
用etree和Beautiful Soup爬取騰訊招聘網站
阿新 • • 發佈:2018-11-12
1.lxml 是一種使用 Python 編寫的庫,可以迅速、靈活地處理 XML ,支援 XPath (XML Path Language),使用 lxml 的 etree 庫來進行爬取網站資訊
2.Beautiful Soup支援從HTML或XML檔案中提取資料的Python庫;支援Python標準庫中的HTML解析器;還支援一些第三方的解析器lxml, 使用的是 Xpath 語法
Beautiful Soup自動將輸入文件轉換為Unicode編碼,輸出文件轉換為utf-8編碼。
我們爬取騰訊招聘網站的連結為https://hr.tencent.com/position.php?&start=10#a
需要獲取職位名稱、職位類別、招聘人數、工作地點、釋出時間等資訊
一、使用etree爬取資訊
1.匯入庫

在python.3中使用urllib庫中的request模組,儲存輸出為json檔案
2.獲取網站並寫到json檔案中

如果只使用w來寫入檔案會報錯:write() argument must be str, not bytes,我們需要用二進位制來開啟改為wb+
3.獲取我們需要得到的標籤


必須是字典形式,先定義一個空字典

找到我們需要的欄位
4.規範輸出形式

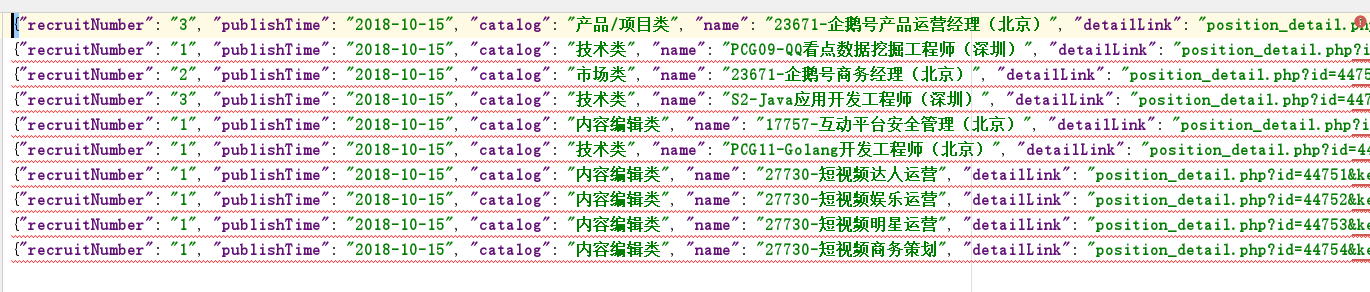
執行後結果如下:

匯出的json檔案如下:
二、使用Beautiful Soup爬取資訊
1.匯入庫

2.獲取網站並寫到json檔案中

3.獲取我們需要得到的標籤

4.規範輸出形式

執行結果如下:

以上為兩種方法爬取網站資訊,個人覺得用Beautiful Soup爬取比較方便