ALS演算法理解和引數調優
在上一篇博文中我們一起學習瞭如何用spark構建一套歌手推薦系統,在模型訓練的時候,我們用到的是ALS演算法,這篇博文我們就一起來學習一下ALS演算法的原理吧。ALS演算法全稱是Alternating Least Squares,從協同過濾的分類來說,這裡的ALS演算法是同時基於使用者和物品的協同,所以說ALS演算法也是混合的協同過濾。其實使用者和物品的關係可以由使用者、物品和評分三項聯絡在一起,可以用<user,item,rating>來表示,rating表示使用者對商品的喜愛程度,也就是使用者對商品的評分,在我的歌手推薦系統中,我們將使用者聽某首歌的頻次作為這首歌的評分。當我們的歌手和使用者的數量足夠大的時候,我們就會得到一個非常大的矩陣,但是這個矩陣只有小部分的位置有資料,因此這個評分矩陣是一個稀疏矩陣,因為這個矩陣巨大,用傳統的分解方法已經很難將這個矩陣進行分解了。所以我們假設使用者和歌手之間存在著若干有聯絡的隱形特徵,也就是維度,比如說使用者的年紀,性別,歌手的年紀,使用者的學歷等等,這些都是一些隱形的特徵,所以我們需要將原始的R矩陣投射在這些隱形的矩陣上面,用數學表示式可以表達成:
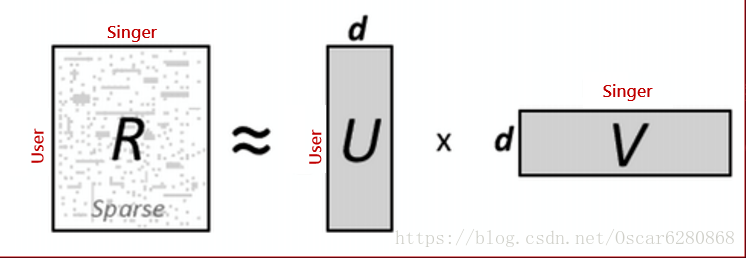
這裡的約等於符號表示這是一個近似的空間變換,也就是說原始的矩陣可以表示成m x k 和 k x n的矩陣相乘,這裡的k就表示我們的隱藏因子數,也稱作latent factor,通過矩陣的拆分,我們可以做到資料降維的目的,矩陣拆分可以由下圖表示:
我們的目的是讓矩陣X和Y相乘儘可能地相似R矩陣,所以我們目的就是最小化我們矩陣的平方損失函式:
整體來說,就是讓我們整體的真實值與我們相乘的預測值儘可能小。我們考慮到矩陣穩定性的問題,我們可以將上述公式正則化:
優化這個公式,最小化我們的損失函式,可以得到我們的X和Y矩陣,將這兩個矩陣相乘,可以得到我們預測的矩陣,這個矩陣不僅可以預測我們使用者對歌手的打分,還可以比較不同使用者或者歌手之間的相似度。ALS演算法是一個離線演算法,所以我們新添加了使用者或者歌手,不能實時進行推薦,這是一個冷啟動的問題,但是ALS演算法在推薦系統中還是佔有很重要的一席之地。
還有就是我們如何優化上述的公式,如何去最小化我們的損失函式。這裡大家想到的就是將上述公式進行求導,但是這個公式直接求導是比較麻煩的,因為有X和Y兩個變數,所以我們可以先優化一個維度,固定其他的維度,所以我們可以對xu求偏導,然後我們可以得到如下的結果:
求導完成之後,我們可以令這個導數為0,然後可以得到下面的公式: