropy 來計算分類 loss. 然後,只對 mini-batch 內標記為 foreground 的 anchros 計算迴歸 loss. 為了計算迴歸的目標targets,根據 foreground anchor 和其最接近的 groundtruth object,計算將 anchor 變換到 object groundtruth 的偏移值 correctΔ.
Faster R-CNN 沒有采用簡單的 L1 或 L2 loss 用於迴歸誤差,而是採用 Smooth L1 loss. Smooth L1 和 L1 基本相同,但是,當 L1 誤差值非常小時,表示為一個確定值 σσ, 即認為是接近正確的,loss 就會以更快的速度消失.
採用動態 batches 是很有挑戰性的. 即使已經嘗試保持 background 和 foreground 的 anchors 的平衡比例,也不總是可行的. 根據圖片中 groundtruth objects 和 anchors 的尺度與比例,很有可能得不到 foreground anchors. 這種情況時,將採用與 groundtruth boxes 具有最大 IoU 的 anchors. 這與理想情況相差很遠,但實際中一般總能有 foreground 樣本和要學習目標。

後處理
非極大值抑制(Non-maximum suppression)
由於 Anchors 一般是有重疊的overlap,因此,相同 object 的 proposals 也存在重疊.
為了解決重疊 proposals 問題,採用 NMS 演算法處理,丟棄與一個score 更高的 proposal 間 IoU 大於預設閾值的 proposals.
雖然 NMS 看起來比較簡單,但 IoU 閾值的預設需要謹慎處理. 如果 IoU 值太小,可能丟失 objetcs 的一些 proposals;如果 IoU 值過大,可能會導致 objects 出現很多 proposals. IoU 典型值為 0.6.
Proposal 選擇
NMS 處理後,根據 sore 對 topNtopN 個 proposals 排序. 在 Faster R-CNN 論文中 N=2000N=2000,其值也可以小一點,如 50,仍然能的高好的結果.

單獨應用RPN
RPN 可以獨立使用,不用 2-stage 模型.
當處理的問題是,單個 object 類時,objectness 概率即可作為最終的類別概率. 此時,“foreground” = “single class”,“background”=“not single class”.
可以應用於人臉檢測(face detection),文字檢測(text detection),等.
僅單獨採用 RPN 的優點在於,訓練和測試速度較快. 由於 RPN 是僅有卷積層的簡單網路,其預測效率比採用分類 base 網路的效率高.

Rol Pooling
RPN 處理後,可以得到一堆沒有 class score 的 object proposals.
待處理問題為,如何利用這些邊界框 bounding boxes,並分類.
一種最簡單的方法是,對每個 porposal,裁剪,並送入pre-trained base 網路,提取特徵;然後,將提取特徵來訓練分類器. 但,這就需要對所有的 2000 個 proposals 進行計算,效率低,速度慢.
Faster R-CNN 則通過重用卷積特徵圖(conv feature map) 來加快計算效率. 即,採用 RoI(region of interest) Pooling 對每個 proposal 提取固定尺寸的特徵圖. R-CNN 是對固定尺寸的特徵圖分類.
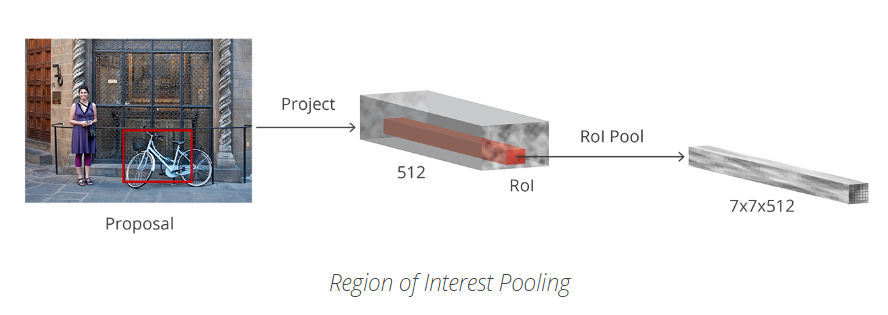

目標檢測中,包括 Faster R-CNN,常用一種更簡單的方法,即:採用每個 proposal 來對卷積特徵圖裁剪crop,然後利用插值演算法(一般為雙線性插值 bilinear)將每個 crop resize 到固定尺寸 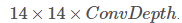 。裁剪後,利用2*2 Kernel的Max Pooling得到每個proposal的最終
。裁剪後,利用2*2 Kernel的Max Pooling得到每個proposal的最終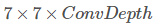 特徵圖。
特徵圖。

R-CNN-Region-based CNN
R-CNN 是 Faster R-CNN 框架中的最後一個步驟.
- 計算圖片的卷積特徵圖conv feature map;
- 然後採用 RPN 對卷積特徵圖處理,得到 object proposals;
- 再利用 RoI Pooling 對每個 proposal 提取特徵;
- 最後,利用提取特徵進行分類.
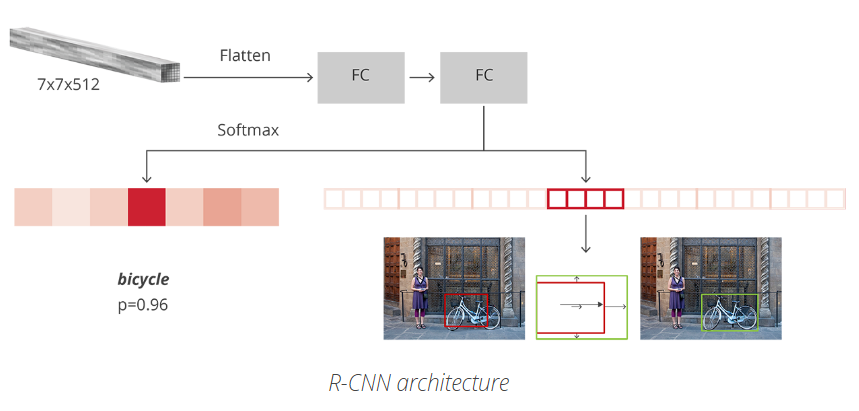
R-CNN 是模仿分類 CNNs 的最後一個階段,採用全連線層來輸出每個可能的 object 類別class 的score.
R-CNN 有兩個不同的輸出:
- 對每個 proposal 分類,其中類別包括一個 background 類(用於去除不良 proposals);
- 根據預測的類別class,更好的調整 proposal 邊界框.

在Faster R-CNN論文中,R-CNN 對每個 proposal 的特徵圖,拉平flatten,並採用 ReLU 和兩個大小為 4096 維的全連線層進行處理。
然而,對每個不同objects採用兩個不同的全連線層處理
- 一個全連線層有 N+1個神經單元,其中 N是類別 class 的總數,包括 background class;
- 一個全連線層有4N個神經單元,迴歸預測輸出,得到N個可能的類別classes分別預測
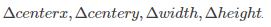

訓練和目標
R-CNN 的目標基本上是與 RPN 目標的計算是一致的,但需要考慮不同的可能的 object 類別 classes.
根據 proposals 和 ground-truth boxes,計算其 IoU.
與任何一個 ground-truth box 的 IoU 大於 0.5 的 proposals 被設為正確的 boxes. IoU 在 0.1 到 0.5 之間時設為 background.
與 RPN 中目標組裝相關,這裡忽略沒有任何交叉的 proposals. 這是因為,在此階段,假設已經獲得良好的 proposals,主要關注於解決難例. 當然,所有的這些超引數都是可以用於調整以更好的擬合 objects.
邊界框迴歸的目標計算的是 proposal 與其對應的 ground-truth間的偏移量,只對基於 IoU 閾值設定類別class 後的 proposals 進行計算.

隨機採用一個平衡化的 mini-batch=64,其中,25% 的 foreground proposals(具有類別class) 和 75% 的background proposals.
類似於 RPNs 的 losses,對於選定的 proposals,分類 loss 採用 multiclass entropy loss;對於 25% 的 foreground proposals 採用 SmoothL1 loss 計算其與 groundtruth box 的匹配.
由於 R-CNN 全連線網路對每個類別class 僅輸出一個預測值,當計算邊框迴歸loss 時需謹慎. 當計算 loss 時,只需考慮正確的類別.

後處理
類似於 RPN,R-CNN 最終輸出一堆帶有類別 class 的objects,在返回結果前,再進一步進行處理.
為了調整邊界框,需要考慮概率最大的類別的 proposals. 忽略概率最大值為 background class 的proposals.
當得到最終的 objects 時,並忽略被預測為 background 的結果,採用 class-based NMS. 主要是通過對 objects 根據類別class 分組,然後根據概率排序,並對每個獨立的分組採用 NMS 處理,最後再放在一起.
最終得到的 objects 列表,仍可繼續通過設定概率閾值的方式,來限制每個類的 objects 數量.

Faster R-CNN 訓練
Faster R-CNN 在論文中是採用分步 multi-step 方法,對每個模組分別訓練再合併訓練的權重. 自此,End-to-end 的聯合訓練被發現能夠得到更好的結果.
當將完整的模型合併後,得到 4 個不同的 losses,2 個用於 RPN,2 個用於 R-CNN. RPN 和 R-CNN 的base基礎網路可以是可訓練(fine-tune)的,也可以是不能訓練的.
base基礎網路的訓練與否,取決於待學習的objects與可用的計算力. 如果新資料與 base基礎網路訓練的原始資料集相似,則不必進行訓練,除非是想嘗試其不同的表現. base基礎網路的訓練是比較時間與硬體消耗較高,需要適應梯度計算.

4 種不同的 losses 以加權和的形式組織. 可以根據需要對分類 loss 和迴歸 loss 設定權重,或者對 R-CNN 和 RPNs 設定不同權重.
採用 SGD 訓練,momentum=0.9. 學習率初始值為 0.001,50K 次迭代後衰減為 0.0001. 這是一組常用引數設定
採用 Luminoth 訓練時,直接採用預設值開始。

評價
評價準則:指定 IoU 閾值對應的 Mean Average Precision (mAP),如 [email protected]
mAP 來自資訊檢索,常用與計算 ranking 問題的誤差計算,以及評估目標檢測結果.

總結
至此,對 Faster R-CNN 的處理方式有了清晰的理解,可以根據實際應用場合來做一些應用.
如果想進一步深入理解,可以參考 Luminoth Faster R-CNN 實現.
Faster R-CNN 可以用於解決複雜的計算機視覺問題,並取得很好的效果. 雖然這裡模型是目標檢測,但對於語義分割,3D目標檢測等,都可以基於以上模型. 或借鑑於 RPN,或借鑑於 R-CNN,或兩者都有. 因此,能夠深度理解其工作原理,對於更好的解決其它問題很有幫助.
參考:https://zhuanlan.zhihu.com/p/24916624
https://blog.csdn.net/zziahgf/article/details/79311275
論文標題:Faster R-CNN: Down the rabbit hole of modern object detection
論文作者:Zhi Tian , Weilin Huang, Tong He , Pan He , and Yu Qiao
論文地址:https://tryolabs.com/blog/2018/01/18/faster-r-cnn-down-the-rabbit-hole-of-modern-object-detection/
論文地址:
宣告:小編翻譯論文僅為學習,如有侵權請聯絡小編刪除博文,謝謝!
小編是一個機器學習初學者,打算認真研究論文,但是英文水平有限,所以論文翻譯中用到了Google,並自己逐句檢查過,但還是會有顯得晦澀的地方,如有語法/專業名詞翻譯錯誤,還請見諒,並歡迎及時指出。
在此之前,我們討論了目標檢測,關於它是什麼以及最近如何使用深度學習解決它。如果你還沒有閱讀之前的部落格,我們建議您先閱讀它,再來看這篇文章。
去年,我們打算去研究Fast R-CNN,閱讀原始論文和所有參考論文(等等),知道我們清楚地瞭解它是如何工作的以及如何去實現它。
我們最終在Luminoth中實施了Fast R-CNN,這是一個基於TensorFlow的計算機視覺工具包,可以輕鬆訓練,監控和使用這些型別的模型。到目前為止,Luminoth已經引起了我們極大的興趣,並且我們甚至在ODSC Eueope和ODSC West談到了它。
基於開發Luminoth的所有工作並基於我們所做的演示,我們認為最好有一篇博文,其中包含我們在研究中收集的所有細節和連結,作為未來的參考,任何人都對該主題感興趣。
背景
Faster R-CNN發表於NIPS 2015,其後出現了很多改進的版本,後面會進行介紹。正如我們在之前的部落格文章中提到的,Faster R-CNN是R-CNN論文的第三次迭代。其中Ross Girshick是作者兼合併者。
一切始於2014年的“ 用於精確物件檢測和語義分割的豐富特徵層次結構 ”(R-CNN),其使用稱為選擇性搜尋的演算法來提出可能的感興趣區域和用於分類和調整它們的標準卷積神經網路(CNN)。 。它迅速演變為2015年初發布的Fast R-CNN,其中一種名為Region of Interest Pooling的技術允許共享昂貴的計算並使模型更快。終於推出了Fast R-CNN,其中提出了第一個完全可微分的模型。
網路結構
Faster R-CNN 的結構是複雜的,因為其有幾個移動部件. 這裡先對整體框架巨集觀介紹,然後再對每個部分的細節分析.
問題描述:
針對一張圖片,需要獲得的輸出有:
- 邊界框(bounding boxes) 列表;
- 每個邊界框的類別標籤;
- 每個邊界框和類別標籤的概率.
首先,輸入圖片表示為 Height×Width×DepthHeight×Width×Depth 的張量(多維陣列)形式,經過預訓練 CNN 模型的處理,得到卷積特徵圖(conv feature map). 即,將 CNN 作為特徵提取器,送入下一個部分。
這種技術在遷移學習(Transfer Learning)中比較普遍,尤其是,採用在大規模資料集訓練的網路權重,來對小規模資料集訓練分類器. 後面會詳細介紹。
然後,RPN(Region Propose Network) 對提取的卷積特徵圖進行處理. RPN 用於尋找可能包含 objects 的預定義數量的區域(regions,邊界框).
基於深度學習(DL)的目標檢測中,可能最難的問題就是生成長度不定(variable-length)的邊界框列表. 在構建深度神經網路時,最後的網路輸出一般是固定尺寸的張量輸出(採用RNN的除外). 例如,在圖片分類中,網路輸出是 (N,) 的張量,N是類別標籤數,張量的每個位置的標量值表示圖片是類別 labeli的概率值。
在 RPN 中,通過採用 anchors 來解決邊界框列表長度不定的問題,即,在原始影象中統一放置固定大小的參考邊界框. 不同於直接檢測 objects 的位置,這裡將問題轉化為兩部分:
對每一個 anchor 而言,
- anchor 是否包含相關的 object?
- 如何調整 anchor 以更好的擬合相關的 object。
這裡可能不容易理解,後面會深入介紹。
當獲得了可能的相關objects和其在原始影象中的對應位置之後,問題就更加直接了,採用CNN提取新的特徵和包含相關objects的邊界框,採用Rol Pooling處理,並提取相關object的特徵,得到了新的向量。
最後基於R-CNN模組,得到:
- 對邊界框內的內容進行分類(或者丟棄邊界框,採用background作為一個label)
- 調整邊界框座標,以更好地使用object
顯而易見,上面忽略了一些重要的細節資訊,但是,包括了Fast R_CNN的大致思想,接下來,我們會對網路結構和每個部分的訓練及loss進行詳細說明。
基礎網路
正如上面所說,Fast R-CNN 第一步是採用基於分類任務(如:使用ImageNet)的CNN模型作為特徵提取器,聽起來比較簡單,但是重要的是理解其如何工作和為什麼會有效,並可視化中間層,檢視其輸出形式。
網路結構很難說那種是最好的,Fast R-CNN最早是採用在ImageNet訓練的ZF和VGG,其後出現了很多其他權重不同的網路,如MobileNet是一種小型效率高的網路結構,僅有3.3M引數;而ResNet-152的引數量達到了60M,新網路結構,如DenseNet在提高了結果的同時,降低了引數數量。
VGG
在討論網路結構孰優孰劣之前,這裡以VGG16為例。
VGG16是ImageNet ILSVRC 2014競賽的模型,其是基於Karen Simonyan 和Andrew Zisserman發表在論文 Very Deep Convolutional Networks for Large-Scale Image Recognition 上。今天來看,VGG16網路結構是不算深的,但在當時,其將網路層比常用的網路結構擴充套件了兩倍,開始了 “deeper→more capacity→better”的網路結構設計方向(在訓練允許的情況)。
VGG16 圖片分類時,輸入為 224×224×3的張量(即,一張 224×224 畫素的 RGB 圖片)。 網路結構最後採用 FC 層(而不是 Conv 層)得到固定長度的向量,以進行圖片分類. 對最後一個卷積層的輸出拉伸為 rank 1 的張量,然後送入 FC 層。
由於 Faster R-CNN 是採用 VGG16 的中間卷積層的輸出,因此,不用關心輸入的尺寸. 而且,該模組僅利用了卷積層. 進一步去分析模組所使用的哪一層卷積層. Faster R-CNN 論文中沒有指定所使用的卷積層,但在官方實現中是採用的卷積層 conv5/conv5_1 的輸出。
每個卷積層利用前面網路資訊來生成抽象描述. 第一層一般學習邊緣edges資訊,第二層學習邊緣edges中的圖案patterns,以學習更復雜的形狀等資訊. 最終,可以得到卷積特徵圖,其空間維度(解析度)比原圖小了很多,但更深. 特徵圖的 width 和 height 由於卷積層間的池化層而降低,而 depth 由於卷積層學習的 filters 數量而增加。
在其depth上,卷積特徵圖對圖片的所有資訊進行了編碼,同時保持相對於原始圖片所編碼“things”的位置. 例如,如果在圖片的左上角存在一個紅色正方形,而且卷積層有啟用響應,那麼該紅色正方形的資訊被卷積層編碼後,仍在卷積特徵圖的左上角。
VGG vs ResNet
現在ResNet結構逐漸取代VGG作為基礎網路,用於提取特徵。Faster R-CNN的共同作者也是ResNet網路結構論文 Deep Residual Learning for Image Recognition 的共同作者。
ResNet相對於VGG的明顯優勢是,網路更大,因此具有更強的學習能力,這對於分類任務是重要的,在目標檢測中也應該是如此。
另外,ResNet採用殘差連線(residual connection) 和 BN (batch normalization) 使得深度模型的訓練比較容易. 這對於 VGG 首次提出的時候沒有出現。
Anchors
在獲得了處理後的圖片後,需要尋找 proposals,如用於分類的 RoIs(regions of interest). anchors 是用來解決長度不定問題的。目標是,尋找圖片中的邊界框bounding boxes,邊界框是具有不同尺寸sizes和長寬比aspect ratios 的矩形。假設,已經知道圖片中有兩個 objects,首先想到的是,訓練一個網路,輸出 8 個值:兩對元組Xmin,Ymin,Xmax,Ymax,分別定義了每個 object 的邊界框. 這種方法存在一些基本問題. 例如,當圖片的尺寸和長寬比不一致時,良好訓練模型來預測,會非常複雜. 另一個問題是無效預測:預測Xmin
論文標題:Faster R-CNN: Down the rabbit hole of modern object detection
論文作者:Zhi Tian , Weilin Huang, Tong He , Pan He , and Yu Qiao
論文地址:https://tryolab 論文標題:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
標題翻譯:基於區域提議(Region Proposal)網路的實時目標檢測
論文作者:Shaoqing Ren, K cluster tina ble mac 曾經 media bject batch 因此 原標題: YOLOv3: An Incremental Improvement
原作者: Joseph Redmon Ali Farhadi
YOLO官網:YOLO: Real-Tim 論文標題:An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition
論文作者: Baoguang Shi, Xiang B 論文標題:Detecting Text in Natural Image with Connectionist Text Proposal Network
論文作者:Zhi Tian , Weilin Huang, Tong He , Pan He , and Yu Qiao
論文原始碼的下載地址:htt 論文標題:Siamese Neural Networks for One-shot Image Recognition
論文作者: Gregory Koch Richard Zemel Ruslan Salakhutdinov
論文地址:https://www.cs.cmu.edu/~rsala 論文標題:MobileNets:Efficient Convolutional Neural Networks for Mobile Vision Appliications
論文作者:Andrew G.Howard Menglong Zhu Bo Chen .....
論文地址:ht 論文標題:Support Vector Method for Novelty Detection
論文作者:Bernhard Scholkopf, Robert Williamson, Alex Smola .....
論文地址:http://papers.nips.cc/paper/1723-support 論文標題:Rich feature hierarchies for accurate object detection and semantic segmentation
標題翻譯:豐富的特徵層次結構,可實現準確的目標檢測和語義分割
論文作者:Ross Girshick Jeff Donahue Trev
論文標題:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
標題翻譯:用於視覺識別的深度卷積神經網路中的空間金字塔池
論文作者:Kaiming He, Xiangyu Zhang, Shao 論文標題:Visualizing and Understanding Convolutional Networks
標題翻譯:視覺化和理解卷積網路
論文作者:Matthew D. Zeiler Rob Fergus
論文地址:https://arxiv.org/pdf/1311.2901v3. 論文標題:OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks
標題翻譯:OverFeat:使用卷積神經網路整合識別,定位和檢測
論文作者:Pierre Sermanet&nb 論文標題:Densely Connected Convolutional Networks
論文作者:Gao Huang Zhuang Liu Laurens van der Maaten Kilian Q. Weinberger
論文地址:https://arxiv.org/pdf/1608.0 論文標題:Squeeze-and-Excitation Networks
論文作者:Jie Hu Li Shen Gang Sun
論文地址:https://openaccess.thecvf.com/content_cvpr_2018/papers/Hu_Squeeze-and-E 論文標題:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
論文作者:Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry 論文標題:MobileNetV2: Inverted Residuals and Linear Bottlenecks
論文作者:Mark Sandler Andrew Howard Menglong Zhu Andrey Zhmoginov Liang-Chieh Chen
論文地址:https://arx 論文標題:Searching for MobileNetV3
論文作者:Andrew Howard, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Chen, Mingxing Tan, Weijun W
yolo-v1
核心思想:從R-CNN到Fast R-CNN一直採用的思路是proposal+分類 (proposal 提供位置資訊, 分類提供類別資訊)精度已經很高,但是速度還不行。 YOLO提供了另一種更為直接的思路: 直接在輸出層迴歸bounding b
深度學習論文隨記(二)---VGGNet模型解讀
Very Deep Convolutional Networks forLarge-Scale Image Recognition
Author: K Simonyan , A Zisserman
Year: 2014
想要獲得更多深度學習在NLP方面應用的經典論文、實踐經驗和最新訊息,歡迎關注微信公眾號“DeepLearning_NLP”
或者掃描下方二維碼新增關注。
深度神經網路
12.《受限波爾茲曼機簡介》
(1)主要內容:主要介紹受限玻爾茲曼機(RBM)的基本模型、學習 相關推薦
深度學習論文翻譯解析(四):Faster R-CNN: Down the rabbit hole of modern object detection
深度學習論文翻譯解析(十三):Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
深度學習論文翻譯解析(一):YOLOv3: An Incremental Improvement
深度學習論文翻譯解析(二):An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition
深度學習論文翻譯解析(三):Detecting Text in Natural Image with Connectionist Text Proposal Network
深度學習論文翻譯解析(五):Siamese Neural Networks for One-shot Image Recognition
深度學習論文翻譯解析(六):MobileNets:Efficient Convolutional Neural Networks for Mobile Vision Appliications
深度學習論文翻譯解析(七):Support Vector Method for Novelty Detection
深度學習論文翻譯解析(八):Rich feature hierarchies for accurate object detection and semantic segmentation
深度學習論文翻譯解析(九):Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
深度學習論文翻譯解析(十):Visualizing and Understanding Convolutional Networks
深度學習論文翻譯解析(十一):OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks
深度學習論文翻譯解析(十五):Densely Connected Convolutional Networks
深度學習論文翻譯解析(十六):Squeeze-and-Excitation Networks
深度學習論文翻譯解析(十七):MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
深度學習論文翻譯解析(十八):MobileNetV2: Inverted Residuals and Linear Bottlenecks
深度學習論文翻譯解析(十九):Searching for MobileNetV3
基於深度學習的視訊檢測(四) yolo-v2和darkflow
深度學習論文隨記(二)---VGGNet模型解讀-2014年(Very Deep Convolutional Networks for Large-Scale Image Recognition)
深度學習論文閱讀筆記(三)之深度信念網路DBN