
小議WebRTC擁塞控制演算法:GCC介紹
網路擁塞是基於IP協議的資料報交換網路中常見的一種網路傳輸問題,它對網路傳輸的質量有嚴重的影響,網路擁塞是導致網路吞吐降低,網路丟包等的主要原因之一,這些問題使得上層應用無法有效的利用網路頻寬獲得高質量的網路傳輸效果。特別是在通訊領域,網路擁塞導致的丟包,延遲,抖動等問題,嚴重的影響了通訊質量,如果不能很好的解決這些問題,一個通訊產品就無法在現實環境中正常使用。在這方面WebRTC中的網路擁塞控制演算法給我們提供了一個可供參考的實現,本篇文章會盡量詳細的介紹WebRTC中的擁塞控制演算法---GCC的實現方式。
相關閱讀推薦
《聊聊WebRTC閘道器伺服器2:如何選擇PeerConnection方案?》
WebRTC簡介
WebRTC是一個Web端的實時通訊解決方案,它可以做到在不借助外部外掛的情況下,在瀏覽器中實現點對點的實時通訊。WebRTC已經由W3C和IETF標準化,最早推出和支援這項技術的瀏覽器是Chrome, 其他主流瀏覽器也正在陸續支援。Chrome中整合的WebRTC程式碼已全部開源,同時Chrome提供了一套LibWebRTC的程式碼庫,使得這套RTC架構可以移植到其他APP當中,提供實時通訊功能。

GCC演算法概述
本文主要介紹的是WebRTC的擁塞控制演算法,WebRTC的傳輸層是基於UDP協議,在此之上,使用的是標準的RTP/RTCP協議封裝媒體流。RTP/RTCP本身提供很多機制來保證傳輸的可靠性,比如RR/SR, NACK,PLI,FIR, FEC,REMB等,同時WebRTC還擴充套件了RTP/RTCP協議,來提供一些額外的保障,比如Transport-CCFeedback, RTP Transport-wide-cc extension,RTP abs-sendtime extension等,其中一些後文會詳細介紹。
GCC演算法主要分成兩個部分,一個是基於丟包的擁塞控制,一個是基於延遲的擁塞控制。在早期的實現當中,這兩個擁塞控制演算法分別是在傳送端和接收端實現的,接收端的擁塞控制演算法所計算出的估計頻寬,會通過RTCP的remb反饋到傳送端,傳送端綜合兩個控制演算法的結果得到一個最終的傳送位元速率,並以此位元速率傳送資料包。下圖便是展現的該種實現方式:

從圖中可以看到,Loss-Based Controller在傳送端負責基於丟包的擁塞控制,它的輸入比較簡單,只需要根據從接收端反饋的丟包率,就可以做頻寬估算;上圖右側比較複雜,做的是基於延遲的頻寬估計,這也是本文後面主要介紹的部分。在最近的WebRTC實現中,GCC把它的兩種擁塞控制演算法都移到了傳送端來實現,但是兩種演算法本身並沒有改變,只是在傳送端需要計算延遲,因而需要一些額外的feedback資訊,為此WebRTC擴充套件了RTCP協議,其中最主要的是增加了Transport-CC Feedback,該包攜帶了接收端接收到的每個媒體包的到達時間。
基於延遲的擁塞控制比較複雜,WebRTC使用延遲梯度來判斷網路的擁塞程度,延遲梯段的概念後文會詳細介紹;
其演算法分為幾個部分:
- 到達時間濾波器
- 過載檢測器
- 速率控制器
在獲得兩個擁塞控制演算法分別結算到的傳送位元速率之後,GCC最終的傳送位元速率取的是兩種演算法的最小值。下面我們詳細介紹WebRTC的擁塞控制演算法GCC。
(一)基於丟包的頻寬估計
基於丟包的擁塞控制比較簡單,其基本思想是根據丟包的多少來判斷網路的擁塞程度,丟包越多則認為網路越擁塞,那麼我們就要降低傳送速率來緩解網路擁塞;如果沒有丟包,這說明網路狀況很好,這時候就可以提高發送位元速率,向上探測是否有更多的頻寬可用。實現該演算法有兩點:一是獲得接收端的丟包率,一是確定降低位元速率和提升位元速率的閾值。
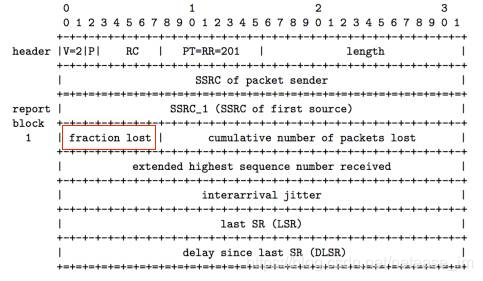
WebRTC通過RTCP協議的Receive Report反饋包來獲取接收端的丟包率。Receive Report包中有一個lost fraction欄位,包含了接收端的丟包率,如下圖所示。
另外,WebRTC通過以下公式來估算髮送位元速率,式中 As(tk) 即為 tk 時刻的頻寬估計值,fl(tk)即為 tk 時刻的丟包率:
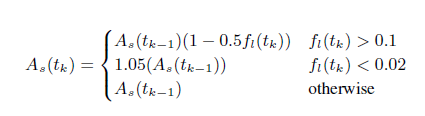
簡單來說,當丟包率大於10%時則認為網路有擁塞,此時根據丟包率降低頻寬,丟包率越高頻寬降的越多;當丟包率小於2%時,則認為網路狀況很好,此時向上提高5%的頻寬以探測是否有更多頻寬可用;2%到10%之間的丟包率,則會保持當前位元速率不變,這樣可以避免一些網路固有的丟包被錯判為網路擁塞而導致降低位元速率,而這部分的丟包則需要通過其他的如NACK或FEC等手段來恢復。
(二)基於延遲梯度的頻寬估計
WebRTC實現的基於延遲梯度的頻寬估計有兩種版本:
- 最早一種是在接受端實現,評估的頻寬結果通過RTCP REMB訊息反饋到傳送端。在此種實現中,為了準確計算延遲梯度,WebRTC添加了一種RTP擴充套件頭部abs-send-time, 用來表示每個RTP包的精確傳送時間,從而避免傳送端延遲給網路傳播延遲的估計帶來誤差。這種模式也是RFC和google的paper中描述的模式。
- 在新近的WebRTC的實現中,所有的頻寬估計都放在了傳送端,也就說傳送端除了做基於丟包的頻寬估計,同時也做基於延遲梯度的頻寬估計。為了能夠在接受端做基於延遲梯度的頻寬估計,WebRTC擴充套件了RTP/RTCP協議,其一是增加了RTP擴充套件頭部,添加了一個session級別的sequence number, 目的是基於一個session做反饋資訊的統計,而不緊緊是一條音訊流或視訊流;其二是增加了一個RTCP反饋資訊transport-cc-feedback,該訊息負責反饋接受端收到的所有媒體包的到達時間。接收端根據包間的接受延遲和傳送間隔可以計算出延遲梯度,從而估計頻寬。
關於如何根據延遲梯度推斷當前網路狀況, 後面會分幾點詳細展開講, 總體來說分為以下幾個步驟:
- 到達時間濾波器
- 過載檢測器
- 速率控制器
其過程就是,到達時間濾波器根據包間的到達時延和傳送間隔,計算出延遲變化,這裡會用到卡爾曼濾波對延遲變化做平滑以消除網路噪音帶來的誤差;延遲變化會作為過載檢測器的輸入,由過載檢測器判斷當前網路的狀態,有三種網路狀態返回overuse/underuse/normal,檢測的依據是比較延遲變化和一個閾值,其中該閾值非常關鍵且是動態調整的。最後根據網路狀態的變化,速率控制器根據一個頻寬估計公式計算頻寬估計值。
(三)到達時間濾波器
前面多次提到WebRTC使用延遲梯度來判斷網路擁塞狀況,那什麼是延遲梯度,為什麼延遲梯度可以作為判斷網路擁塞的依據,我們在這裡詳細介紹,首先來看以下,延遲梯度是怎樣計算出來的:
1. 延遲梯度的計算

如上圖所示,用兩個資料包的到達時間間隔減去他們的傳送時間間隔,就可以得到一個延遲的變化,這裡我們稱這個延遲的變化為單向延遲梯度(one way delay gradient),其公式可記為:
![]()
那麼為什麼延遲梯度可以用來判斷網路擁塞的呢,如下面兩圖所示:
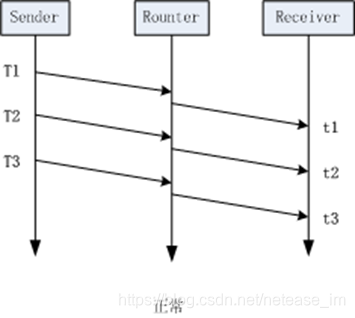
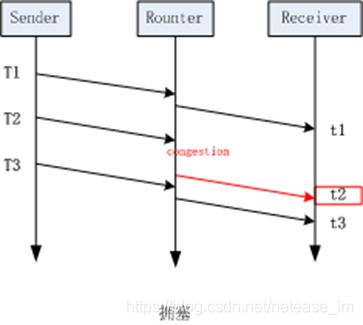
左邊這幅圖的場景是理想狀況下的網路傳輸,沒有任何擁塞,按我們上面提到的公式(2)來計算,這種場景下,所計算到的延遲梯度應該為0。而右邊這幅圖的場景則是傳送擁塞時的狀況,當包在t2時刻到達時,該報在網路中經歷過一次因擁塞導致的排隊,這導致他的到達時間比原本要完,此時計算出的延遲梯度就為一個較大的值,通過這個值,我們就能判斷當前網路正處在擁塞狀態。
在WebRTC的具體實現中,還有一些細節來保證延遲梯度計算的準確性,總結如下:
- 由於延遲梯度的測量精度很小,為了避免網路噪音帶來的誤差,利用了卡爾曼濾波來平滑延遲梯度的測量結果。
- WebRTC的實現中,並不是單純的測量單個數據包彼此之間的延遲梯度,而是將資料包按傳送時間間隔和到達時間間隔分組,計算組間的整體延遲梯度。分組規則是:
- 傳送時間間隔小於5ms的資料包被歸為一組,這是由於WebRTC的傳送端實現了一個平滑傳送模組,該模組的傳送間隔是5ms傳送一批資料包。
- 到達時間間隔小於5ms的資料包被歸為一組,這是由於在wifi網路下,某些wifi裝置的轉發模式是,在某個固定時間片內才有機會轉發資料包,這個時間片的間隔可能長達100ms,造成的結果是100ms的資料包堆積,並在傳送時形成burst,這個busrt內的所有資料包就會被視為一組。
- 為了計算延遲梯度,除了接收端要反饋每個媒體包的接受狀態,同時傳送端也要記錄每個媒體包的傳送狀態,記錄其傳送的時間值。在這個情況下abs-send-time擴充套件不再需要。
2. transport-cc-feedback訊息
- 該訊息是對RTCP的一個擴充套件,專門用於在GCC中反饋資料包的接受情況。這裡有兩點需要注意:
- 該訊息的傳送速率如何確定,按RFC[2]中的說明,可以是收到每個frame傳送一次,另外也指出可以是一個RTT的時間傳送一次,實際WebRTC的實現中大約估計了一個傳送頻寬的5%這樣一個傳送速率。
- 如果這個資料包丟失怎麼辦,RFC[2]和WebRTC實現中都是直接忽略,這裡涉及的問題是,忽略該包對計算延遲梯度影響不大,只是相當於資料包的分組跨度更大了,丟失的包對計算沒有太大影響,但另一個問題是,傳送端需要計算接受端的接受速率,當feedback丟失時,會認為相應的資料包都丟失了,這會影響接受速率的計算,這個值在後續計算估計頻寬中會用到,從而導致一定誤差。
具體訊息格式如下:

如上圖所示,紅框之前的欄位是RTCP包的通用欄位,紅框中的欄位為transport-cc的具體內容,其中前四個欄位分別表示:
- base sequence number:當前包攜帶的媒體包的接受資訊是從哪個包開始的
- packet status count:當前包攜帶了幾個媒體包的接受資訊
- reference time:一個基準時間,計算該包中每個媒體包的到達時間都要基於這個基準時間計算
- fb pkt. count:第幾個transport-cc包
在此之後,是兩類資訊:多個packet chunk欄位和多個recv delta欄位。其中pcaket chunk具體含義如下:
如下兩圖所示, 表示媒體包到達狀態的結構有兩種編碼方式, 其中 T 表示chunk type;0表示RunLength Chunk, 1表示Status Vector Chunk.
1)Run LengthChunk

這種表示方式是用於,當我們連續收到多個數據包,他們都有相同的到達狀態,就可以用這種編碼方式。其中S表示的是到達狀態,Run Length表示有多少個連續的包屬於這一到達狀態。
到達狀態有三種:
00 Packet not received
01 Packet received, small delta (所謂small detal是指能用一個位元組表示的數值)
10 Packet received, large ornegative delta (large即是能用兩個位元組表示的數值)
2) Status Vector Chunk

這種表示方式用於每個資料包都需要自己的狀態表示碼,當然還是上面提到的那三種狀態。但是這裡的S就不是上面的意思,這裡的S指的是symbol list的編碼方式,s = 0時,表示symbollist的每一個bit能表示一個數據包的到達狀態,s = 1時表示每兩個bit表示一個數據包的狀態。
s = 0 時
0 Packet not received
1 Packet received , small detal
s = 1 時
同 Run Length Chunk
最後,對於每一個狀態為Packet received 的資料包的延遲依次填入|recv delta|欄位,到達狀態為1的,recv delta佔用一個位元組,到達狀態為2的,recv delta佔用兩個位元組可以看出以上編碼的目的是為了儘量減少該資料包的大小,因為每個媒體包都需要反饋他的接受狀態。
(四)過載檢測器
到達時間濾波器計算出每組資料包的延遲梯度之後,就要據此判斷當前的網路擁塞狀態,通過和某個閾值的比較,高過某個閾值就認為時網路擁塞,低於某個閾值就認為網路狀態良好,因此如何確定閾值就至關重要。這就是過載檢測器的主要工作,它主要有兩部分,一部分是確定閾值的大小,另一部分就是依據延遲梯度和閾值的判斷,估計出當前的網路狀態,一共有三種網路狀態: overuse underuse normal,我們先看網路狀態的判斷。
1. 網路狀態判斷
判斷依據入下圖所示:
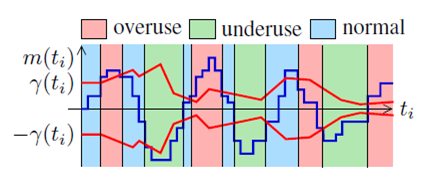
其中表示的是計算出的延遲梯,
表示的是一個判斷閾值,這個閾值是自適應的, 後面還會介紹他是怎麼動態調整的,這裡先只看如何根據這兩個值判斷當前網路狀態。
從上圖可以看出,這裡的判斷方法是:

這樣計算的依據是,網路發生擁塞時,資料包會在中間網路裝置中排隊等待轉發,這會造成延遲梯度的增長,當網路流量回落時,網路裝置快速消耗(轉發)其傳送佇列中的資料包,而後續的包排隊時間更短,這時延遲梯度減小或為負值。
這裡了需要說明的是:
- 在實際WebRTC的實現中,雖然每個資料包組(前面提到了如何分組)的到達都會觸發這個探測過程,但是使用的m(ti)這個值並不是直接使用每組資料到來時的計算值,而是將這個值放大了60倍。這麼做的目的可能是m(ti)這個值通常情況下很小,理想網路下基本為0,放大該值可以使該演算法不會應為太靈敏而波動太大。
- 在判斷是否overuse時,不會一旦超過閾值就改變當前狀態,而是要滿足延遲梯度大於閾值至少持續100ms,才會將當前網路狀態判斷為overuse。
2. 自適應閾值
上節提到的閾值值,它是判斷當前網路狀況的依據,所以如何確定它的值也就非常重要了。雖然理想狀況下,網路的延遲梯度是0,但是實際的網路中,不同轉發路徑其延遲梯度還是有波動的,波動的大小也是不一樣的,這就導致如果設定固定的
太大可能無法探測到擁塞,太小又太敏感,導致速率了變化很大。同時,另外一個問題是,實驗中顯示固定的值會導致在和TCP連結的競爭中,自己被餓死的現象(TCP是基於丟包的擁塞控制),因此WebRTC使用了一種自適應的閾值調節演算法,具體如下:
(1) 自適應演算法
![]()
上面的公式就是GCC提出的閾值自適應演算法,其中:
![]() ,每組資料包會觸發一次探測,同時更新一次閾值,這裡
,每組資料包會觸發一次探測,同時更新一次閾值,這裡 的意義就是距上次更新閾值時的時間間隔。
![]() 是一個變化率,或者叫增長率,當然也有可能是負增長,增長的基值是:當前的延遲梯度和上一個閾值的差值---
是一個變化率,或者叫增長率,當然也有可能是負增長,增長的基值是:當前的延遲梯度和上一個閾值的差值---
![]() 。其具體的取值如下:
。其具體的取值如下:
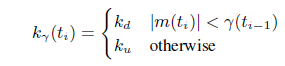
從這個式子中可以看出,當延遲梯度減小時,閾值會以一個更慢的速率減小; 延遲梯度增加時,閾值也會以一個更慢的速度增加;不過相對而言,閾值的減小速度要小於增加速度。
(五)速率控制器
速率控制器主要實現了一個狀態機的變遷,並根據當前狀態來計算當前的可用位元速率,狀態機如下圖所示:

速率控制器根據過載探測器輸出的訊號(overuse underusenormal)驅動速率控制狀態機, 從而估算出當前的網路速率。從上圖可以看出,當網路擁塞時,會收到overuse訊號,狀態機進入“decrease”狀態,傳送速率降低;當網路中排隊的資料包被快速釋放時,會受到underuse訊號,狀態機進入“hold”狀態。網路平穩時,收到normal訊號,狀態機進入“increase”狀態,開始探測是否可以增加發送速率。
在Google的paper[3]中,計算頻寬的公式如下:
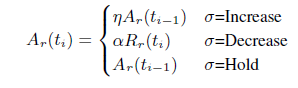
其中 = 1.05,
=0.85。從該式中可以看到,當需要Increase時,以前一次的估算位元速率乘以1.05作為當前位元速率;當需要Decrease時,以當前估算的接受端位元速率(Rr(ti))乘以0.85作為當前位元速率;Hold狀態不改變位元速率。
最後,將基於丟包的位元速率估計值和基於延遲的位元速率估計值作比較,其中最小的位元速率估價值將作為最終的傳送位元速率。
以上便是WebRTC中的擁塞控制演算法的主要內容,其演算法也一直還在演進當中,每個版本都有會有一些改進加入。其他還有一些主題這裡沒有覆蓋到,比如平滑傳送,可以避免突發流量; padding包等用來探測頻寬的策略。應該說WebRTC的這套機制能覆蓋大部分的網路場景,但是從我們測試來看有一些特殊場景,比如抖動或者丟包比較高的情況下,其頻寬利用率還是不夠理想,但總體來說效果還是很不錯的。
另外,想要獲取更多產品乾貨、技術乾貨,記得關注網易雲信部落格。