
爬取騰訊課堂的課程評論
阿新 • • 發佈:2018-12-07
最近想了解一下線上教育的課程的如何去選擇,課程的質量如何?所以試著去爬了一下騰訊課堂,只爬了IT網際網路這一項。
通過分析發現要想爬取到評論需要是個步驟:

通過開發者工具審查元素,發現標籤在<dl class="sort-menu sort-menu1 clearfix">下
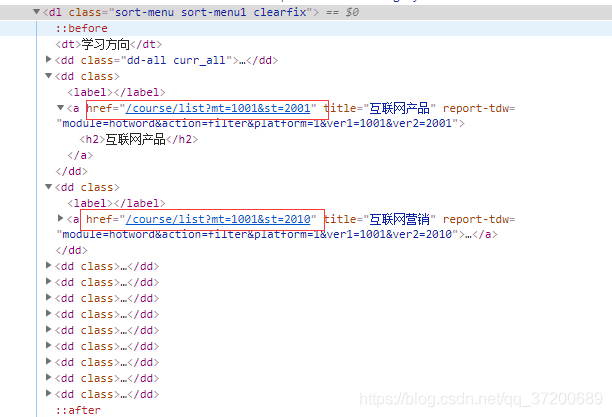
然後去寫解析程式碼:
· # _pattern表示解析href的正則表示式 def get_menu_link(self, url, _pattern): headers = { 'user-agent': self.round_header() } start = time.perf_counter() res = self.s.get(url, headers=headers) if res is None: return content = res.text menu_pattern = re.compile(r'<dl class="sort-menu sort-menu1 clearfix">(.*?)</dl>', re.S) menu = re.findall(menu_pattern, content) link_paternt = re.compile(_pattern, re.S | re.M) if len(menu) != 0: links = re.findall(link_paternt, menu[0]) end = time.perf_counter() _time = end - start print('{0}解析成功,共耗時:{1:f}s'.format(url, _time)) for item in links: item = item.replace('&', '&') link = 'https://ke.qq.com{0}'.format(item) yield link else: end = time.perf_counter() _time = end - start print('{0}解析失敗!!!,共耗時:{1:f}s'.format(url, _time)) return None
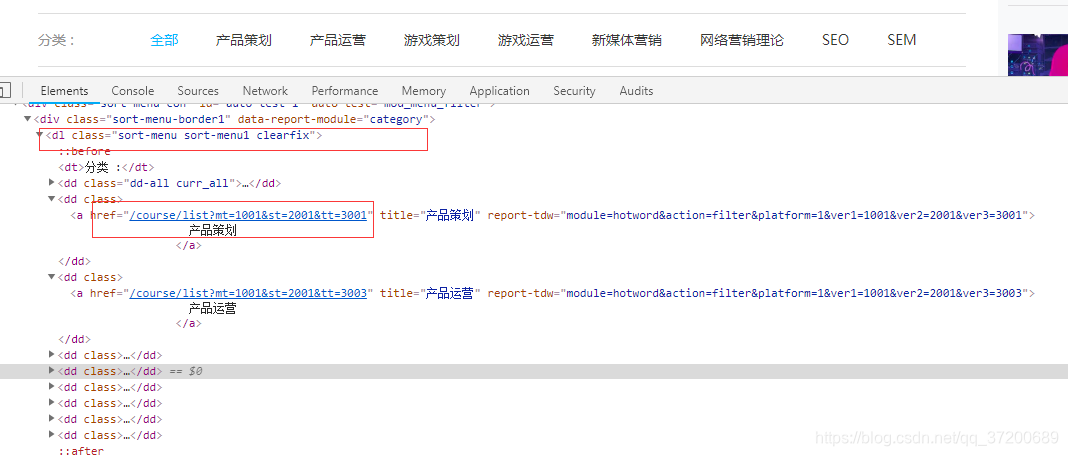
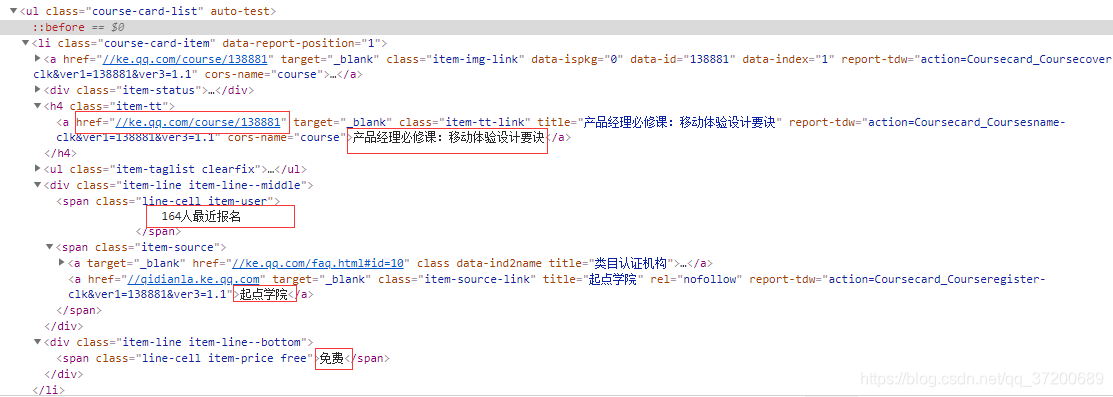
解析程式碼如下:
def get_course_list(self, url): headers = { 'user-agent': self.round_header() } start = time.perf_counter() res = self.s.get(url, headers=headers) if res is None: return content = res.text course_card_list_pattern = re.compile(r'<ul class="course-card-list.+?">\s+(.+)\s+</ul>', re.S) course_card_list = re.findall(course_card_list_pattern, content) course_list_pattern = re.compile(r'<li class="course-card-item.*?">.*?<h4 class="item-tt">\s+' + r'<a href="(.*?)" target="_blank" class="item-tt-link.*?">(.*?)</a>\s+</h4>.*?<div ' + r'class="item-line.*?middle">\s+<span class="line-cell.*?">\s+(.*?)\s+</span>\s+<span ' + r'class="item-source">.*?class="item-source-link.*?">(.*?)</a>\s+.*?<div ' + r'class="item-line.*?bottom">\s+<span class="line-cell item-price free">(.*?)</span>\s+</div>\s+</li>', re.S) if len(course_card_list) != 0: #這裡只獲取了前三個 course_list = re.findall(course_list_pattern, course_card_list[0])[0:3] end = time.perf_counter() _time = end - start print('解析成功,共耗時:{0}s'.format(_time)) for item in course_list: yield { 'url': 'https:{0}'.format(item[0]), 'courseName': item[1], 'num': item[2], 'source': item[3], 'fee': item[4] } else: end = time.perf_counter() _time = end - start print('在該連結下沒有找到課程列表,共耗時:{0}s'.format(_time)) return None
- 最後到了獲取評論,發現是動態獲取的,所以要去分析傳送請求中的引數

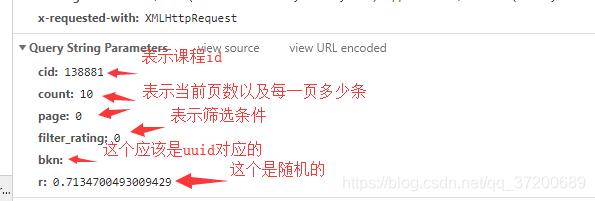
好了,引數都分析好了,接著看程式碼:
def get_comment(self, url, params, headers): res = self.get(url, params=params, headers=headers) if res is None: return #解析json成Python物件 result = json.loads(res.text).get('result') return { 'total_page': result.get('total_page'), 'comments': result.get('items'), 'total_num': result.get('total_num') } # 獲取cid cid = re.search(r'/(\d+)', _url).group(1) # 獲取19位隨機數 r = eval('{0:.18f}'.format(random.random())[0:19]) params = { 'cid': cid, 'count': 10, 'page': 0, 'filter_rating': 0, 'bkn': '', 'r': r } headers = { 'user-agent': t.round_header(), 'referer': _url, 'cookie': 'pgv_info=ssid=s6819497920; ts_last=ke.qq.com/course/144558; pgv_pvid=1821056816; ts_uid=7896600315; _pathcode=0.9075570219139721; tdw_auin_data=-; tdw_data={"ver4":"4","ver6":"","refer":"","from_channel":"","path":"eh-0.9075570219139721","auin":"-","uin":null,"real_uin":null}; tdw_first_visited=1; Hm_lvt_0c196c536f609d373a16d246a117fd44=1543998342; Hm_lpvt_0c196c536f609d373a16d246a117fd44=1543998342; tdw_data_new_2={"auin":"-","sourcetype":"","sourcefrom":"","uin":"","visitor_id":"53087919"}' } __url = 'https://ke.qq.com/cgi-bin/comment_new/course_comment_list' print('獲取cid:{0}的評論'.format(cid), end='\t') comments = t.get_comment(__url, params, headers=headers) coures.update(comments)
到這裡整個爬蟲就寫完了,全部程式碼如下:
import requests as req
import sys
import io
import time
import re
import random
import json
import csv
from utils.spider import Spider
class Ten(Spider):
def __init__(self, url):
Spider.__init__(self, url)
self.url = url
self.s = req.Session()
self.flag = 1
def get_menu_link(self, url, _pattern):
headers = {
'user-agent': self.round_header()
}
start = time.perf_counter()
res = self.s.get(url, headers=headers)
if res is None:
return
content = res.text
menu_pattern = re.compile(r'<dl class="sort-menu sort-menu1 clearfix">(.*?)</dl>', re.S)
menu = re.findall(menu_pattern, content)
link_paternt = re.compile(_pattern, re.S | re.M)
if len(menu) != 0:
links = re.findall(link_paternt, menu[0])
end = time.perf_counter()
_time = end - start
print('{0}解析成功,共耗時:{1:f}s'.format(url, _time))
for item in links:
item = item.replace('&', '&')
link = 'https://ke.qq.com{0}'.format(item)
yield link
else:
end = time.perf_counter()
_time = end - start
print('{0}解析失敗!!!,共耗時:{1:f}s'.format(url, _time))
return None
def get_course_list(self, url):
headers = {
'user-agent': self.round_header()
}
start = time.perf_counter()
res = self.s.get(url, headers=headers)
if res is None:
return
content = res.text
course_card_list_pattern = re.compile(r'<ul class="course-card-list.+?">\s+(.+)\s+</ul>', re.S)
course_card_list = re.findall(course_card_list_pattern, content)
course_list_pattern = re.compile(r'<li class="course-card-item.*?">.*?<h4 class="item-tt">\s+'
+ r'<a href="(.*?)" target="_blank" class="item-tt-link.*?">(.*?)</a>\s+</h4>.*?<div '
+ r'class="item-line.*?middle">\s+<span class="line-cell.*?">\s+(.*?)\s+</span>\s+<span '
+ r'class="item-source">.*?class="item-source-link.*?">(.*?)</a>\s+.*?<div '
+ r'class="item-line.*?bottom">\s+<span class="line-cell item-price free">(.*?)</span>\s+</div>\s+</li>',
re.S)
if len(course_card_list) != 0:
course_list = re.findall(course_list_pattern, course_card_list[0])[0:3]
end = time.perf_counter()
_time = end - start
print('解析成功,共耗時:{0}s'.format(_time))
for item in course_list:
yield {
'url': 'https:{0}'.format(item[0]),
'courseName': item[1],
'num': item[2],
'source': item[3],
'fee': item[4]
}
else:
end = time.perf_counter()
_time = end - start
print('在該連結下沒有找到課程列表,共耗時:{0}s'.format(_time))
return None
def get_comment(self, url, params, headers):
res = self.get(url, params=params, headers=headers)
if res is None:
return
result = json.loads(res.text).get('result')
return {
'total_page': result.get('total_page'),
'comments': result.get('items'),
'total_num': result.get('total_num')
}
def save(self, data):
fieldnames = ['url', 'courseName', 'num', 'source', 'fee', 'total_num', 'total_page', 'comments']
file_name = 'mooc.csv'
with open(file_name, 'a+', newline='', encoding='utf-8') as f:
w = csv.DictWriter(f, fieldnames)
if self.flag == 1:
w.writeheader()
self.flag = 0
w.writerow(data)
if __name__ == "__main__":
# it 網際網路
# 第一步先解析網際網路下的分類URL
# 第二步解析一級選單下的分類
# 第三步解析二級選單下的前三個課程連結
# 第四步解析課程中的評論
url = 'https://ke.qq.com/course/list?mt=1001'
list_no = []
t = Ten(url)
# 1.
link_paternt = r'<dd class="">\s+<\w+></\w+>\s+<a href="(.*?)" title=".*?">.*?</a>\s+</dd>'
print('--------開始爬取--------')
links = t.get_menu_link(url, link_paternt)
if links is not None:
for item in links:
# 2.
option_pattern = r'<dd class="">\s+<a href="(.*?)" title=".*?">.*?</a>\s+</dd>'
options = t.get_menu_link(item, option_pattern)
time.sleep(2)
if options is not None:
for option in options:
print('開始解析{}'.format(option), end=' ====>> ')
# 3
course_list = t.get_course_list(option)
time.sleep(2)
if course_list is None:
list_no.append(option)
continue
else:
for coures in course_list:
_url = coures.get('url')
# 4
cid = re.search(r'/(\d+)', _url).group(1)
r = eval('{0:.18f}'.format(random.random())[0:19])
params = {
'cid': cid,
'count': 10,
'page': 0,
'filter_rating': 0,
'bkn': '',
'r': r
}
headers = {
'user-agent': t.round_header(),
'referer': _url,
'cookie': 'pgv_info=ssid=s6819497920; ts_last=ke.qq.com/course/144558; pgv_pvid=1821056816; ts_uid=7896600315; _pathcode=0.9075570219139721; tdw_auin_data=-; tdw_data={"ver4":"4","ver6":"","refer":"","from_channel":"","path":"eh-0.9075570219139721","auin":"-","uin":null,"real_uin":null}; tdw_first_visited=1; Hm_lvt_0c196c536f609d373a16d246a117fd44=1543998342; Hm_lpvt_0c196c536f609d373a16d246a117fd44=1543998342; tdw_data_new_2={"auin":"-","sourcetype":"","sourcefrom":"","uin":"","visitor_id":"53087919"}'
}
__url = 'https://ke.qq.com/cgi-bin/comment_new/course_comment_list'
print('獲取cid:{0}的評論'.format(cid), end='\t')
comments = t.get_comment(__url, params, headers=headers)
coures.update(comments)
t.save(coures)