
十、如何選擇神經網路的超引數
本部落格主要內容為圖書《神經網路與深度學習》和National Taiwan University (NTU)林軒田老師的《Machine Learning》的學習筆記,因此在全文中對它們多次引用。初出茅廬,學藝不精,有不足之處還望大家不吝賜教。
在之前的部分,採用梯度下降或者隨機梯度下降等方法優化神經網路時,其中許多的超引數都已經給定了某一個值,在這一節中將討論如何選擇神經網路的超引數。
1. 神經網路的超引數分類
神經網路中的超引數主要包括1. 學習率 ηη,2. 正則化引數 λλ,3. 神經網路的層數 LL,4. 每一個隱層中神經元的個數 jj,5. 學習的回合數EpochEpoch,6. 小批量資料 minibatchminibatch 的大小,7. 輸出神經元的編碼方式,8. 代價函式的選擇,9. 權重初始化的方法,10. 神經元啟用函式的種類,11.參加訓練模型資料的規模 這十一類超引數。
這些都是可以影響神經網路學習速度和最後分類結果,其中神經網路的學習速度主要根據訓練集上代價函式下降的快慢有關,而最後的分類的結果主要跟在驗證集上的分類正確率有關。因此可以根據該引數主要影響代價函式還是影響分類正確率進行分類,如圖1所示
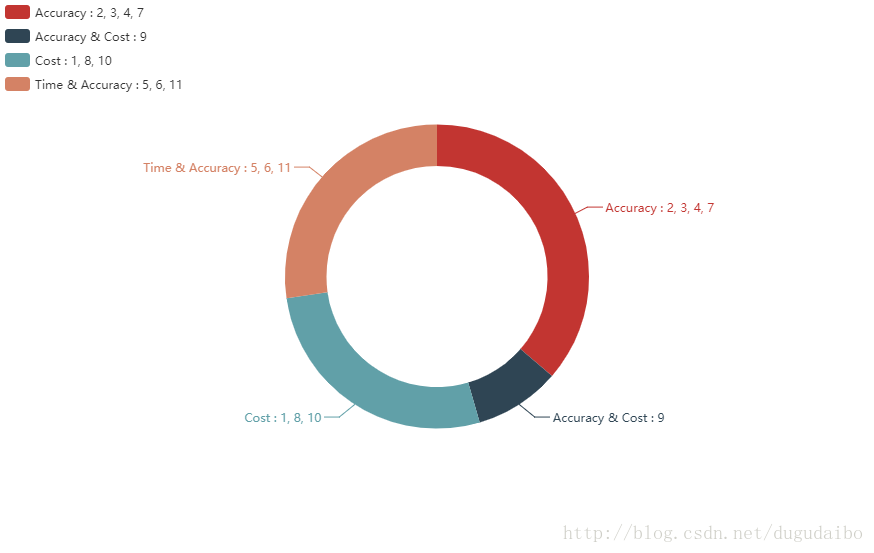
圖1. 十一類超引數的分類情況
在上圖中可以看到超引數 2,3,4, 7 主要影響的時神經網路的分類正確率;9 主要影響代價函式曲線下降速度,同時有時也會影響正確率;1,8,10 主要影響學習速度,這點主要體現在訓練資料代價函式曲線的下降速度上;5,6,11 主要影響模型分類正確率和訓練用總體時間。這上面所提到的時某個超引數對於神經網路想到的首要影響,並不代表著該超引數隻影響學習速度或者正確率。
因為不同的超引數的類別不同,因此在調整超引數的時候也應該根據對應超引數的類別進行調整。再調整超引數的過程中有根據機理選擇超引數的方法,有根據訓練集上表現情況選擇超引數的方法,也有根據驗證集上訓練資料選擇超引數的方法。他們之間的關係如圖2所示。
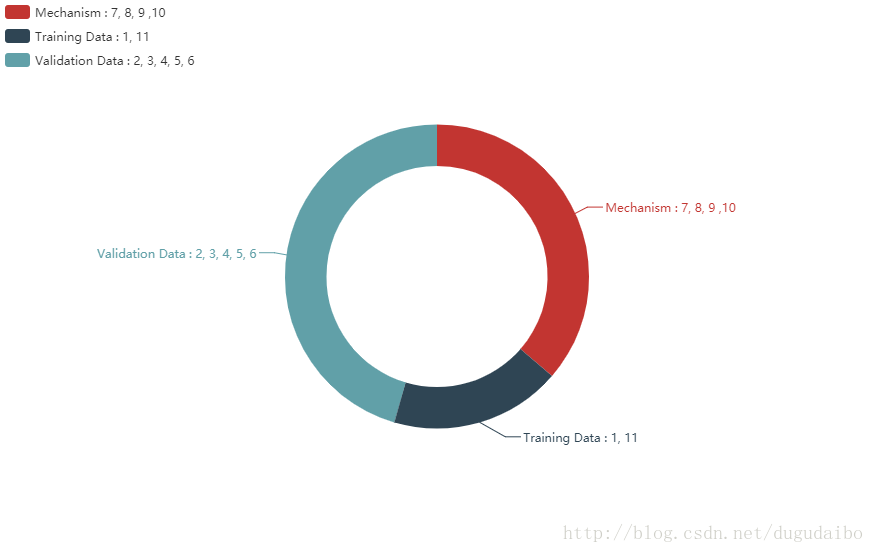
圖2. 不同超引數的選擇方法不同。
如圖2所示,超引數 7,8,9,10 由神經網路的機理進行選擇。在這四個引數中,應該首先對第10個引數神經元的種類進行選擇,根據目前的知識,一種較好的選擇方式是對於神經網路的隱層採用sigmoid神經元,而對於輸出層採用softmax的方法;根據輸出層採用sotmax的方法,因此第8個代價函式採用 log-likelihood 函式(或者輸出層還是正常的sigmoid神經元而代價函式為交叉熵函式),第9個初始化權重採用均值為0方差為 1nin√1nin 的高斯隨機分佈初始化權重;對於輸出層的編碼方式常常採用向量式的編碼方式,基本上不會使用實際的數值或者二進位制的編碼方式。超引數1由訓練資料的代價函式選擇,在上述這兩部分都確定好之後在根據檢驗集資料確定最後的幾個超引數。這只是一個大體的思路,具體每一個引數的確定將在下面具體介紹。
2. 寬泛策略
根據上面的分析我們已經根據機理將神經網路中的神經元的種類、輸出層的模式(即是否採用softmax)、代價函式及輸出層的編碼方式進行了設定。所以在這四個超引數被確定了之後變需要確定其他的超引數了。假設我們是從頭開始訓練一個神經網路的,我們對於其他引數的取值本身沒有任何經驗,所以不可能一上來就訓練一個很複雜的神經網路,這時就要採用寬泛策略。
寬泛策略的核心在於簡化和監控。簡化具體體現在,如簡化我們的問題,如將一個10分類問題轉變為一個2分類問題;簡化網路的結構,如從一個僅包含10個神經元你的隱層開始訓練,逐漸增加網路的層數和神經元的個數;簡化訓練用的資料,在簡化問題中,我們已經減少了80%的資料量,在這裡我們該要精簡檢驗集中資料的數量,因為真正驗證的是網路的效能,所以僅用少量的驗證集資料也是可以的,如僅採用100個驗證集資料。監控具體指的是提高監控的頻率,比如說原來是每5000次訓練返回一次代價函式或者分類正確率,現在每1000次訓練就返回一次。其實可以將“寬泛策略”當作是一種對於網路的簡單初始化和一種監控策略,這樣可以更加快速地實驗其他的超引數,或者甚至接近同步地進行不同引數的組合的評比。
直覺上看,這看起來簡化問題和架構僅僅會降低你的效率。實際上,這樣能夠將進度加快,因為你能夠更快地找到傳達出有意義的訊號的網路。一旦你獲得這些訊號,你可以嚐嚐通過微調超引數獲得快速的效能提升。
3. 學習率的調整
假設我們運行了三個不同學習速率( η=0.025η=0.025、η=0.25η=0.25、η=2.5η=2.5)的 MNIST 網 絡,其他的超引數假設已經設定為進行30回合,minibatch 大小為10,然後 λ=5.0λ=5.0 ,使用50000幅訓練影象,訓練代價的變化情況如圖3
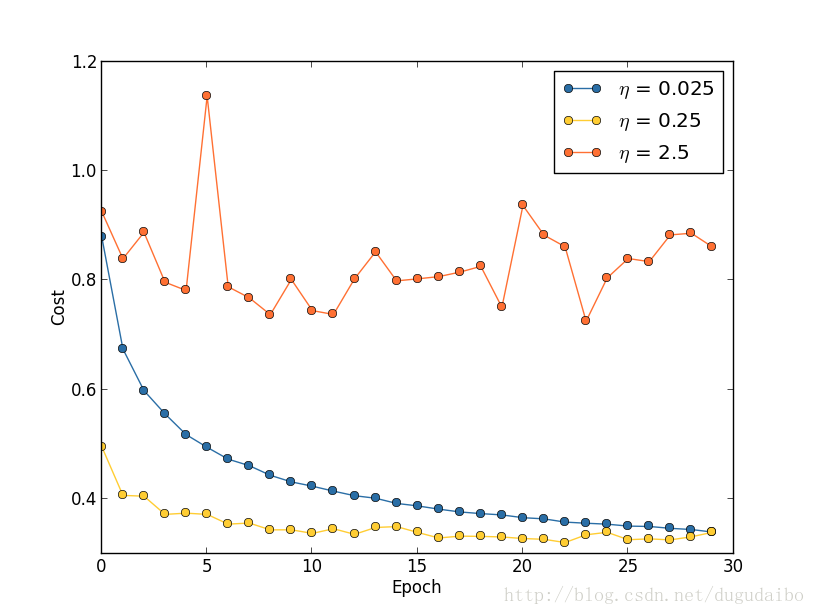
圖3. 不同學習率下代價函式曲線的變化情況
使用 η=0.025η=0.025,代價函式平滑下降到最後的回合;使用 η=0.25η=0.25,代價剛開始下降,在大約20 回合後接近飽和狀態,後面就是微小的震盪和隨機抖動;最終使用 η=2.5η=2.5 代價從始至終都震盪得非常明顯。
因此學習率的調整步驟為:首先,我們選擇在訓練資料上的代價立即開始下降而非震盪或者增加時的作為 ηη 閾值的估計,不需要太過精確,確定量級即可。如果代價在訓練的前面若干回合開始下降,你就可以逐步增加 ηη 的量級,直到你找到一個的值使得在開始若干回合代價就開始震盪或者增加;相反,如果代價函式曲線開始震盪或者增加,那就嘗試減小量級直到你找到代價在開始回合就下降的設定,取閾值的一半就確定了學習速率 。在這裡使用訓練資料的原因是學習速率主要的目的是控制梯度下降的步長,監控訓練代價是最好的檢測步長過大的方法。
4. 迭代次數
提前停止表示在每個回合的最後,我們都要計算驗證集上的分類準確率,當準確率不再提升,就終止它也就確定了迭代次數(或者稱回合數)。另外,提前停止也能夠幫助我們避免過度擬合。
我們需要再明確一下什麼叫做分類準確率不再提升,這樣方可實現提前停止。正如我們已經看到的,分類準確率在整體趨勢下降的時候仍舊會抖動或者震盪。如果我們在準確度剛開始下降的時候就停止,那麼肯定會錯過更好的選擇。一種不錯的解決方案是如果分類準確率在一段時間內不再提升的時候終止。建議在更加深入地理解 網路訓練的方式時,僅僅在初始階段使用 10 回合不提升規則,然後逐步地選擇更久的回合,比如 20 回合不提升就終止,30回合不提升就終止,以此類推。
5. 正則化引數
我建議,開始時代價函式不包含正則項,只是先確定 ηη 的值。使用確定出來的 ηη,用驗證資料來選擇好的 λλ 。嘗試從 λ=1λ=1 開始,然後根據驗證集上的效能按照因子 10 增加或減少其值。一旦我已經找到一個好的量級,你可以改進 λλ 的值。這裡搞定 λλ 後,你就可以返回再重新優化 ηη 。
6. 小批量資料的大小
選擇最好的小批量資料大小也是一種折衷。太小了,你不會用上很好的矩陣庫的快速計算;太大,你是不能夠足夠頻繁地更新權重的。你所需要的是選擇一個折衷的值,可以最大化學習的速度。幸運的是,小批量資料大小的選擇其實是相對獨立的一個超引數(網路整體架構外的引數),所以你不需要優化那些引數來尋找好的小批量資料大小。因此,可以選擇的方式就是使用某些可以接受的值(不需要是最優的)作為其他引數的選擇,然後進行不同小批量資料大小的嘗試,像上面那樣調整 ηη 。畫出驗證準確率的值隨時間(非回合)變化的圖,選擇哪個得到最快效能的提升的小批量資料大小。得到了小批量資料大小,也就可以對其他的超引數進行優化了。
7. 總體的調參過程
首先應該根據機理確定啟用函式的種類,之後確定代價函式種類和權重初始化的方法,以及輸出層的編碼方式;其次根據“寬泛策略”先大致搭建一個簡單的結構,確定神經網路中隱層的數目以及每一個隱層中神經元的個數;然後對於剩下的超引數先隨機給一個可能的值,在代價函式中先不考慮正則項的存在,調整學習率得到一個較為合適的學習率的閾值,取閾值的一半作為調整學習率過程中的初始值 ;之後通過實驗確定minibatch的大小;之後仔細調整學習率,使用確定出來的 ηη,用驗證資料來選擇好的 λλ ,搞定 λλ 後,你就可以返回再重新優化 ηη。而學習回合數可以通過上述這些實驗進行一個整體的觀察再確定。
版權宣告:本文為博主原創文章,未經博主允許不得轉載。 https://blog.csdn.net/dugudaibo/article/details/77366245